This is part two of a five-part series on Kubernetes Fundamentals. Check back for new parts in the following weeks.
Kubernetes is the leading orchestration platform for containerized applications. To manage containers effectively, Kubernetes needs a way to check their health to see if they are working correctly and receiving traffic. Kubernetes uses health checks—also known as probes—to determine if instances of your app are running and responsive.
In this article, we’ll discuss the different probe types and the various ways to use them.
Why Probes are Important
Distributed systems can be hard to manage. Since the separate components work independently, each part will keep running even after other components have failed. At some point, an application may crash. Or an application might be still in the initialization stage and not yet ready to receive and process requests.
You can only assert the system's health if all of its components are working. Using probes, you can determine whether a container is dead or alive, and decide if Kubernetes should temporarily prevent other containers from accessing it. Kubernetes verifies individual containers’ health to determine the overall pod health.
Types of Probes
As you deploy and operate distributed applications, containers are created, started, run, and terminated. To check a container's health in the different stages of its lifecycle, Kubernetes uses different types of probes.
Liveness probes
Allow Kubernetes to check if your app is alive. The kubelet agent that runs on each node uses the liveness probes to ensure that the containers are running as expected. If a container app is no longer serving requests, kubelet will intervene and restart the container.
For example, if an application is not responding and cannot make progress because of a deadlock, the liveness probe detects that it is faulty. Kubelet then terminates and restarts the container. Even if the application carries defects that cause further deadlocks, the restart will increase the container's availability. It also gives your developers time to identify the defects and resolve them later.
Readiness probes
Readiness probes run during the entire lifecycle of the container. Kubernetes uses this probe to know when the container is ready to start accepting traffic. If a readiness probe fails, Kubernetes will stop routing traffic to the pod until the probe passes again.
For example, a container may need to perform initialization tasks, including unzipping and indexing files and populating database tables. Until the startup process is completed, the container will not be able to receive or serve traffic.
During this time, the readiness probe will fail, so Kubernetes will route requests to other containers. A pod is considered ready when all of its containers are ready. That helps Kubernetes control which pods are used as backends for services. If not ready, a pod is removed from service load balancers.
Startup probes
Startup probes are used to determine when a container application has been initialized successfully. If a startup probe fails, the pod is restarted. When pod containers take too long to become ready, readiness probes may fail repeatedly. In this case, containers risk being terminated by kubelet before they are up and running. This is where the startup probe comes to the rescue.
The startup probe forces liveness and readiness checks to wait until it succeeds so that the application startup is not compromised. That is especially beneficial for slow-starting legacy applications.
Creating Probes
To create health check probes, you must issue requests against a container.
There are three ways of implementing Kubernetes liveness, readiness, and startup probes:
- Sending an HTTP request
- Running a command
- Opening a TCP socket
HTTP Requests
An HTTP request is a common and straightforward mechanism for creating a liveness probe. To expose an HTTP endpoint, you can implement any lightweight HTTP server in your container.
A Kubernetes probe will perform an HTTP GET request against your endpoint at the container's IP to verify whether your service is alive. If your endpoint returns a success code, kubelet will consider the container alive and healthy. Otherwise, kubelet will terminate and restart the container.
Suppose you have a container based on an image named k8s.gcr.io/liveness. In that case, if you define a liveness probe that uses an HTTP GET request, your YAML configuration file would look similar to this snippet:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
The configuration defines a single-container pod with initialDelaySeconds and periodSeconds properties that tell kubelet to execute a liveness probe every 3 seconds and wait 3 seconds before performing the first probe. Kubelet will check whether the container is alive and healthy by sending requests to the /healthz path on port 8080 and expect a success result code.
Commands
When the HTTP requests are not suitable, you can use command probes.
Once you have a command probe configured, kubelet executes the cat /tmp/healthy command in the target container. Kubelet considers your container alive and healthy if the command succeeds. Otherwise, Kubernetes terminates and restarts the container.
This is how your YAML configuration would look for a new pod that runs a container based on the k8s.gcr.io/busybox image:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
The above configuration defines a single container pod with the initialDelaySeconds and the periodSeconds keys tell kubelet to perform a liveness probe every 5 seconds and wait 5 seconds before the first probe is completed.
Kubelet will run the cat /tmp/healthy command in the container to execute a probe.
TCP Connections
When a TCP socket probe is defined, Kubernetes tries to open a TCP connection on your container's specified port. If Kubernetes succeeds, the container is considered healthy. TCP probes are helpful when HTTP or command probes are not adequate. Scenarios where containers can benefit from TCP probes include gRPC and FTP services, where the TCP protocol infrastructure already exists.
