Kubernetesのデバッグは、ストレスが多く、時間のかかる作業になる場合があります。今回のブログでは、コンテナ、ポッド、ノードレベルの一般的なエラーを説明し、クラスタの円滑な運用に向けて適用できるヒントを考えていきます。Kubernetesを初めて使う方でも、すでに使用している方でも、Kubernetesの問題のデバッグを行うためのツールと手法を改めて学ぶことができます。
本ブログは、New RelicでKubernetesクラスタをすばやく設定し、監視を行うために必要なすべてのことを説明する、Kubernetes監視シリーズの第3部です。
前回の内容を発展させる形で、ポッドやコンテナの基礎に関する理解から、より高度なトラブルシューティングのテクニックまで、幅広いトピックをご紹介していきます。
Kubernetesデプロイメントのあらゆるレベルのトラブルシューティング
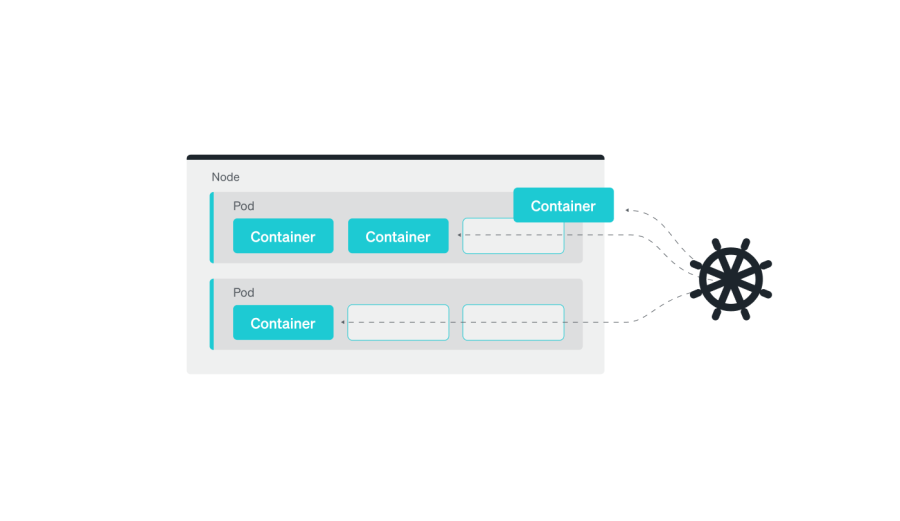
ノードのトラブルシューティング
このトラブルシューティングガイドを始めるにあたり、まずはトップレイヤーから見ていきましょう。Kubernetesのクラスタ全体の健全性を確認したい場合、クラスタ内のノードがどのように機能しているか、キャパシティはどのくらいか、各ノードで実行されているアプリケーション数、そしてクラスタ全体でのリソース使用量を確認します。
これらすべてとその他のメトリクスは、以下のコマンドを実行することで取得できます。
kubectl top nodeの出力には、CPUコア数と使用メモリ、そして全体のCPUと使用メモリに関するメトリクスが含まれます。これがトラブルシューティングの重要な第1ステップです。これでインフラストラクチャーの現在のステータスを確認できるからです。
ポッドのトラブルシューティング
Kubernetesでは、ポッドはオブジェクトモデルにおいて最小かつもっともシンプルなユニットです。これは、クラスタで実行される単一のプロセスを示します。ポッドは、Kubernetesのオブジェクトモデルの最小単位でありながら、複数のコンテナを保持することができ、これらのコンテナは同一のネットワークネームスペースを共有します。つまり、お互いがlocalhostを使用してコミュニケーションを行えるということです。ポッドはストレージボリュームも共有するため、ポッド内の全コンテナが同じデータにアクセスできます。
ポッドには、 実行中、保留、失敗、成功、そして不明などのさまざまなステータスがあります。
- 実行中のステータスは、ポッドのコンテナが実行中で健全性が保たれている状態です
- 保留のステータスは、ポッドは作成されているが、1つ以上のコンテナがまだ実行されていない状態です
- 失敗のステータスは、1つ以上のポッドのコンテナがエラーにより終了した状態です
- 成功のステータスは、ポッド内のすべてのコンテナが正常に終了した状態です。また、不明のステータスは、ポッドのステータスが特定できない状態です
ポッドのステータスを確認するには、ターミナルでkubectl get podsコマンドを使用できます。出力には、現在のネームスペース内の全ポッドの現在のステータスが表示されます。デフォルトでは、ここにポッド名、現在のステータス(例えば、実行中、保留など)、コンテナ数、ポッドの年数が表示されます。
-o wideオプションを使用して、IPアドレスやホスト名など、各ポッドに関するさらに多くの情報を得ることもできます。
