As part of our “/blog/search?s=life+at+new+relic" target="_blank" rel="noopener noreferrer">Life at New Relic” blog series, we recently sat down with Josh Biggley, an Ops Strategist on the TechOps Strategy Consulting team. In this role, Josh and his team, with experience spanning telecoms to tech startups, healthcare to managed services, meet with customers and prospects to strengthen the adoption of fellow Ops SMEs. Josh joined New Relic in November 2019 from Cardinal Health, where he was a Senior Engineer on the Enterprise Monitoring team.

New Relic: There's been a lot of talk in the market and the Twittersphere about observability. How would you define observability?
Josh: My background and claim to fame was being a SolarWinds subject matter expert for more than a decade. I was one of about 50 MVPs for their user community globally, a role I resigned to join New Relic and the only MVP in Canada. When I came over to New Relic, the pitch was, “Yeah, [New Relic] can bring the Orion Platform data [into the NRDB].” To prove out that theory, I authored Part 1 of a blog series, focusing on the strategy of observability for SolarWinds SMEs.
For me, observability is about the democratization of data. It doesn't matter if that data is telemetry data or business data. We need to break down data silos and bring all of the data together to make informed decisions.
As a customer, I preached this democratized access to data to our architecture and account teams. Our CEO, Lew Cirne, uses the phrase “single source of truth,” which also resonates. Observability, for me, is about asking the questions of my data in two formats:
- What are the things that I know that I need to ask about my data?
- What are the things that I don't even know that I'm going to have to ask of my data, and will I be able to do that?
And then, it's driven by a couple of parameters, including data cardinality, data fidelity, and data granularity. If we can check those boxes, we can answer those “known knowns” questions and importantly, the “unknown unknowns.”
New Relic: What would you say is required for full observability?
Josh: Observability requires a change in culture for a lot of organizations. We enable the technical parts, collecting data at a more granular interval, going from 5 and 10 minutes down to 10 seconds, or even looking at our tracing products, doing both head and tail-based tracing so we have everything. But you can have the very best platform, and I talked about this in the webinar we just did, you can have nano stack and granularity on your data, but if you don't change the culture within your organization—where you pursue democratized access to data, start enabling teams to ask questions, and take actions on the questions that you ask of your data set—then you've missed the essence of observability while trying to achieve the technical realities of it. Just like DevOps, observability is a cultural and people-based movement as much as it is a technological one.
New Relic: Do average developers and different teams have an interest in access to democratized data? Does everyone want this?
Josh: I think that everyone wants it, as long as they've got the right mindset. Unfortunately, some teams within organizations value or measure their value by the data gatekeeping that they can put in place. That is the antithesis of observability.
Observability is all about destroying gates.
So if we can break down those gates, then that's the right thing to do. I can't speak specifically to the developer persona, but I can use an example from my Cardinal Health role. For the principal network architect at Cardinal Health, this scenario played out far too often for his team.
So, an application starts to experience problems. The application owners hop on, start to do their triaging, immediately see those issues, and blame the network team. The network team then has to hop on, collect some telemetry data, start doing some packet captures, and then do some analysis of those packet captures. Then they come back to the application team and say, "No, it's not us. Here's what we see," like a failed handshake or something. "It's not us. It's not a network issue, and we have all this bandwidth."
So this principal architect said to me, "Josh, I love this idea of observability, because it means I can take the network data we already are collecting and immediately show that to our application teams and say, ‘Hey, you expect to have this much bandwidth and this kind of latency under this threshold of errors so you can determine right at the very beginning of your troubleshooting that it's not a network issue.’"
So you're not paging someone in the middle of the night. You're not taking away cycles from my team, completing the projects that they need to. You're just allowing us to focus on what we need to prioritize, which is solving network-related problems, but also allowing your teams to move faster. No need to wait for network engineers to hop on and do their analytics.
By breaking down data silos and democratizing access to that data, you can move past the blame game of “it's the network” or “it’s the code.” It doesn't matter if we're talking about network data, database performance, frontend, backend, or middleware. It's about bringing all of that data together and letting people ask, "Hey, is it the network? Is it my storage, infrastructure, or application?” Or is it one user complaining, but just complaining loudly to our CIO that things are broken?
New Relic: So quickly identifying where the problem is, reducing MTTR, and getting sleep are pretty important benefits.
Josh: Yeah. And I would say something that we don't talk about enough in the industry is the difference between mean time to detect, mean time to understand, and mean time to resolve. Often, you know what the problem is and you can put in some sort of strategy to mitigate it, but you can't resolve the broader issue until you hit a maintenance window. At New Relic, observability enables us to do the mean time to detect and the mean time to understand. That will allow the customer to hopefully reduce the overall window that an issue remains open—the time from when the issue starts to the time it takes to understand and resolve it.
But there's only so much influence that technology can have. That mean time to resolve is all cultural. Are you going to allow me to push a code update in the middle of the day? Do we trust ourselves to do that? Can I make a change to my dynamic environment? Lots of traditional organizations are like, "Nope, you’ve got to wait until your maintenance window." And that's just awful for engineers, for the company, and most importantly, for customers.