With the following configuration, kubelet will try to open a socket to your container on the specified port.
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20The above configuration is similar to the HTTP check. It defines a readiness and a liveness probe. When the container starts, kubelet will wait 5 seconds to send the first readiness probe. After that, kubelet will keep checking the container readiness every 10 seconds.
Monitoring Kubernetes health
Probes tell Kubernetes whether your containers are healthy, but they don't tell you anything.
When you have many services running in Kubernetes pods deployed across many nodes, health and error monitoring can be difficult.
As a developer or a DevOps specialist working with the Kubernetes platform, you might find New Relic an excellent tool for checking Kubernetes' health, gathering insights, and troubleshooting container issues.
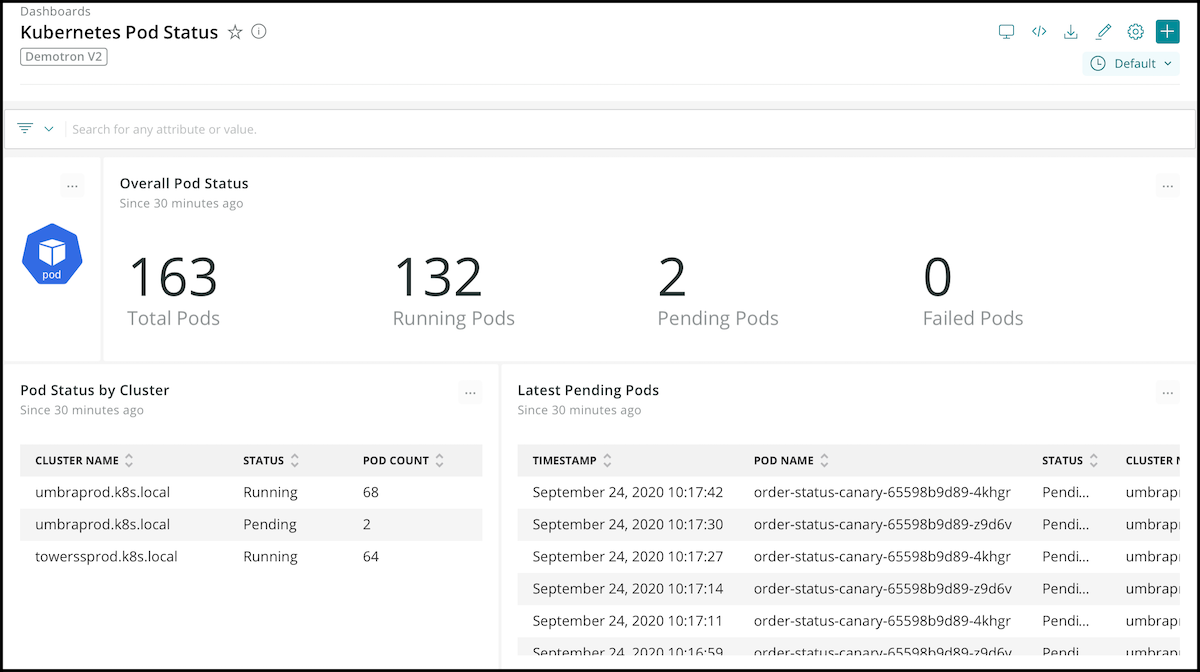
With open instrumentation, connected data, and programmability, the New Relic platform offers full observability of your Kubernetes cluster and the services running in it via metrics, events, logs, and traces.

Wrapping Up
Health checks via probes are essential to ensure that your containers are good citizens in a cluster. Kubernetes uses liveness, readiness, and startup probes to decide when a container needs to be restarted, or a pod needs to be removed from service. That helps you keep your distributed system services reliable and available.
As we've seen, probes are too difficult to set up and use—and now you know how to do it.
Ready for a deep dive into Kubernetes monitoring? Check out A Complete Introduction to Monitoring Kubernetes with New Relic.
Check out the rest of our Kubernetes series here:
Part 1: How to manage cluster capacity
Part 3: How to use Kubernetes secrets
Part 4: How to organize clusters
Part 5: Working with Kubernetes volumes
New Relic is a proud Platinum Sponsor at this year's KubeCon + CloudNativeCon Virtual Conference.
Get started with New Relic.
New Relic is an observability platform that helps you build better software. You can bring in data from any digital source so that you can fully understand how to improve your system.

本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