ポッドは、ステータスに関する貴重な情報を提供するイベントを作成することもできます。kubectlのdescribeコマンドを使用してイベントを表示させ、現在のステータス、IPアドレス、コンテナのステータスなど、ポッドに関するより詳細な情報を得ることができます。
これは、なぜポッドがそのステータスなのかを理解するのに役立ちます。例えばイベントは、リソース不足のためポッドが移された、あるいはアプリケーションコードのエラーによりコンテナが開始に失敗したことを示しているかもしれません。
また、例えば、すべての実行中のポッドを確認するために、以下のコマンドを用いてポッドをステータスでフィルタリングすることもできます。
さらに、kubectl top podコマンドを使用して、そのポッドのリソース使用の統計を取ることもできます。
すでにKubernetesクラスタを運用しているのであれば、これらのコマンドを使用して、どんな出力を取得できるかを試してみてください。
ポッドのよくあるエラー
ポッドの現在のステータスが明らかになったので、このセクションではKubernetesのリソース(ポッド、サービス、StatefulSets)に関する一般的な問題をご紹介します。これらの一般的な問題のそれぞれを、どう理解し、トラブルシューティングを行い、解決していくかについて考えてみましょう。
Kubernetesを使用する際の問題はこれ以外にも多くありますが、このセクションで扱うのは、遭遇するであろう最も一般的なインスタンスです。
以下のリストから、それぞれのよくある問題の各セクションにジャンプすることができます。
- CrashLoopBackOffエラー
- ImagePullBackOff/ErrImagePullエラー
- OOMKilledエラー
- CreateContainerConfigErrorおよびCreateContainerError
- ポッドが保留または待機で停止
CrashLoopBackOffエラー
Kubernetesを使用する際に起こり得る最も一般的なエラーの1つは、CrashLoopBackOffエラーです。このエラーは、ポッドのコンテナがクラッシュし、ポッドの再起動ポリシーがAlwaysに設定されているKubernetes環境でよく発生します。このシナリオでは、Kubernetesはコンテナの再起動を試行し続けますが、クラッシュが続くと、ポッドはCrashLoopBackOffステータスとなります。
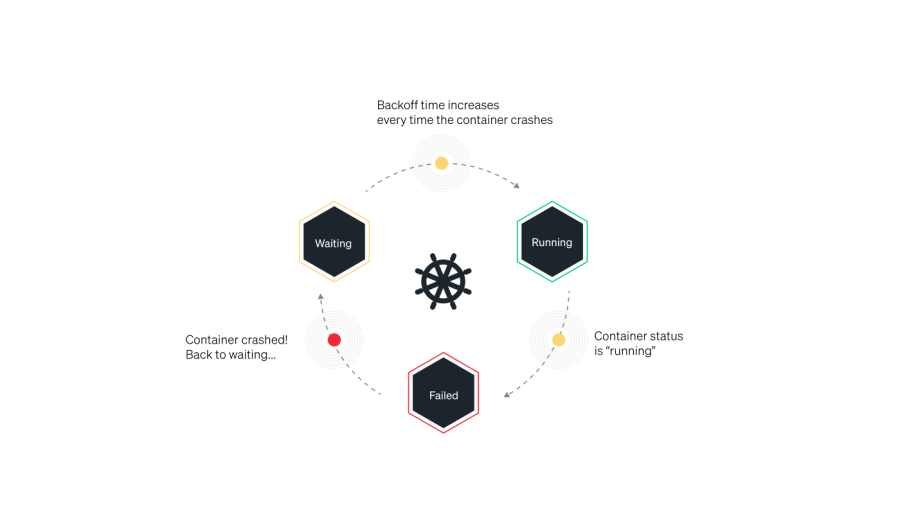
CrashLoopBackOffエラーの特定方法
kubectl get podsを実行します- 出力を確認し、以下であるかどうかを確かめます
- ポッドのステータスが
CrashLoopBackOffエラーとなっている - 複数の再起動がある
- ポッドが準備完了と認識されていない
この例では、0/1が準備完了、2が再起動を表示しており、ステータスがCrashLoopBackOffとなっています。
CrashLoopBackOffエラーの原因
STATUS列内のCrashLoopBackOffステータスは、問題の根本原因ではありません。これは単に、ポッドでクラッシュのループが起きていることを示しています。効果的にトラブルシューティングを行い、問題を修正するには、コンテナのクラッシュ原因となっている根底のエラーを特定し、それに対処する必要があります。
CrashLoopBackOffエラーの原因には、複数の可能性が考えられます。
