Se você é um usuário recente do Apache Kafka, com certeza está tentando determinar como lidar com todo o fluxo de dados através do seu sistema. A equipe de eventos do Pipeline da New Relic processa uma grande quantidade de “dados de eventos” a todo momento, então estamos pensando muito no monitoramento do Kafka e nesta questão. Desde que você esteja processando apenas uma pequena quantidade de dados, você precisa distribuir os seus dados em partições separadas.
Na primeira parte desta série — Usando o Apache Kafka para o processamento de eventos em tempo real na New Relic — explicamos como desenvolvemos algumas das arquiteturas subjacentes de nossos fluxos de processamento de eventos usando o Kafka. Neste blogpost, explicamos como a estratégia de particionamento para os seus produtores depende do que os seus consumidores farão com os dados.

O que são tópicos e partições do Kafka?
O Apache Kafka usa tópicos e partições para um processamento eficiente de dados. Os tópicos são categorias de dados nas quais os registros são publicados; os consumidores assinam esses tópicos. Para escalabilidade e desempenho, os tópicos são divididos em partições, permitindo o processamento paralelo de dados, e tolerância a falhas. As partições permitem que vários consumidores leiam simultaneamente, e sejam replicadas entre nós para resiliência contra falhas. Vamos nos aprondundar nisso.
O que são tópicos e partições do Kafka?
Uma partição no Kafka é a unidade de armazenamento que permite que um log de tópico seja separado em vários logs e distribuído pelo cluster Kafka.
As partições permitem que os clusters Kafka sejam dimensionados sem problemas.
O que são tópicos e partições do Kafka?
Se você tiver tanto volume, que precise de mais de uma única instância da sua aplicação, será necessário particionar os seus dados. A forma como você particiona serve como balanceamento de carga para a aplicação downstream. Os clientes produtores decidem em qual partição de tópico os dados vão parar, mas é o que as aplicações do consumidor fazem com esses dados que orienta a lógica de decisão.
Como o particionamento do Kafka melhora o desempenho?
O particionamento do Kafka permite o processamento paralelo de dados, permitindo que vários consumidores trabalhem em diferentes partições simultaneamente. Isso ajuda a obter um maior taxas de transferência, e garante que o volume de processamento seja distribuído pelo conjunto Kafka.
Quais fatores você deve considerar ao determinar o número de partições?
Escolha o número de partições com base em fatores como o volume de dados esperado, o número de consumidores, e o nível desejado de paralelismo. É essencial encontrar um equilíbrio para evitar particionamento excessivo, ou insuficiente, o que pode afetar o desempenho.
O número de partições pode ser alterado após a criação de um tópico?
Sim, é possível alterar o número de partições de um tópico. No entanto, fazer isso requer uma consideração cuidadosa, pois pode afetar a distribuição de dados, e o comportamento do consumidor. Recomendamos planejar uma estratégia de particionamento durante a criação inicial do tópico.
Um consumidor pode ler várias partições simultaneamente?
Sim, os consumidores podem ler várias partições simultaneamente. Os consumidores Kafka são projetados para lidar com o processamento paralelo, permitindo que consumam mensagens de diferentes partições ao mesmo tempo, aumentando, assim, o taxas de transferência geral.
Tópicos do Kafka
Um tópico do Kafka é uma categoria ou nome de feed no qual os registros são publicados. Os tópicos no Kafka são sempre multi-assinantes; isto é, um tópico pode ter zero, um, ou muitos consumidores que assinam os dados gravados nele.
A relação entre tópicos e partições do Kafka
Para melhorar a escalabilidade e o desempenho, cada tópico é dividido em partições. Essas partições permitem a distribuição e o processamento paralelo de dados entre vários corretores dentro de um conjunto Kafka. Cada partição é uma sequência ordenada e imutável de registros, onde a ordem é mantida apenas dentro da partição, e não em todo o tópico. Este mecanismo de particionamento permite que o Kafka lide com um grande volume de dados de forma eficiente, já que vários produtores podem gravar em diferentes partições simultaneamente, e vários consumidores podem ler em diferentes partições em paralelo. A relação entre tópicos e partições é indispensável para a capacidade do Kafka de fornecer alto taxas de transferênciao e tolerância a falhas em aplicações de streaming de dados.
Estratégia de particionamento de tópicos do Kafka: qual você deve escolher?
No Kafka, o particionamento é um recurso versátil e essencial, com diversas estratégias disponíveis para otimizar a distribuição de dados e a eficiência do processamento. Essas estratégias determinam como os registros são alocados em diferentes partições dentro de um tópico. Cada abordagem atende a casos de uso e requisitos de desempenho específicos, influenciando o equilíbrio entre distribuição de carga e garantias de pedido. Agora vamos nos aprofundar nessas diversas estratégias de particionamento, explorando como elas podem efetivamente melhorar o desempenho e a confiabilidade do Kafka em diversos cenários.
