サーバー監視とは?目的やツールの選び方、効率化の方法を解説
現代のシステム運用において、サーバー監視はサービスの安定稼働に不可欠な業務です。
システム停止やパフォーマンス低下は、サービス提供やビジネスに重大な影響を与えるため、サーバーの稼働状況を常に把握し、適切に保守する必要があります。
また、クラウドネイティブやマイクロサービスの普及により、監視対象の構成や範囲はますます複雑になっており、従来の監視では不十分なケースも少なくありません。
ここでは、サーバー監視の目的や代表的な監視項目のほか、ツール選定のポイント、現代の監視におけるオブザーバビリティの重要性について解説します。
サーバー監視とは、サーバーの稼働状況を常時確認し、異常の兆候を早期に検知・対処すること
サーバー監視とは、文字通り「サーバーの稼働状況を監視すること」であり、システム運用の根幹を支える重要な業務です。サーバーの稼働状況や状態を継続的にチェックして、異常の予兆を把握し、障害発生時には迅速に対応することを指します。
もしもサーバー監視を怠れば、障害やサイバー攻撃によってサービス停止や情報漏えいが発生し、ユーザーや取引先の信頼を失うリスクが生じます。だからこそ、サーバーの状態を常に把握し、安定稼働を支えるための運用・保守が欠かせません。
さらにサーバーは、OSやアプリケーション、ミドルウェア、ハードウェアなどの複数の構成要素から成り立っており、それぞれの要素が正常に動作しているかを個別に監視する必要があります。
このような複雑な監視業務を支えるのが「監視ツール」と呼ばれるソフトウェアです。近年ではクラウドやコンテナなど、動的に変化する環境に対応できる監視ツールの導入が求められています。
サーバー監視の目的
サーバー監視の主な目的は、「障害の予防と早期検知」と「障害発生時の迅速な原因特定と対応」に分けられます。それぞれについて詳しく見ていきましょう。
障害の予防と早期検知
サーバー監視の目的は、障害を早期に検知し、大きなトラブルを未然に防ぐことです。
例えば、CPUやメモリなどのリソース関連を常に監視することで、過負荷や障害の予兆を見逃さず、サービス停止といった重大トラブルを未然に防げます。
特に近年では、オンプレミス環境に加えて、クラウド環境の活用が進み、システム構成が動的に変化するケースも少なくありません。
そのため、リアルタイムで異常を検知する必要性がいっそう高まっています。
障害発生時の迅速な原因特定と対応
万が一、サーバーに障害が発生した場合、最優先すべきは原因の迅速な特定と早期復旧です。そのためには、日常的に蓄積されるログや稼働データの活用が欠かせません。
これらのデータを活用することで、いつ、何が、どの要素に影響を与えたのかをスピーディーに分析し、最適な復旧手段を講じることが可能になります。
ただし、すべての異常を通知対象とすると、現場の負担が大きくなりかねません。
実効性の高い運用を行うには、サービス提供に直結するアプリケーションや、ユーザー体験に関わる異常を重点的に監視することが不可欠です。
サーバーの監視項目
サーバー監視では、対象とするシステムの構成や目的に応じて、監視項目が異なります。
基本的には、リソース使用状況やログ、ネットワークトラフィック、サービス稼働状況などが主な対象です。これらを組み合わせて統合的に把握すれば、異常の兆候を早期に検知し、影響範囲を最小限に抑えることが可能です。
また、監視の対象はオンプレミスとクラウド環境で異なる傾向があります。
オンプレミスでは、物理サーバーやハードウェアを含めた包括的な監視が求められますが、クラウド環境では、仮想リソースやコンテナ、マネージドサービスといった動的な要素をリアルタイムで可視化することが重視されます。
特にクラウド環境では、リソースの利用状況がコストに直結するため、稼働状況を正確に把握し、必要なタイミングでスケーリングする仕組みが重要です。
