Es ist schon kein Leichtes, einen Tech-Stack aufzubauen, der genau auf die Anforderungen eines einzelnen Unternehmens zugeschnitten ist. Wenn es aber um die Konsolidierung zweier Tech-Stacks im Rahmen einer Firmenfusion geht, gestaltet sich die Sache noch komplizierter. 2021 erwarb Dustin, ein führender Online-IT-Partner, das Unternehmen Centralpoint. Ich bin Web Development Manager bei Centralpoint und mein Team wurde mit der Zusammenführung der Tech-Stacks betraut – zweier komplett unterschiedlicher Stacks mit unterschiedlichen Toolsets und Architekturen.
Konsolidierung zweier Tech-Stacks: New Relic und Datadog
Bei der Auswahl der Tools und Verfahren für die Zusammenführung von Tech-Stacks geht es nicht nur darum, welche Technologie besser ist. Teams haben oft starke Vorlieben und Argumente für oder wider ein Tool, die wir wiederum auf Kosteneffektivität und Skalierbarkeit hin bewerten müssen. Zusätzlich mussten wir in diesem Fall die jeweilige Firmenkultur hinsichtlich geschäftlicher Entscheidungen berücksichtigen.
Vor der Übernahme nutzte Centralpoint New Relic für das Monitoring seines cloudnativen Stacks. Von der privaten zur Public Cloud umgestiegen war Centralpoint mit Amazon Web Services (AWS) bereits 2019. Damals wurde im Unternehmen auch das Monitoring von Infrastruktur und Logs ausgeweitet. Dustin wiederum verfügte über einen hochmodernen Anwendungsstack, die Infrastruktur allerdings fußte auf On-Prem-Technologie für Rechenzentren. Die Daten wurden im Haus gehostet und das Infrastruktur-Team hatte die Aufgabe, die Kubernetes-Cluster auf dem neuesten Stand zu halten. Der Tech-Stack bei Dustin befand sich in einer privaten Cloud und die Engineers bauten auf Datadog.
Wir mussten also überlegen, welche Technologien aus den beiden Stacks wir kombinieren sollten, um das optimale Set-up zu erhalten. Letztendlich entschieden wir uns für den Anwendungsstack von Dustin in Kombination mit der Infrastructure-as-Code-Architektur von Centralpoint, womit nur noch die Frage der besten gemeinsamen Observability-Lösung blieb.
Ob die Antwort Datadog oder New Relic lauten sollte, war letztlich eine Frage von Kosten und Nutzen. Bei Dustin wurde Datadog quasi als angereicherter Log-Aggregator zum Parsen von Logs eingesetzt. Bei Centralpoint verwendeten wir New Relic weitaus umfassender. New Relic war bei uns bereits fast acht Jahre lang für Monitoring und Alerting im Einsatz gewesen, und mit unserem Umstieg von der privaten Cloud auf AWS weiteten wir das Einsatzfeld aus. Als wir von Dustin übernommen wurden, hatten wir etablierte und bewährte Verfahren sowohl für Application Performance Monitoring (APM) als auch für Logs.
Schlussendlich fiel die Entscheidung, den gesamten neuen Tech-Stack zu New Relic zu migrieren, einerseits aus Kostengründen, andererseits weil New Relic sich bereits bewährt hatte. Ein weiterer wichtiger Faktor war aber auch die enge Arbeitsbeziehung zwischen New Relic und unseren Engineers mit ständigem Feedback und häufigen Feature-Anfragen. Der Einstieg bei New Relic war dank der umfassenden Dokumentation und der großen, hilfreichen Community einfach. Das Aufwendigste an der ganzen Sache war eigentlich nur, den Entwickler:innen zu zeigen, was mit der Plattform alles möglich ist und welche Toolsets es gibt. Nachdem die Entscheidung gefallen war, konnten wir uns endlich auf die nächste Phase unserer Tech-Evolution konzentrieren.