- コンテナがメモリまたはCPUリソースを使い果たしている。
kubectlコマンドを使用してコンテナとポッドのリソース使用を確認することで検証可能です。 - イメージまたは設定の問題でコンテナが開始できない。例えば、イメージが必要な依存関係を欠いている、コンテナに必要な特定のリソースへのアクセス権限がない場合。
- コンテナがアプリケーションコードのバグによりクラッシュしている。この場合、コンテナのログでクラッシュ原因のさらなる情報を確認できることがあります。
- コンテナがネットワークの問題によりクラッシュしている。例えば、コンテナが必要なサービスに接続できないなど
CrashLoopBackOffエラーのトラブルシューティング
CrashLoopBackOffエラーを示しているポッドを特定し、以下のステップに従って根本原因を特定します。
1. 以下のコマンドを実行します
2. ポッドがLiveness Probeの失敗またはback-off restarting failed containerエラーにより失敗している場合は、以下のコマンドで有益な知見を得られます
3. back-off restarting failed container、またLiveness probe failedのエラーメッセージを受け取った場合、ポッドはアクティビティの急増による一時的なリソースのオーバーロードを経験している可能性があります。
この問題を解決するには、periodSecondsまたはtimeoutSecondsのパラメータを調整して、アプリケーションが対応するために必要な時間を設けます。これにより、ポッドが回復します。
ImagePullBackOff/ErrImagePullエラー
Kubernetesのクラスタには、各ノードに、そのノードでコンテナを実行するためのkubeletと呼ばれるエージェントがあります。コンテナイメージがまだノードに存在していない場合、kubeletはコンテナのランタイムを指示してコンテナイメージを取得します。
Kubernetesのポッドがイメージプルの問題に遭遇すると、まずErrImagePullエラーが生成されます。次に、システムは何度かイメージのダウンロードを試みた後、最終的に「プルバック」して他の方法を試します。他の方法が失敗するごとに、再試行にかかる遅れが指数関数的に増加し、最大で5分の遅延を生じます。
Kubernetes環境でのImagePullBackOffとErrImagePullエラーは、通常、Kubernetesノードが特定のイメージをコンテナレジストリから取得できない場合に起こります。これには、いくつかの理由が考えられます。
- イメージが指定されたコンテナレジストリに存在していないか、ポッド定義でのイメージ名のスペルが間違っている
- イメージがプライベート領域にあり、ポッドにそれを取得する権限がない
- ポッドのネットワークにコンテナレジストリへのアクセス権がない
- ポッドにコンテナレジストリからイメージをプルする十分な権限がない
ImagePullBackOffエラーの特定方法
1. kubectl get podsを実行します
2. 出力を確認し、ポッドのステータスがImagePullBackOff エラーとなっているかどうかを確かめます
ImagePullBackOffエラーのトラブルシューティングの方法
ImagePullBackOffエラーのトラブルシューティングには、まずkubectl describeを実行して、イベント下の特定のエラーをレビューします。それぞれのエラーに対し、以下の推奨アクションを実行します。