Particionando em um atributo
Você pode precisar particionar um atributo dos dados se:
- Os consumidores do tópico precisam agregar por algum atributo dos dados
- Os consumidores precisam de algum tipo de garantia de pedido
- Outro recurso é um gargalo e você precisa fragmentar os dados
- Você deseja concentrar dados para a eficiência de armazenamento e/ou indexação
Na primeira parte, usamos o diagrama a seguir para ilustrar a simplificação de um sistema que executamos para processar consultas contínuas em dados de eventos:
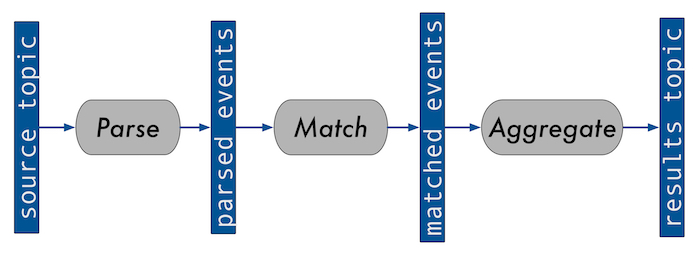
Particionamento aleatório de dados do Kafka
Usamos este sistema no tópico de entrada para a nossa aplicação que utiliza mais CPU—o serviço de correspondência. Isso significa que todas as instâncias do serviço de correspondência devem saber sobre todas as consultas registradas para poder corresponder a qualquer evento. Por mais que o volume de eventos seja grande, o número de consultas registradas é relativamente baixo e, portanto, uma única instância da aplicação pode manter todas elas na memória, pelo menos por enquanto.
Diagrama de particionamento aleatório do Kafka
O diagrama a seguir usa quadrados coloridos para representar eventos que correspondem à mesma consulta. Ele mostra mensagens alocadas aleatoriamente em partições:
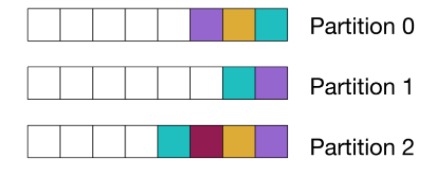
Quando usar o particionamento aleatório
O particionamento aleatório resulta na distribuição mais uniforme da carga para os consumidores e, portanto, facilita o escalonamento dos consumidores. É adequado para serviços sem estado, ou paralelos.
Isso é o que você realmente consegue ao usar o particionador padrão, sem especificar manualmente uma partição, ou uma chave de mensagem. Para obter um aumento de eficiência, o particionador padrão no Kafka, a partir da versão 2.4, usa um algoritmo “fixo”, que agrupa todas as mensagens na mesma partição aleatória para um lote.
Partição por agregado
No tópico consumido pelo serviço que faz a agregação da consulta, porém, devemos particionar de acordo com o identificador da consulta, pois precisamos que todos os eventos que estamos agregando acabem no mesmo local.
Diagrama de particionamento agregado do Kafka
Este diagrama mostra que os eventos correspondentes à mesma consulta estão todos localizados na mesma partição. As cores representam a qual consulta cada evento corresponde:
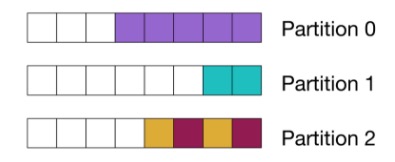
Depois de lançar a versão original do serviço, descobrimos que 1,5% das principais consultas representavam aproximadamente 90% dos eventos processados para agregação. Como você pode imaginar, isso resultou em alguns pontos de acesso péssimos nas partições infelizes.
Quando usar análise agregada
No exemplo a seguir, você pode ver que dividimos o serviço de agregação em duas partes. Agora podemos particionar aleatoriamente no primeiro estágio, onde agregamos parcialmente os dados, e depois particionamos pelo ID da consulta para agregar os resultados finais por janela. Essa abordagem nos permite condensar bastante os fluxos maiores no primeiro estágio de agregação, para que eles sejam gerenciáveis para balanceamento de carga no segundo estágio.

É claro que essa abordagem acarreta uma compensação em termos de custo de recursos. Colocar mais um passo para o Kafka, e ter que dividir o serviço em dois, significa que gastamos mais em custos de rede e de serviço.Neste exemplo, co-localizar todos os dados para consulta em um único cliente também nos permite oferecer melhores garantias de pedido.