主な監視項目とクラウド特有の監視項目については、下記のとおりです。
■主な監視項目
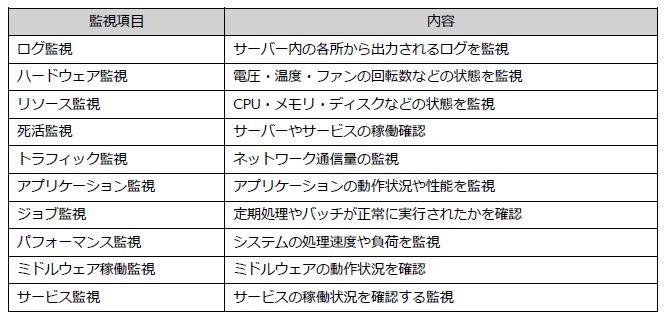
■クラウド特有の監視項目

なお、ここで挙げたすべての監視項目を、同じレベルで一律に監視すればよいというわけではありません。監視対象は、システムの構成やユーザーへの影響の有無に応じて、優先度をつけて柔軟に選定することをおすすめします。
現代におけるサーバー監視の課題
従来のサーバー監視は、CPUやメモリの使用率、ログの異常検知など、主に機器やシステムの状態を定量的にチェックするものでした。
しかし現在では、オンプレミスからクラウド、さらにはマイクロサービスやコンテナベースのアーキテクチャへと進化したことにより、一部のコンポーネントに障害が発生しても、サービス全体は継続できるように設計されているのが一般的です。
そのため、CPUやメモリといった個別のリソースだけでなく、サービス全体の正常性を把握する視点が重要です。
例えば、表示速度の低下や特定操作でのタイムアウトなど、ユーザーにとっての不具合が発生していても、システム的には「異常なし」と判断されることがあります。
また、分散システムでは、1台のサーバーの不調がほかのコンポーネントに波及し、サービス全体に影響を及ぼすことも少なくありません。
こうした相関関係や依存関係は、従来の監視手法だけで捉えきるのは困難です。
加えて、従来はあらゆる事象にアラートを発生させる運用が主流でしたが、この方法では情報が氾濫し、重要な通知が埋もれる「アラート疲れ」を招きかねません。
さらに、ログ監視に頼る運用では、出力漏れや粒度の粗さ、リアルタイム性の欠如といった課題により、異常の見落としや原因特定の遅れが生じるリスクがあります。また、ログだけではユーザー体験の劣化を直接把握することは困難です。
これらの課題を解決するには、サービス全体の構造やユーザーへの影響をふまえた監視設計が必要です。「通知が来たかどうか」ではなく、「サービスに実害が生じているかどうか」を基準に判断する視点こそが、現代のサーバー監視に必要不可欠です。
監視ツールを選ぶ際のポイント
サーバー監視を効果的に行うためには、自社の運用方針や環境に合った監視ツールを選定することが必要です。監視ツールを選ぶ際に確認すべき主なポイントは、以下のとおりです。
<監視ツールを選ぶ際に確認すべき主なポイント>
監視対象と導入方法
まず重要なのは、監視ツールが自社の監視対象(サーバー、クラウド、アプリケーションなど)に対応しているかどうかです。オンプレミスだけでなくクラウドやコンテナなども監視対象に含めたい場合は、それらに対応した機能があるかを事前に確認しましょう。
また、導入方法も重要です。例えば、個々の監視対象にデータ収集用のアプリケーションを組み込む「エージェント型」は、初期設定の手間と運用負荷はかかるものの、詳細な状態把握ができます。
一方、「エージェントレス型」は標準プロトコルを用いて監視対象からデータを吸い上げるため、導入の手間がかかりません。しかし、取得できる情報に制限が生じるケースもあるため、注意が必要です。
現場の運用体制や技術リソースに合わせて、適切な方式を選ぶことがポイントです。
コストと拡張性
監視ツールの導入には、初期費用やライセンス費用、月額利用料などのコストが発生します。自社の予算に合うかはもちろん、今後のスケールアップやシステム変更にも柔軟に対応できるか、拡張性の観点も確認することをおすすめします。
例えば、オープンソースの監視ツールは初期費用が抑えられる反面、トラブル発生や機能拡張は、自社で対応しなければなりません。
一方、商用ツールは継続的なコストがかかりますが、手厚いサポートと高機能が魅力です。
通知機能
異常を検知した際に、リアルタイムで通知を受け取れるかどうかは非常に重要です。メールやチャットツール、プッシュ通知などへの通知に対応しているかを確認しましょう。