Repository does not exist or no pull access- これは、ポッドで指定されたリポジトリが、クラスタの使用しているDockerレジストリに存在しないことを意味します。
- デフォルトで、イメージはDockerハブから取得されますが、クラスタが1つ以上のプライベートレジストリを使用している可能性があります
- ポッドが正しいリポジトリ名を指定していないため、または完全に適格な正しいイメージ名(username/imagenameなど)を指定していないため、エラーが発生している可能性があります
- このエラーの別の理由として、DockerHubやその他のコンテナレジストリのレート制限のため、kubeletがイメージを取得できないことが考えられます
Manifest not found- これは、リクエストされたイメージの特定のバージョンが見つからなかったことを意味します。タグを指定していた場合は、そのタグが間違っていたことを意味します
- これを解決するには、ポッドの仕様のタグが正しいこと、またそれがリポジトリに存在することを再確認します。レポジトリ内のタグは変わることがあることに注意してください。タグを指定していない場合は、イメージにlatestタグがついているかどうかを確認してください。有効なタグを指定していない場合、latestタグのないイメージは返されません
Authorization failed- このケースでは、指定した識別情報ではコンテナレジストリまたはリクエストした特定のイメージにアクセスできないことが問題です。
- これを解決するには、適切な識別情報でKubernetes Secretを作成し、それをポッドの仕様に参照します。すでに承認されたSecretがある場合、それらの識別情報に、必要なイメージにアクセスしたり、コンテナリポジトリでのアクセスを承認する権限があるかどうかを確認します。
OOMKilledエラー
Kubernetesでは、仮想マシン(VM)で実行されるkubeletsには、アウトオブメモリー(OOM)の問題を含め、さまざまなプロセスのメモリ使用を追跡するMemory Managerという機能があります。VMがメモリを使い果たしそうになると、システム全体のクラッシュを回避するのに必要なメモリを確保できるように、Memory Managerはポッドを最少量で削除します。
OOMKilled Errorが発生するシナリオには2種類あります。
1.コンテナが上限に達したため、ポッドが終了する
Container Limit Reachedエラーは、単一のポッドで発生します。Kubernetesは、ポッドが設定された上限を超えるメモリを使用していることを検知すると、 OOMKilled - Container Limit Reachedエラーメッセージを出してそのポッドを終了します。
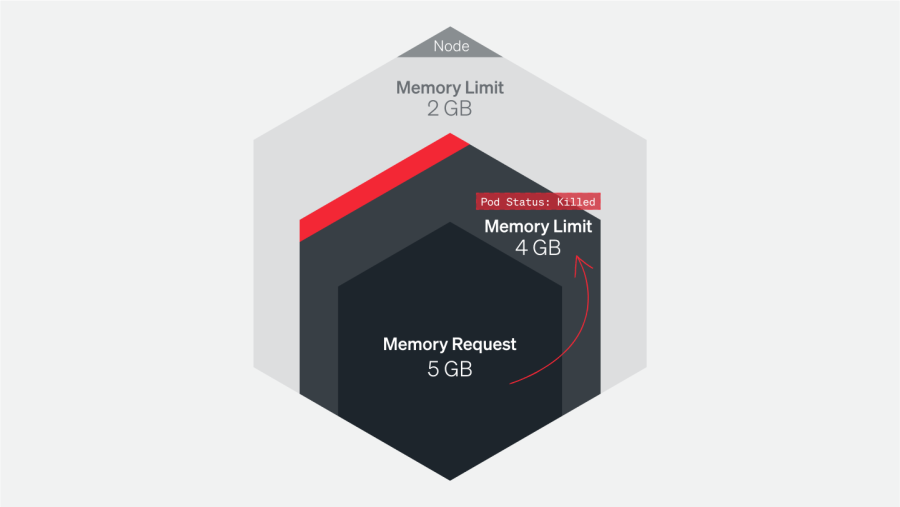
このエラーのトラブルシューティングには、アプリケーションログを確認して、なぜそのポッドが設定上限を超えるメモリを使用していたのかを理解することが重要です。トラフィックの急増、Kubernetesジョブの長時間による実行、もしくはアプリケーションのメモリリークによるものかもしれません。
