In today's complex and interconnected technological landscape, maintaining robust and reliable infrastructure is paramount for businesses to deliver seamless digital experiences to their customers. However, as systems grow in size and complexity, issues and incidents can increase, leading to downtime, performance degradation, and frustrated users. To address these challenges, organizations need an efficient and systematic approach to identify and resolve the root causes of such problems. This is where root cause analysis (RCA) comes into play.
This blog post provides a comprehensive guide on how to maximize infrastructure monitoring for effective root cause analysis. Specifically, you’ll:
- Understand the concept and importance of root cause analysis.
- Discover how infrastructure monitoring supports RCA.
- Learn best practices for conducting a successful RCA.
- Overcome common challenges associated with RCA.
- Harness the power of the New Relic infrastructure agent for optimized monitoring and RCA.
What is root cause analysis?
Root cause analysis is a systematic approach to problem-solving that aims to identify and address the underlying causes of incidents, disruptions, or anomalies within your infrastructure. It's essential to recognize that incidents are not isolated events. They are often indicators of underlying systemic issues or vulnerabilities within the infrastructure. By conducting a thorough root cause analysis, you can gain valuable insights into these underlying causes, allowing you to implement targeted remedial actions and prevent the recurrence of incidents. This proactive approach can minimize downtime, enhance system performance, and improve overall operational efficiency. Root cause analysis helps to:
- Pinpoint the root causes responsible for the incident or problem.
- Uncover contributing factors and dependencies that played a role in the problem.
- Identify potential systemic weaknesses or vulnerabilities.
- Validate assumptions and ensure an accurate diagnosis.
- Inform decision-making for implementing effective corrective actions.
By focusing on the root cause rather than just the symptoms, you can prevent recurring problems and enhance the overall stability of your systems.
How infrastructure monitoring supports root cause analysis
Infrastructure monitoring plays a pivotal role in supporting effective RCA by providing critical insights into the performance and health of your infrastructure components. It helps you gain a comprehensive understanding of your system's behavior, which is vital for identifying and resolving underlying issues. Let’s review five key ways that infrastructure monitoring supports RCA with examples from the New Relic infrastructure agent.
Real-time data collection and visualization
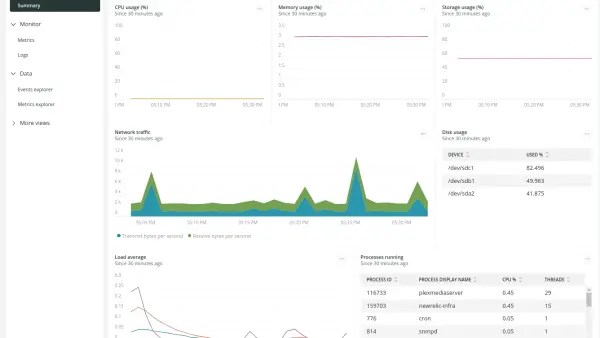
Infrastructure monitoring tools collect a wide range of real-time data from your infrastructure, including metrics, logs, events, and traces. This data provides valuable insights into the behavior and performance of your systems. By visualizing this data through intuitive dashboards and graphs, you can quickly identify anomalies, patterns, and trends that may indicate root causes.
The next image shows an example dashboard that visualizes data collected by the New Relic infrastructure agent.
Alerting and anomaly detection
Infrastructure monitoring systems can be configured to generate alerts based on predefined thresholds or anomalies. These alerts notify you of critical events, such as service disruptions, high resource utilization, or abnormal system behavior. Timely alerts enable you to investigate and address potential root causes before they escalate into major incidents.
The next image shows the Activity stream of recent anomalies captured through the New Relic infrastructure agent. Read AIOps Made Easy: Get to the root cause and respond faster to learn how you can use the New Relic alerting and anomaly detection capabilities.
Log management and correlation
Logs are invaluable sources of information for RCA. Infrastructure monitoring tools provide log management capabilities, allowing you to aggregate, store, and analyze logs from various components of your infrastructure. By correlating logs with other metrics and events, you can uncover the relationships between different system elements and trace the sequence of events leading to an incident. Read more about correlating log data in How to simplify your troubleshooting with logs in context and Reduce mean time to detect and resolve issues with correlated log data.
The next image shows logs collected through the New Relic infrastructure agent.
Integration with other monitoring and analytics tools
Infrastructure monitoring often integrates with other diagnostic tools and systems, such as application performance monitoring (APM), network monitoring, and log analysis platforms. These integrations provide a holistic view of your infrastructure and facilitate cross-domain analysis. By combining data from various sources, you can correlate events, identify dependencies, and pinpoint the root causes of complex issues that span multiple components.
The next image captures the host view of the New Relic infrastructure agent and shows the performance and behavior of the APM application Login Service within the infrastructure.
Historical data analysis
Infrastructure monitoring systems store historical data, allowing you to perform trend analysis. By analyzing historical patterns, you can identify recurring issues, understand the impact of changes, and uncover long-term root causes. Trend analysis also helps you detect and devise preventive measures for underlying issues that may not be immediately apparent.
By leveraging infrastructure monitoring, you gain real-time visibility into your infrastructure's performance, helping you to detect anomalies and proactively address potential root causes. This proactive approach minimizes downtime, reduces mean time to resolution (MTTR), and improves overall system stability.
