If you’re a recent adopter of Apache Kafka, you’re undoubtedly trying to determine how to handle all the data streaming through your system. The Events Pipeline team at New Relic processes a huge amount of “event data” on an hourly basis, so we’re thinking about Kafka monitoring and this question a lot. Unless you’re processing only a small amount of data, you need to distribute your data onto separate partitions.
In part one of this series—Using Apache Kafka for Real-Time Event Processing at New Relic—we explained how we built some of the underlying architecture of our event processing streams using Kafka. In this post, we explain how the partitioning strategy for your producers depends on what your consumers will do with the data.
What are Kafka topics and partitions?
Apache Kafka uses topics and partitions for efficient data processing. Topics are data categories to which records are published; consumers subscribe to these topics. For scalability and performance, topics are divided into partitions, allowing parallel data processing and fault tolerance. Partitions enable multiple consumers to read concurrently and are replicated across nodes for resilience against failures. Let's dive into these further.
What are Kafka topics and partitions?
A partition in Kafka is the storage unit that allows for a topic log to be separated into multiple logs and distributed over the Kafka cluster.
Partitions allow Kafka clusters to scale smoothly.
Why partition your data in Kafka?
If you have so much load that you need more than a single instance of your application, you need to partition your data. How you partition serves as your load balancing for the downstream application. The producer clients decide which topic partition that the data ends up in, but it’s what the consumer applications do with that data that drives the decision logic.
How does Kafka partitioning improve performance?
Kafka partitioning allows for parallel data processing, enabling multiple consumers to work on different partitions simultaneously. This helps achieve higher throughput and ensures the processing load is distributed across the Kafka cluster.
What factors should you consider when determining the number of partitions?
Choose the number of partitions based on factors like expected data volume, the number of consumers, and the desired level of parallelism. It's essential to strike a balance to avoid over-partitioning or under-partitioning, which can impact performance.
Can the number of partitions be changed after creating a topic?
Yes, it's possible to change the number of partitions for a topic. However, doing so requires careful consideration as it may affect data distribution and consumer behavior. We recommend to plan a partitioning strategy during the initial topic creation.
Can a consumer read from multiple partitions simultaneously?
Yes, consumers can read from multiple partitions concurrently. Kafka consumers are designed to handle parallel processing, allowing them to consume messages from different partitions at the same time, thus increasing overall throughput.
Kafka topics
A Kafka topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
The relationship between Kafka topics and partitions
To enhance scalability and performance, each topic is further divided into partitions. These partitions allow for the distribution and parallel processing of data across multiple brokers within a Kafka cluster. Each partition is an ordered, immutable sequence of records, where order is maintained only within the partition, not across the entire topic. This partitioning mechanism enables Kafka to handle a high volume of data efficiently, as multiple producers can write to different partitions simultaneously, and multiple consumers can read from different partitions in parallel. The relationship between topics and partitions is fundamental to Kafka's ability to provide high throughput and fault tolerance in data streaming applications.
Kafka topic partitioning strategy: Which one should you choose?
In Kafka, partitioning is a versatile and crucial feature, with several strategies available to optimize data distribution and processing efficiency. These strategies determine how records are allocated across different partitions within a topic. Each approach caters to specific use cases and performance requirements, influencing the balance between load distribution and ordering guarantees. We'll now dive into these various partitioning strategies, exploring how they can effectively enhance Kafka's performance and reliability in diverse scenarios.
Partitioning on an attribute
You may need to partition on an attribute of the data if:
- The consumers of the topic need to aggregate by some attribute of the data
- The consumers need some sort of ordering guarantee
- Another resource is a bottleneck and you need to shard data
- You want to concentrate data for efficiency of storage and/or indexing
In part one, we used the following diagram to illustrate a simplification of a system we run for processing ongoing queries on event data:
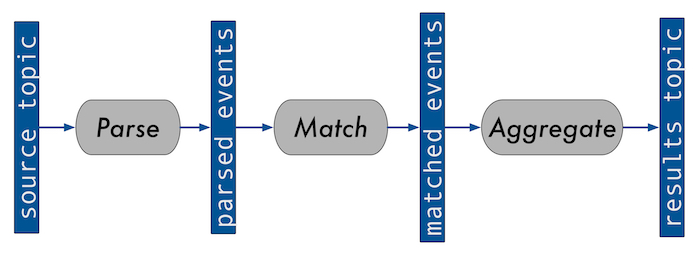
Random partitioning of Kafka data
We use this system on the input topic for our most CPU-intensive application—the match service. This means that all instances of the match service must know about all registered queries to be able to match any event. While the event volume is large, the number of registered queries is relatively small, and thus a single application instance can handle holding all of them in memory, for now at least.