Der Umstieg aufs DevOps-Modell
Es war uns klar, dass der Tech-Stack nach der Fusion auf einer Public-Cloud-Architektur basieren würde. Im Zuge dieser Umstrukturierung entschieden wir uns auch für ein komplett internes DevOps-Konzept anstelle des Infrastructure-as-a-Service(IaaS)-Modells. Damit das gesamte Team die für DevOps nötige Verantwortung übernehmen konnte, brauchten wir allerdings bessere und umfassendere Informationen.
Eine Firmenakquisition ist immer eine gute Gelegenheit zur Bestandsaufnahme. Welche Ressourcen sind eventuell überflüssig, welche fehlen? In beiden Unternehmen schienen die Logs und Monitoring-Tools entweder zu viele oder nicht die richtigen Daten zu enthalten. Das passiert oft, wenn in einer Firma über eine längere Zeit diverse verschiedene Mitarbeiter:innen mit einem Tool arbeiten. Sobald ein Unternehmen größer wird, muss man sich überlegen, welche Daten angezeigt und welche Benachrichtigungen in der Produktionsumgebung ausgegeben werden sollen. Die Konsolidierung half uns festzulegen, welche Infos wir sehen und umsetzen wollten. Momentan arbeiten wir daran, New Relic genau auf unsere Anforderungen zuzuschneiden, mit dem für unsere Ressourcen passenden Datenvolumen.
Wir beschlossen, New Relic für APM, Browser, Logs und Infrastruktur einzusetzen, um unser DevOps-Modell zu unterstützen. Beim Distributed Tracing werden Service-Anfragen auf ihrem Weg durch das Unternehmen lückenlos nachverfolgt – diese Transparenz war für unsere neuen, effizienteren Geschäftsabläufe unerlässlich. Die Verknüpfung mit AWS und der Versand von Logs von dort an New Relic war dann die logische Konsequenz. Und als Team haben wir uns zum Ziel gesetzt, ein proaktives Mindset zu entwickeln, anstatt bei Engineering und Incident Response nur reaktiv tätig zu sein.
In Apps eingebettete Sicherheit dank Security RX
Wir scannen unsere Apps mit einer Reihe von Tools auf Sicherheitslücken. Eines dieser Tools gab uns die Ergebnisse in PDF-Dateien, die wir dann mit älteren PDFs vergleichen mussten, um Schwankungen zu erkennen. Das war wirklich nicht besonders benutzerfreundlich. Zusätzlich nutzen wir den Container-Scanner in GitLab als festen Bestandteil unserer Pipelines für die Entwicklung. Damit scannen wir die Container, die wir bereitstellen. Diese Container enthalten zum einen die Anwendung, zum anderen aber auch unsere Business Packages mit dem größten Kernelbezug.
Es reicht nicht, die Schwachstellen in einer Anwendung zu kennen – man muss auch wissen, wie sie behoben werden können, also was eventuell entfernt oder korrigiert werden muss. Unsere Strategie für das Sicherheits-Monitoring soll z. B. auch Alerts und Reports umfassen, damit unsere Entwickler:innen verwertbare Daten haben. Und all das soll im selben Monitoring-Tool sein, damit alle auf dieselben Daten zugreifen.
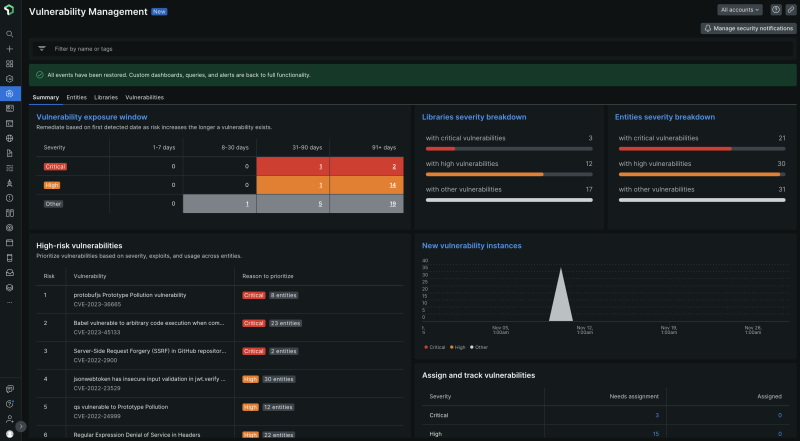
New Relic Security RX liefert uns ohne jeglichen Konfigurationsbedarf wertvolle Sicherheitsinformationen – das ist wirklich eine tolle Sache. Denn ein weiterer Grund, weshalb wir Security als festen Bestandteil eines zentralen Monitoring-Tools haben wollten, ist die Vermeidung einer Alert-Schwemme. Wir wollen sicher sein, dass die Alerts, die ausgegeben werden, auch wirklich korrekt und brauchbar sind.