原因を突き止めましょう!もしアプリケーションが想定通りに実行され、単に運用のためにさらなるメモリを必要としていることが分かったら、そのリクエスト向けの値とポッドの上限を増やすことを検討します。ポッドとクラスタのリソース使用とパフォーマンスの監視も、問題を特定し、将来的に回避するための方法を見つけるのに役立ちます。
2. ノードが「オーバーコミット」のためにポッドが終了する
ノードにスケジュールされたポッドが、合計するとそのノードで使用できるよりも多いメモリをリクエストする場合があります。
OOMKilled: Limit Overcommitエラーは、あるノードの全ポッドの合計の必要メモリが、そのノードで使用できるメモリ量を超えた場合に発生します。この問題は、本シリーズの第2部でも説明しています。
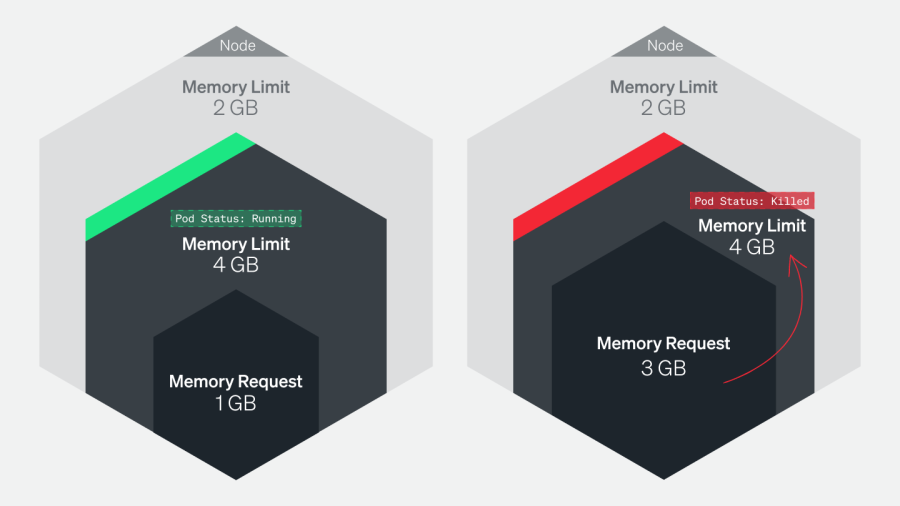
例えば、5GBのメモリを持つノードがあり、そのノードで、それぞれのメモリ上限が1GBの5つのポッドを実行するとします。合計のメモリ使用量は、上限内の5GBとなるはずです。ただし、これらのポッドのうちの1つに、より高い上限値、例えば1.5GBが設定されていると、合計のメモリ使用量が使用可能なメモリ量を超えてしまい、OOMKilledエラーを引き起こします。これは、ポッドでトラフィックの急増や想定外のメモリリークが起こった際に発生することがあり、Kubernetesはメモリを回収するためにポッドを終了します。
ホスト自体を確認し、Kubernetesの外部でメモリリソースを消費し、そのポッドの使用可能量を減らしている他のプロセスが実行されていないことを確認することが重要です。また、メモリ使用を監視し、それに従ってポッドの上限を調整することも大切です。
OOMKilledエラーの特定方法
1. kubectl get podsを実行します
2. 出力を確認し、ポッドのステータスがOOMKilledエラーとなっているかどうかを確かめます
OOMKilledエラーのトラブルシューティングの方法
OOMKilledエラーの対応方法は、ポッドが終了した理由により変わります。コンテナの上限や、オーバーコミットのノードが原因で終了した可能性があります。
コンテナの上限のためにポッドが終了した場合
OOMKilled: Container Limit Reachedエラーを解決するには、まずそのアプリケーションが本当により多くのメモリを必要としているのかを判断することが重要です。アプリケーションでロードや使用の増加が見られる場合、最初に割り当てられていた以上のメモリを要求するかもしれません。この場合は、エラーに対処するためにポッドの仕様でコンテナのメモリ上限を増やすことができます。特定のポッドのログを取得することで、このケースに該当するかどうかを確認できます。kubectlログのポッド名を実行し、リクエストに明らかな急増があるかどうかを判断します。
しかし、メモリ使用が想定外に増え、アプリケーションの要求とは関連していないような場合、これはアプリケーションにメモリリークが起こっていることを示唆している可能性があります。この場合、アプリケーションをデバッグし、そのメモリリークの発生源を特定する必要があります。根底にある問題に対応することなく単純にアプリケーションのメモリ上限を増やせば、問題が解決されないまま、より多くのリソースを消費するだけという状況に陥りかねません。リークの根本原因に対応し、再発を防止することが大切です。
ノードの「オーバーコミット」のためにポッドが終了した場合