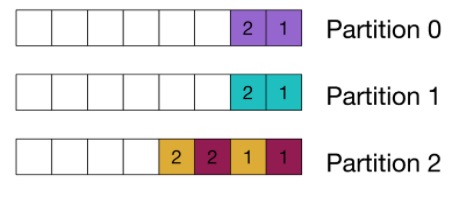
Garantia de pedido
Particionamos nossos resultados finais pelo identificador da consulta, pois os clientes que consomem do tópico de resultados esperam que as janelas sejam fornecidas na ordem:
Planejando gargalos de recursos e eficiência de armazenamento
Ao escolher uma estratégia de particionamento, é importante planejar gargalos de recursos e eficiência de armazenamento.(Observe que os exemplos nesta seção fazem referência a outros serviços que não fazem parte do sistema de consulta de streaming que estou discutindo.)
Gargalo de recursos
Temos outro serviço que dependência de alguns bancos de dados, que foram divididos em fragmentos. Particionamos o seu tópico de acordo com como os fragmentos são divididos nos bancos de dados. Essa abordagem produz um resultado semelhante ao diagrama em nosso exemplo de partição por agregado. Cada consumidor dependerá apenas do fragmento do banco de dados ao qual está vinculado. Assim, problemas com outros fragmentos do banco de dados não afetarão a instância, ou a sua capacidade de continuar consumindo da partição. Além disso, se a aplicação precisar manter o estado na memória relacionado ao banco de dados, será um compartilhamento menor. Obviamente, esse método de particionamento de dados também está sujeito a pontos de acesso.
Eficiência de armazenamento
O tópico de origem em nosso sistema de processamento de consultas compartilha um tópico com o sistema que armazena permanentemente os dados do evento. Ele lê os mesmos dados, usando um grupo de consumidores separado. Os dados neste tópico são particionados de acordo com a conta do cliente a qual os dados pertencem. Para eficiência de armazenamento e acesso, concentramos os dados de uma conta no menor número possível de nós.
Apesar de que muitas contas sejam pequenas o suficiente para caber em um único nó, devem ser distribuidas por vários nós. Se uma conta se tornar muito grande, temos uma lógica personalizada para distribuí-la pelos nós e, quando necessário, podemos reduzir a contagem de nós.
Atribuição de partição de consumidor
Sempre que um consumidor entra, ou sai, de um grupo de consumidores, os corretores reequilibram as partições entre eles, o que significa que o Kafka lida com o balanceamento de carga em relação ao número de partições por instância da aplicação para você. Isso é ótimo—é um recurso importante do Kafka. Usamos grupos de consumidores em quase todos os nossos serviços.
Por padrão, quando ocorre um reequilíbrio, todos os consumidores descartam as suas partições, e são reatribuídas novas partições (o que é chamado de protocolo “ansioso”). Se você tiver uma aplicação que possua um estado associado aos dados consumidos, como nosso serviço agregador, por exemplo, será necessário eliminar esse estado, e começar do zero com os dados da nova partição.
StickyAssignor
Para reduzir esse embaralhamento de partição em serviços com estado, você pode usar o StickyAssignor. Este indicativo tenta manter os números de partição atribuídos à mesma instância, desde que permaneçam no grupo, enquanto ainda distribui uniformemente as partições entre os membros.
Como as partições são sempre revogadas no início de um rebalanceamento, o código do cliente consumidor deve rastrear se manteve/perdeu/ganhou partições, ou se as movimentações de partição são importantes para a lógica da aplicação. Esta é a abordagem que usamos para o nosso serviço agregador.
CooperativeSitckyAssignor
Quero destacar algumas outras opções. A partir da versão 2.4 do Kafka você pode usar o CooperativeStickyAssignor. Ao invés de sempre revogar todas as partições no início de um rebalanceamento, o ouvinte do consumidor obtém apenas a diferença nas partições revogadas, conforme atribuídas acima do curso do reequilíbrio.
Os rebalanceamentos como um todo demoram mais e, em nossa aplicação, precisamos otimizar para reduzir o tempo de rebalanceamento quando uma partição se move. É por isso que continuamos usando o protocolo “ansioso” do StickyPartitioner para o nosso serviço agregador. No entanto, a partir da versão 2.5 do Kafka, temos a capacidade de continuar consumindo partições durante um rebalanceamento cooperativo, então pode valer a pena revisitar.