Kafka random partitioning diagram
The following diagram uses colored squares to represent events that match to the same query. It shows messages randomly allocated to partitions:
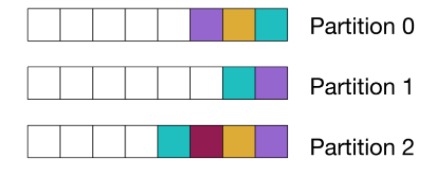
When to use random partitioning
Random partitioning results in the evenest spread of load for consumers, and thus makes scaling the consumers easier. It is particularly suited for stateless or “embarrassingly parallel” services.
This is effectively what you get when using the default partitioner while not manually specifying a partition or a message key. To get an efficiency boost, the default partitioner in Kafka from version 2.4 onwards uses a “sticky” algorithm, which groups all messages to the same random partition for a batch.
Partition by aggregate
On the topic consumed by the service that does the query aggregation, however, we must partition according to the query identifier since we need all of the events that we’re aggregating to end up at the same place.
Kafka aggregate partitioning diagram
This diagram shows that events matching to the same query are all co-located on the same partition. The colors represent which query each event matches to:
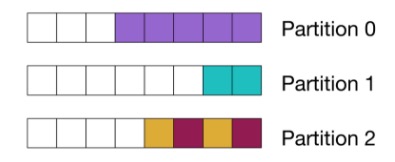
After releasing the original version of the service, we discovered that the top 1.5% of queries accounted for approximately 90% of the events processed for aggregation. As you can imagine, this resulted in some pretty bad hot spots on the unlucky partitions.
When to use aggregate parsing
In the following example, you can see that we broke up the aggregation service into two pieces. Now we can randomly partition on the first stage, where we partially aggregate the data and then partition by the query ID to aggregate the final results per window. This approach allows us to greatly condense the larger streams at the first aggregation stage, so they are manageable to load balance at the second stage.

Of course, this approach comes with a resource-cost trade-off. Writing an extra hop to Kafka and having to split the service into two means that we spend more on network and service costs.
In this example, co-locating all the data for a query on a single client also sets us up to be able to make better ordering guarantees.
Ordering guarantee
We partition our final results by the query identifier, as the clients that consume from the results topic expect the windows to be provided in order:
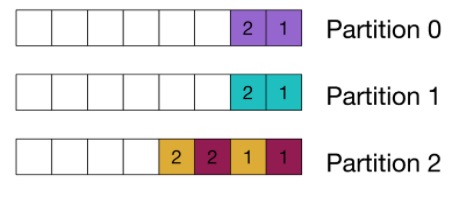
Planning for resource bottlenecks and storage efficiency
When choosing a partitioning strategy, it’s important to plan for resource bottlenecks and storage efficiency.
(Note that the examples in this section reference other services that are not a part of the streaming query system I’ve been discussing.)
Resource bottleneck
We have another service that has a dependency on some databases that have been split into shards. We partition its topic according to how the shards are split in the databases. This approach produces a result similar to the diagram in our partition by aggregate example. Each consumer will be dependent only on the database shard it is linked with. Thus, issues with other database shards will not affect the instance or its ability to keep consuming from its partition. Also, if the application needs to keep state in memory related to the database, it will be a smaller share. Of course, this method of partitioning data is also prone to hotspots.
Storage efficiency
The source topic in our query processing system shares a topic with the system that permanently stores the event data. It reads all the same data using a separate consumer group. The data on this topic is partitioned by which customer account the data belongs to. For efficiency of storage and access, we concentrate an account’s data into as few nodes as possible.
While many accounts are small enough to fit on a single node, some accounts must be spread across multiple nodes. If an account becomes too large, we have custom logic to spread it across nodes, and, when needed, we can shrink the node count back down.
Consumer partition assignment
Whenever a consumer enters or leaves a consumer group, the brokers rebalance the partitions across consumers, meaning Kafka handles load balancing with respect to the number of partitions per application instance for you. This is great—it’s a major feature of Kafka. We use consumer groups on nearly all our services.