ポッドは、そのノードで使用できるメモリと比較したメモリリクエスト値に基づきノードにスケジュールされています。しかし、これがメモリのオーバーコミットにつながることがあります。オーバーコミットにより発生するOOMKilledエラーのトラブルシューティングとその解決には、なぜKubernetesがそのポッドを終了したのかを理解することが重要です。そうすることで、メモリの上限とリクエストを調整し、ノードがオーバーコミットしないことを確実にできます。
これらの問題の発生を防ぐため、つねに環境を監視してポッドとコンテナのメモリの動作を理解し、定期的に設定を確認することが重要です。このアプローチは、潜在的問題を早期に特定し、問題の拡大を防ぐための適切なアクションを取るのに役立ちます。ポッドとコンテナのメモリの動作をよく理解し、設定内容を確認することで、Kubernetesのメモリに関する問題を早期に診断し、解決できるようになります。
CreateContainerConfigErrorおよびCreateContainerError
KubernetesのCreateContainerConfigErrorとCreateContainerErrorは、ポッドのコンテナ設定作成に問題があるときによく発生します。一般的な原因は以下の通りです。
- 無効なイメージ名またはタグ:ポッドの定義で指定されているイメージ名とタグが有効であり、指定されたコンテナレジストリからプルできることを確認します
- イメージプルシークレットがない:イメージがプライベートレジストリにある場合、必要なイメージプルシークレットがポッドの定義で定義されていることを確認します
- 許可が不十分:ポッドが使用するサービスアカウントに、指定のイメージをレジストリからプルするのに必要な権限があるかを確認します
CreateContainerConfigErrorやCreateContainerErrorの特定方法
kubectl get podsを実行します
2. 出力を確認し、ポッドのステータスがCreateContainerConfigErrorとなっているかを確かめます
CreateContainerConfigErrorやCreateContainerErrorのトラブルシューティングの方法
1. ポッドの定義のイメージ名やタグに、エラーや誤りがないかを確認します。指定されたコンテナレジストリにイメージが存在しない場合、このエラーが発生します。
2. 指定されたイメージプルシークレットが有効であり、ネームスペースに存在することを確認します。また、サービスが指定のイメージをレジストリからプルするために必要な権限があることを確認します。kubectl auth can-iコマンドを実行して、サービスアカウントに指定のアクションを実行するのに必要な権限があるかを確認できます。例えば、このコマンドを使用して、my-service-accountという名のサービスアカウントがNGINXリポジトリからNGINXイメージをプルできるかどうかを確認してみましょう
<namespace>を、サービスアカウントが置かれているネームスペースに置き換えます。コマンドがyesを返してきたら、サービスアカウントにはNGINXイメージをプルするのに必要な権限があります。コマンドがnoを返してきたら、サービスアカウントには必要な権限がありません。
3. Kubernetesログを確認し、エラーについてのさらなる詳細を確認します
4. kubectl describe pod <pod-name>コマンドを使用して、ポッドのさらなる詳細を取得し、何らかのエラーメッセージがないかを確認します