New Relic: How does having observability make you feel as an operations person, a customer, as someone responsible for ensuring systems are running?
Josh: I've recently realized that observability allows me to be a data storyteller. I'm a data geek. I love data. I love to tell stories, and I find that the best stories are told when you interweave a narrative with compelling data. And that's why democratized access to data is a game-changer. There's nothing worse than trying to tell a story and not having access to the data that I need to tell that story.
Observability enables me to be a data storyteller by having access to all of the data. It allows me to be a better leader, galvanize necessary support within the organization, and achieve goals.
Data can say anything you want, which is why you need trusted storytellers. My favorite quote about data is there are three types of lies in the world: lies, damn lies, and statistics. It's very accurate, unfortunately. But within an organization, compelling stories told by data storytellers will move the organization forward on that path of observability.
New Relic: Can you tell us an anecdote or a story about practicing observability?
Josh: During my last year at Cardinal Health, I was part of a leadership training initiative for high-performing, high-potential individuals. My group’s challenge was to reduce the amount of data that we collected in GCP while not impacting business.
So I had to weave this narrative of the business expectations for the data that we were collecting. And engineers want all the data, right? Because their narrative is “storage is cheap, so just give us all your data.” The reality is that when you start collecting data at a multi-petabyte scale, even for a large organization like Cardinal Health, it can get expensive.
When we started to look at the data, we started to weave this story around the question, what does the data start to tell us? And we ran into a bunch of blockers. Security said, "No, the data tells us this story." The cloud architects were saying, "No, the data tells us this other story." In the end, we were able to find a single common thread.
And this is why storytellers are so important, because you hear these two stories, and then you suddenly can overlap them and map the data to that overlap. And it was by mapping the data to the overlap that allowed us to make a single change that reduced our costs by something in the neighborhood of 65%. That was the best part because we found that overlapping thread.
So we made the change, and none of the technical teams were arguing about us making that change. They didn't notice that we had made a change. Obviously, the financial people did, because that was our goal: to reduce cost. Reduce cost, no technical impact. But yeah, we made the change and we went to some technical people and said, "Okay, so we made the change." They said, "When?" "Like days ago." "Oh, okay." And that was it.
The best data analysts are your best storytellers. And I think that everyone needs to be a data analyst, which is why observability matters. In this case, we were looking at a very specific data set for a very specific business requirement. Observability enables everyone to become a data storyteller. And to Lew's point, it's a trusted data set.
New Relic: Can we talk about another big topic—monitoring versus observability?
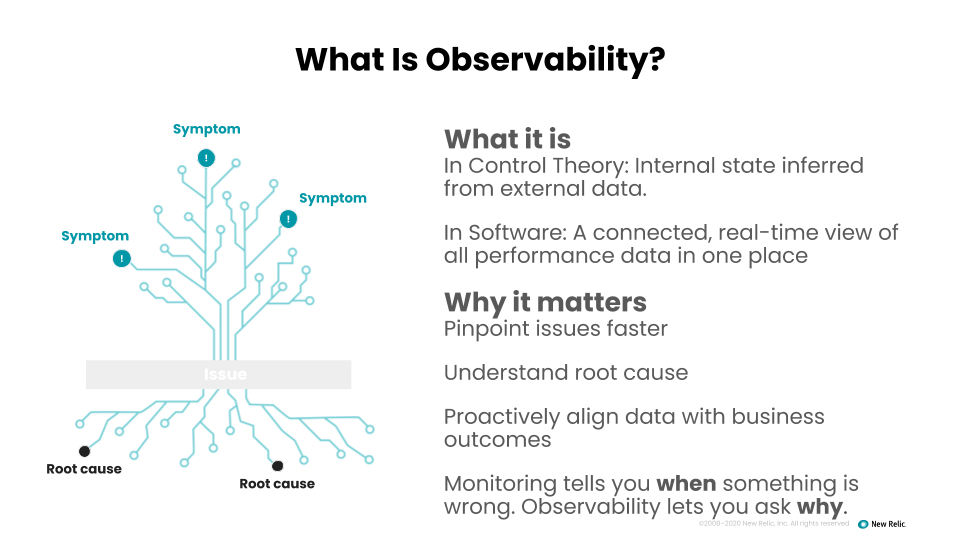
Josh: Heck, yeah! Monitoring tells you when something is wrong, observability lets you ask why. Monitoring is all about trying to preemptively anticipate how your system's going to fail. I’ve heard it said that if you're monitoring for a failure, why don't you just fix it in the first place, instead of waiting for things to fail? It's almost like, "Oh, I know that thing's going to fall over. I'm just going to watch it until it falls, and then I'll jump in." I think that's the argument between monitoring being passive and observability being an active approach.
Stay tuned for the second installment of this “Life at New Relic” post. For our previous post, see how engineer management is like at New Relic. To read more about observability, check out Observability in 2020: A Manifesto. For more about New Relic platforms, see our Infrastructure monitoring system

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (support.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