By default, when a rebalance happens, all consumers drop their partitions and are reassigned new ones (which is called the “eager” protocol). If you have an application that has a state associated with the consumed data, like our aggregator service, for example, you need to drop that state and start fresh with data from the new partition.
StickyAssignor
To reduce this partition shuffling on stateful services, you can use the StickyAssignor. This assignor makes some attempt to keep partition numbers assigned to the same instance, as long as they remain in the group, while still evenly distributing the partitions across members.
Because partitions are always revoked at the start of a rebalance, the consumer client code must track whether it has kept/lost/gained partitions or if partition moves are important to the logic of the application. This is the approach we use for our aggregator service.
CooperativeSitckyAssignor
I want to highlight a few other options. From Kafka release 2.4 and later, you can use the CooperativeStickyAssignor. Rather than always revoking all partitions at the start of a rebalance, the consumer listener only gets the difference in partitions revoked, as assigned over the course of the rebalance.
The rebalances as a whole do take longer, and in our application, we need to optimize for shortening the time of rebalances when a partition does move. That's why we stayed with using the “eager” protocol under the StickyPartitioner for our aggregator service. However, starting with Kafka release 2.5, we have the ability to keep consuming from partitions during a cooperative rebalance, so it might be worth revisiting.
Static membership
Additionally, you might be able to take advantage of static membership, which can avoid triggering a rebalance altogether, if clients consistently ID themselves as the same member. This approach works even if the underlying container restarts, for example. (Both brokers and clients must be on Kafka release 2.3 or later.)
Instead of using a consumer group, you can directly assign partitions through the consumer client, which does not trigger rebalances. Of course, in that case, you must balance the partitions yourself and also make sure that all partitions are consumed. We do this in situations where we’re using Kafka to snapshot state. We keep snapshot messages manually associated with the partitions of the input topic that our service reads from.
Kafka topic partitioning best practices
Following these best practices ensures that your Kafka topic partitioning strategy is well-designed, scalable, and aligned with your specific use case requirements. Regular monitoring and occasional adjustments will help maintain optimal performance as your system evolves.
Understand your data access patterns:
- Analyze how your data is produced and consumed.
- Consider the read-and-write patterns to design a partitioning strategy that aligns with your specific use case.
Choose an appropriate number of partitions:
- Avoid over-partitioning or under-partitioning.
- The number of partitions should match the desired level of parallelism and the expected workload.
- Consider the number of consumers, data volume, and the capacity of your Kafka cluster.
Use key-based partitioning when necessary:
- For scenarios where ordering or grouping of related messages is crucial, leverage key-based partitioning.
- Ensure that messages with the same key are consistently assigned to the same partition for strict ordering.
Consider data skew and load balancing:
- Be aware of potential data skew, where certain partitions receive more data than others.
- Use key-based partitioning or adjust partitioning logic to distribute the load evenly across partitions.
Plan for scalability:
- Design your partitioning strategy with scalability in mind.
- Ensure that adding more consumers or brokers can be achieved without significantly restructuring partitions.
Set an appropriate replication factor:
- Configure replication to ensure fault tolerance.
- Set a replication factor that suits your level of fault tolerance requirements.
- Consider the balance between replication and storage overhead.
Avoid frequent partition changes:
- Changing the number of partitions for a topic can be disruptive.
- Plan partitioning strategies during the initial topic creation and avoid frequent adjustments.
Monitor and tune as needed:
- Regularly monitor the performance of your Kafka cluster.
- Adjust partitioning strategies based on changes in data patterns, workloads, or cluster resources.
Choosing the best Kafka topic partitioning strategy
Your partitioning strategies will depend on the shape of your data and what type of processing your applications do. As you scale, you might need to adapt your strategies to handle new volume and shape of data. Consider what the resource bottlenecks are in your architecture, and spread load accordingly across your data pipelines. It might be CPU, database traffic, or disk space, but the principle is the same. Be efficient with your most limited/expensive resources.
To learn more tips for working with Kafka, see 20 Best Practices for Working with Kafka at Scale.
Get started with New Relic.
New Relic is an observability platform that helps you build better software. You can bring in data from any digital source so that you can fully understand how to improve your system.
Interested in how working with New Relic is like? See how we worked with ZenHub to drive in success.

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (support.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