ポッドが保留または待機で停止
第2部では、ワークロードのリクエストと上限値をどのように適正化するかについて話をしました。では、適正に設定しなかったら、どうなるのでしょうか?ポッドのステータスが、保留または待機で停止するかもしれません。ノードへのスケジュールが行えないからです。
ポッドがペンディングとなり、で停止した場合
イベントセクションのdescribe pod outputを確認します。なぜポッドがスケジュールできなかったかを示すメッセージを探しましょう。以下のような例があります。
- クラスタのCPUまたはメモリのリソースが不足している。これは、いくつかのポッドを削除するか、ノードにリソースを追加する、またはノードを追加する必要があることを意味します。
- 特定のリソースの要求のために、ポッドのスケジュールが難しい可能性がある。ポッドが追加ノードへのスケジューリング資格を得られるよう、いくつかの要求をリリースできるかを確認します。
ポッドの待機時間が長い場合
ポッドのステータスが待機の場合、ノードにスケジュールされているものの、実行ができないことを示します。kubectl describe <podname>を実行し、イベントセクションでポッドが実行できない理由を探します。
最も多いのは、イメージ取得時のエラーによりポッドが待機で停止しているケースです。以下の問題を確認してください。
- ポッドマニフェストのイメージ名が正しいことを確認する
- レポジトリのイメージが確実に使用できることを確認する
- イメージを取得できるかどうかを手動で検証してみる。ローカルのマシンで
docker pullコマンドを実行し、適切な権限があることを確認する
New RelicでのKubernetesのトラブルシューティング
Kubernetesでのトラブルシューティングのプロセスは複雑です。正しいツールがなければ、デバッグはストレスが多く、非効率で時間のかかる作業になりかねません。ベストプラクティスには障害が発生する確率の最小化に役立つものもありますが、最終的には障害は発生します。単純に、確率はゼロにはならないからです。
New Relicは、すべてのオブザーバビリティデータに対する信頼できる唯一のソースとして使用できます。アプリケーション自体からKubernetesのコンポーネント、そしてVMのインフラストラクチャーメトリクスに至るまで、Kubernetesスタックのあらゆる箇所から、すべてのメトリクス、ログ、トレースを収集します。
Next steps
自社環境でKubernetes監視を試す準備ができているのであれば、今すぐNew Relicアカウントにご登録ください。無料のアカウントには、New Relicのすべてにアクセスできる1ユーザーと、そのレポートを閲覧できる人数無制限の基本ユーザー、さらに毎月100GBの無料データが含まれます。
試してみたい場合は、New RelicのKubernetesのビルド済みダッシュボードと一連のアラートをぜひご利用ください。
まだ開始する環境が整っていない場合には、本ガイドで紹介されている機能に慣れるために、ローカルでこのデモアプリケーションにサインアップして起動してみましょう。
本シリーズの第4部では、New RelicでのKubernetessのオブザーバビリティデータ管理について詳しく見ていきます。


The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.