Associação estática
Além disso, você pode aproveitar as vantagens da associação estática, que pode evitar o acionamento de um reequilíbrio total, se os clientes se identificarem consistentemente como o mesmo membro. Essa abordagem funciona mesmo se o contêiner subjacente for reiniciado, por exemplo. (Tanto corretores quanto clientes devem estar no Kafka versão 2.3, ou posterior).Ao invés de usar um grupo de consumidores, é possível atribuir partições diretamente por meio do cliente consumidor, o que não aciona rebalanceamentos. É claro que, nesse caso, você mesmo deve equilibrar as partições, e também certificar-se de que todas as partições sejam consumidas. Fazemos isso em situações em que usamos o Kafka para capturar o estado. Mantemos mensagens instantâneas associadas manualmente às partições do tópico de entrada que o nosso serviço lê.
Práticas recomendadas de particionamento de tópicos do Kafka
Seguir essas práticas recomendadas garante que a sua estratégia de particionamento de tópicos do Kafka seja bem projetada, escalonável, e alinhada com os requisitos específicos do seu caso de uso. O monitoramento regular, e ajustes ocasionais, ajudarão a manter o desempenho ideal a medida que o seu sistema evolui.
Entenda os seus padrões de acesso a dados:
- Analise como os seus dados são produzidos e consumidos.
- Considere os padrões de leitura e gravação para projetar uma estratégia de particionamento que se alinhe ao seu caso de uso específico.
Escolha um número apropriado de partições:
- Evite o particionamento excessivo, ou insuficiente.
- O número de partições deve corresponder ao nível de paralelismo desejado, e à carga de trabalho esperada.
- Considere o número de consumidores, o volume de dados, e a capacidade do seu conjunto Kafka.
Use o particionamento baseado em chave quando necessário:
- Para cenários onde a ordenação ou o agrupamento de mensagens relacionadas é essencial, aproveite o particionamento baseado em chave.
- Certifique-se de que mensagens com a mesma chave sejam atribuídas consistentemente à mesma partição para uma ordem rigorosa.
Considere a distorção de dados e o balanceamento de carga:
- Esteja ciente da possível distorção de dados, onde certas partições recebem mais dados do que outras.
- Use o particionamento baseado em chave, ou ajuste a lógica de particionamento para distribuir a carga uniformemente entre as partições.
Planeje a escalabilidade:
- Projete a sua estratégia de particionamento tendo em mente a escalabilidade.
- Garanta que a adição de mais consumidores ou corretores possa ser alcançada sem reestruturar significativamente as partições.
Defina um fator de replicação apropriado:
- Configure a replicação para garantir tolerância a falhas.
- Defina um fator de replicação adequado ao seu nível de requisitos de tolerância a falhas.
- Considere o equilíbrio entre replicação e sobrecarga de armazenamento.
Evite alterações frequentes de partição:
- Alterar o número de partições de um tópico pode ser perturbador.
- Planeje estratégias de particionamento durante a criação inicial do tópico, e evite ajustes frequentes.
Monitore e ajuste conforme o necessário:
- Monitore regularmente o desempenho do seu conjunto Kafka.
- Ajuste as estratégias de particionamento com base em mudanças nos padrões de dados, cargas de trabalho, ou recursos de conjunto.
Escolhendo a melhor estratégia de particionamento de tópicos Kafka
As suas estratégias de particionamento dependerão do formato dos seus dados, e do tipo de processamento que as suas aplicações fazem. Conforme você escala, talvez seja necessário adaptar as suas estratégias para lidar com novos volumes e formatos de dados. Considere quais são os gargalos de recursos em sua arquitetura, e distribua a carga adequadamente pelos pipelines de dados. Pode ser CPU, tráfego de banco de dados, ou espaço em disco, mas o princípio é o mesmo. Seja eficiente com os seus recursos mais limitados/caros.
Para aprender mais dicas para trabalhar com o Kafka, veja As 20 Práticas Recomendadas Para Trabalhar Com o Kafka Em Escala.
Comece a usar o New Relic.
A New Relic é uma plataforma de observabilidade, que o ajuda a desenvolver programas melhores. Você pode trazer dados de qualquer fonte digital para entender completamente como melhorar o seu sistema.
Interessado em saber como é trabalhar com a New Relic? Veja como trabalhamos com o ZenHub para alcançar o sucesso.

As opiniões expressas neste blog são de responsabilidade do autor e não refletem necessariamente as opiniões da New Relic. Todas as soluções oferecidas pelo autor são específicas do ambiente e não fazem parte das soluções comerciais ou do suporte oferecido pela New Relic. Junte-se a nós exclusivamente no Explorers Hub ( support.newrelic.com ) para perguntas e suporte relacionados a esta postagem do blog. Este blog pode conter links para conteúdo de sites de terceiros. Ao fornecer esses links, a New Relic não adota, garante, aprova ou endossa as informações, visualizações ou produtos disponíveis em tais sites.