ただし、通知のリアルタイム性ばかりを重視すると、アラート疲れを引き起こす可能性もあります。
それを避けるには、しきい値や継続時間、外れ値検知といった判定条件を適切に設定し、誤検知や不要な通知を減らす工夫が求められます。
操作性と可視化
監視ツールは日々の運用で使うものだからこそ、直感的に操作できるUIであることが望まれます。ダッシュボードで全体状況を一目で把握できる設計や、グラフによる視覚的な表示、必要な情報へすぐにアクセスできるナビゲーション性など、実際の操作感にも注目しましょう。
特に、複数の監視項目をまとめて可視化し、異常の関連性を分析できる機能は、障害対応の迅速化に大きく寄与します。
無料版やデモ版があれば、事前に試用してみて、操作性を確認するのがおすすめです。
外部ツールとの連携機能
監視ツールを選ぶ際は、外部のツールと容易に連携できるかもチェックすべき項目です。システムの規模や運用体制によっては、インシデント管理ツールやチケットシステム、自動復旧スクリプトなどと連携することで、より強力な運用基盤を構築できます。
例えば、異常を検知したら対応タスクを自動発行したり、あらかじめ定義された手順を自動実行できたりする製品もあります。
このような連携機能が充実していれば、人的対応の手間を大幅に削減でき、運用効率の向上につながります。
オブザーバビリティの重要性
システム構成の複雑化と、ユーザー体験を重視した運用へシフトした現代の監視において、注目されているのが、「オブザーバビリティ」という考え方です。
オブザーバビリティとは「可観測性」と訳される言葉です。システム全体がどのような状態にあるかを常に観測し、必要な情報を収集する指標あるいは仕組みを指します。システム内の情報を関連づけて分析することで、異常が起こった際に迅速な原因の追求、解決が可能です。
ただし、オブザーバビリティは単にツールを導入すれば完結するものではありません。組織として、システム構成やアーキテクチャ、運用体制を見直し、観測データを活用して継続的に改善するための意識改革が求められます。
オブザーバビリティと監視の違いについては、下記の記事をご覧ください。
オブザーバビリティとは?監視との違い、必要性について解説
https://newrelic.com/jp/blog/best-practices/what-is-observability-difference-from-monitoring
より高度な監視を目指すならNew Relicがおすすめ
サービス全体の可用性やユーザー体験を重視した、より高度な監視を実現するためにおすすめなのが、オブザーバビリティ・プラットフォーム「New Relic」です。
New Relicは、インフラからアプリケーション、ユーザー体験までを包括的に可視化できるSaaS型の監視・分析ツールです。
複雑化する現代のIT環境に対応する多彩な機能を備えており、主な特徴は下記のとおりです。
<New Relicの主な特徴>
サービス全体を可視化できる
New Relicは、オンプレミスでもクラウドが混在する環境においても、インフラ、アプリケーション、ネットワーク、さらにはエンドユーザーの体験までを一元的に可視化できます。
これにより、リソースの稼働状況やエラー情報だけでなく、サービス全体の健全性を把握し、システムの変化がビジネスに与える影響までを把握することが可能です。
障害の原因を迅速に特定できる
New Relicなら、複雑なクラウド環境であっても、稼働中の各コンポーネント間の依存関連を含めて可視化できるため、障害発生時にその原因を迅速かつ的確に特定できます。
従来の監視では、異常のアラートが出ても「本当に問題が発生しているのか」が不明確なまま、システムログや過去の監視記録を手作業で確認しながら対応するなど、属人的な運用に頼らざるを得ないケースも少なくありませんでした。