Security RX hilft uns, den Sicherheitsaspekt von Anfang an in den Entwicklungszyklus zu integrieren, sodass die Teams die Sicherheit in ihren Microsites ebenfalls berücksichtigen. Entwickler:innen können dank Security RX den Sicherheitsstatus ihrer Anwendungen sehen und selbst Verantwortung übernehmen, anstatt Sicherheitsbedenken an das Sicherheitsteam abzuwälzen. Wird eine Feature-Anfrage erfüllt, erhalten wir die Ergebnisse als leicht lesbare Streudiagramme. Entwickler:innen erkennen anhand der Dashboards, ob es Sicherheitsprobleme gibt und ob bei kürzlich aktualisierten Pakete noch Patches ausstehen. Bei eingehender Prüfung kann jede:r die Daten sowie die zu ergreifenden Maßnahmen sehen.
Von DevOps zu DevSecOps
Beim Scannen einer Pipeline mit einem Container-Scanner sieht man normalerweise einen schwarzen Bildschirm mit weißem Text. Wird Ihre Anwendung ohne manuellen Konfigurationsaufwand von New Relic Security RX gescannt, erhalten Sie einen benutzerfreundlichen Überblick für Produktion oder Laufzeit – aber mit diesen Informationen muss dann auch etwas geschehen. Dazu muss sich die Denkweise im Unternehmen ändern. Früher hätte jemand vom Sicherheitsteam anhand der Daten Tickets generiert. Davon möchten wir wegkommen und stattdessen einen agileren Ansatz etablieren, damit die Teams, die eine Anwendung entwickeln, selbst Verantwortung für eventuelle Probleme übernehmen. Dazu muss sich das Mindset im Team zu einer agileren Arbeitsweise hin ändern, sonst helfen auch die besten Tools nichts. Und daran arbeiten wir gerade.
Zukunftspläne
Zukünftig werden wir in unseren Teams noch mehr maßgeschneiderte Dashboards einsetzen. So können wir wichtige Aspekte oder Informationen gezielt berücksichtigen, anstatt planlos in Logs herumzustochern. New Relic Custom-Events werden von unseren Anwendungen ausgegeben und mithilfe von NRQL in Dashboards visualisiert. Das hilft uns, Anwendungsflows schneller zu prüfen und validieren. New Relic Groundskeeper hilft uns, die Anwendungsabhängigkeiten und Pakete im Griff zu behalten.
Die Kubernetes-Übersicht ist die effektivste Möglichkeit zur raschen Beurteilung der Health unserer Cluster und Deployments.

Die in diesem Blog geäußerten Ansichten sind die des Autors und spiegeln nicht unbedingt die Ansichten von New Relic wider. Alle vom Autor angebotenen Lösungen sind umgebungsspezifisch und nicht Teil der kommerziellen Lösungen oder des Supports von New Relic. Bitte besuchen Sie uns exklusiv im Explorers Hub (support.newrelic.com) für Fragen und Unterstützung zu diesem Blogbeitrag. Dieser Blog kann Links zu Inhalten auf Websites Dritter enthalten. Durch die Bereitstellung solcher Links übernimmt, garantiert, genehmigt oder billigt New Relic die auf diesen Websites verfügbaren Informationen, Ansichten oder Produkte nicht.