Best practices for effective root cause analysis
To conduct an effective root cause analysis, it is essential to follow a set of best practices that streamline the process and maximize the chances of identifying the underlying causes accurately. Here are some key practices to consider:
Establish a standard process for root cause analysis
To ensure consistency and efficiency in RCA, it is crucial to establish a standardized process that outlines the steps, roles, and responsibilities involved. By documenting a clear and structured RCA process, you provide a framework for teams to follow, reducing ambiguity and improving collaboration. This process should include steps such as incident reporting, data collection, analysis, root cause identification, and corrective action implementation.
Use appropriate root cause analysis tools
Employing the right tools can significantly enhance the effectiveness of RCA. As mentioned earlier, the New Relic infrastructure agent provides powerful monitoring capabilities that enable you to collect and analyze crucial infrastructure data. Additionally, you can leverage other RCA tools like fault tree analysis, fishbone diagrams, or the 5 Whys technique, depending on the complexity of the issue. These tools help visualize relationships between factors and guide the investigation towards the root cause.
Involve multiple stakeholders
Effective RCA requires collaboration and input from various stakeholders involved in managing the infrastructure. This includes system administrators, developers, operations teams, and any other relevant parties. By involving different perspectives and expertise, you gain a comprehensive understanding of the problem and increase the chances of uncovering the true root cause. Encourage open communication and facilitate cross-team collaboration to foster a collaborative RCA environment.
Document root cause analysis results
Documentation plays a vital role in RCA, as it ensures that findings, actions, and lessons learned are captured for future reference. It helps create a knowledge base that can be shared across teams, enabling others to learn from past incidents and preventing recurring issues. Include detailed descriptions of the problem, analysis techniques used, identifying root causes, implementing solutions, and the outcomes of those actions. This process is closely aligned with conducting an incident post mortem, which further delves into analyzing the incident comprehensively to improve future response and prevention strategies.
Continuous improvement of the root cause analysis process
RCA is an iterative process that can be continuously refined and improved over time. Encourage a culture of learning and improvement within your organization by conducting regular reviews of the RCA process. Analyze the effectiveness of the process, identify any bottlenecks or areas for improvement, and implement necessary changes. Solicit feedback from stakeholders involved in RCA and encourage them to contribute ideas and suggestions for process enhancement.
By following these RCA best practices, you establish a solid foundation for conducting thorough investigations and resolving infrastructure issues effectively.
How to overcome root cause analysis challenges
RCA can present several challenges, making it essential to have the right tools and strategies in place. Some of the common challenges include:
- Limited visibility: In complex infrastructure environments, gaining comprehensive visibility into the performance of various components can be a challenge. Without a clear view of your systems, it becomes difficult to identify the root causes of issues.
- Identifying root causes among complex systems: In intricate infrastructures with interconnected systems and dependencies, pinpointing the exact root cause of an issue can be like finding a needle in a haystack.
- Collaborating across teams: RCA often requires collaboration among different teams, such as operations, development, and support. Coordinating efforts and sharing insights across these teams can be time-consuming and prone to miscommunication.
With the right infrastructure monitoring tool, you can overcome all of these challenges. Let’s see how New Relic provides support for all of these cases:
Comprehensive visibility with real-time monitoring
The New Relic infrastructure agent offers real-time monitoring and data collection for a wide range of metrics. By leveraging the agent's capabilities, you can gain insights into critical infrastructure elements, including servers, databases, containers, and more. Monitoring key metrics such as CPU usage, memory consumption, and network activity allows you to spot anomalies and investigate their root causes swiftly.
Advanced analytics and correlation
The New Relic infrastructure agent provides advanced analytics and correlation capabilities that enable you to analyze vast amounts of data, like logs and metrics, from multiple sources. By correlating this information, you can identify patterns or anomalies that help narrow down potential root causes. This significantly simplifies the RCA process and saves valuable time and effort.
Consolidated data and visualizations for effective communication
The New Relic infrastructure agent facilitates effective cross-team communication and troubleshooting by consolidating data and visualizations in one place. With shared dashboards, teams from operations, development, and support can access real-time data simultaneously, fostering seamless collaboration. This consolidated approach accelerates root cause analysis and cultivates a culture of knowledge sharing and teamwork, empowering teams to investigate and resolve incidents efficiently.
For example, imagine a scenario where a web application experiences intermittent slowdowns. By using New Relic infrastructure monitoring, you can quickly identify high CPU utilization on a specific server during periods of slowdown. The next image shows how New Relic visualizes high CPU utilization on a host for an example web application called Tower-Washington.
With this information, the operations team can investigate further and discover what is causing the performance degradation. For the Tower-Washington app, a background process was consuming excessive resources. The operations team can then share this insight with the development team to work together to optimize the process and prevent future incidents.
In summary, infrastructure monitoring platforms like New Relic help overcome challenges with root cause analysis by providing comprehensive visibility, advanced analytics, and collaborative features. By leveraging these capabilities and following best practices, you'll gain real-time insights that help you streamline RCA processes and prevent incidents from recurring.
Next steps
Improve your team’s root cause analysis with New Relic:
- Sign up for a free account. Your account includes 100 GB/month of free data ingest, one free full-platform user, and unlimited basic users.
- Install the New Relic infrastructure agent, or explore the integration options that New Relic offers to send data to the New Relic platform.
- Learn how to manage your data collected by the New Relic infrastructure agent.

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (support.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.