New Relicを活用すれば、リアルタイムに状況を把握し、迅速かつ的確な障害対応が可能になります。
外形監視・リアルユーザーモニタリングができる
New Relicの大きな強みのひとつが、外形監視とリアルユーザーモニタリングの両方に対応している点です。
外形監視は、事前に設定したシナリオに従い、ロボットがシステムにアクセスしてサービスの利用状況をテストする機能です。この機能により、アプリケーションの応答や可用性を定量的に評価できます。
一方、リアルユーザーモニタリングは、実際のユーザーがサービスを利用した際の操作や、それに対するブラウザ側でのシステムの反応を可視化する機能です。地域別のレスポンス時間やブラウザごとのエラー発生状況なども把握でき、ユーザーごとの体験の違いを見逃さず、きめ細かな対応につなげることが可能になります。
外形監視については、下記の記事をご覧ください。
外形監視とは?内部監視との違いや、安定運用のための方法を紹介
https://newrelic.com/jp/blog/best-practices/what-is-synthetics
アラート機能が柔軟で、迅速な対応を支援できる
New Relicでは、異常検知に関するしきい値やルールを柔軟に設定できます。検知結果は、メールのほか、Webhook連携を通じてSlackなどのツールにリアルタイムで通知することも可能です。
さらに、条件付き通知やアラートをまとめて管理できるグルーピング機能も備えており、誤検知や通知過多を防ぎながら、必要な情報を確実に届けられます。
ダッシュボードで状況を直感的に把握できる
複数の監視対象を統合し、ダッシュボードで視覚的に表現できるインターフェースを備えている点も、New Relicの大きな特徴のひとつです。重要なKPIやエラー情報、稼働状況などをグラフやウィジェットで直感的に表示できるため、異常の傾向や改善ポイントも一目で把握できます。
ダッシュボード上で何らかの変化を確認した際は、すぐに該当箇所の詳細情報にアクセスが可能です。
安定したサービスの提供のために、New Relicで確実な監視体制を築こう
デジタルサービスがビジネスの中核を担う現在、サービス品質の低下が直接的なビジネス損失につながります。だからこそ、信頼性の高い監視体制と、障害への迅速な対応は不可欠です。
併せて、エンジニア一人ひとりが「サービス品質を守り、高めることでビジネスに貢献する」という意識を持つことも重要です。
エンジニアの本質的な役割は、単にサーバーの状態を監視したり、通知に対応したりすることだけではありません。通知はあくまでスタート地点であり、そこから観測データをもとに状況を分析し、「何が起きていて、どこに影響が出ているのか」「それがビジネスにどう影響するのか」を見極めて改善することが求められます。
こうした姿勢は、単なる運用作業者から、サービス全体を俯瞰しながら改善に取り組む「サービス責任者の視点」へのマインドシフトを意味します。
New Relicは、単なる監視ツールではなく、俯瞰的な判断を支援するツールです。サービス全体を一元的に可視化し、意味のあるアラートをきっかけに、適切な判断と迅速な対応へとつなげる土台を提供します。
サーバー監視を超え、「サービス品質とユーザー体験を守る包括的な可視化」を目指す企業にとって、New Relicは最適なパートナーとなるでしょう。この機会にぜひ一度、New Relicの導入をご検討ください。

次のステップ
- まだNew Relicをお使いではありませんか? New Relicでは、無料でお使いいただける無料サインアップをご用意しています。 無料プランは、毎月100GBの無料データ取込み、1名の無料フルプラットフォームユーザー、および無制限の無料ベーシックユーザーが含まれています。
無料サインアップはこちらから

本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


