MTTRとは?サービス障害時に押さえるべき改善アプローチを解説
サービスの中断やシステム障害は、ユーザー体験や事業継続に大きな影響を与えます。その復旧スピードを評価する指標として注目されているのが、MTTRです。
MTTRは単なる平均時間ではなく、対応プロセスの質や組織の復旧力を測る重要な指標として企業で取り入れられています。信頼性の高いサービス運用を目指すなら、MTTRを正しく理解し、改善に活かすことが必要です。
ここでは、MTTRの考え方や計算方法、関連指標との違い、そしてMTTRを短縮するための実践的なアプローチについて解説します。
MTTRとは、サービスやシステムに障害が発生してから復旧するまでにかかる平均時間
MTTR(Mean Time To Recovery)とは、サービスやシステムに障害が発生してから復旧するまでにかかる平均時間を指します。
一般的に「平均復旧時間」と訳され、システムの可用性や信頼性を測るための基本的な指標とされています。
MTTRは、製造ラインなどの機械故障にも広く使われており、文脈によっては「Mean Time To Repair」と定義されることもありますが、本記事ではITシステム運用に焦点を当て、復旧ベースで解説します。
現代におけるIT運用やサービス提供の現場では、MTTRは、従来のような「ハードウェアの修復時間」ではなく、「ユーザー視点に立ったサービス復旧時間」として捉えられることが一般的です。
ユーザーへの影響を最小限に抑え、どれだけ早く通常のサービス提供に戻せるかが問われます。
そのため、MTTRを評価する際は、個々のコンポーネントに着目するのではなく、システム全体が必要なサービスレベルを満たしているかを把握することが重要です。
なお、SREやDevOpsチームにおいては、MTTRは対応プロセスの効率性や組織の復旧力を測る客観的な指標として活用されています。
障害対応の振り返りや、プロセス改善の判断材料としても欠かせない指標といえるでしょう。
SREについては、下記の記事をご覧ください。
SREとは?DevOpsとの違いや、実践で誤解しがちなポイントを解説
https://newrelic.com/jp/blog/best-practices/what-is-sre
MTTRの計算方法
ここでは、MTTRの基本的な計算式と、正確に算出するために必要なデータの種類について解説します。
MTTRの計算式
MTTRの計算式は非常にシンプルです。特定期間内に発生した復旧対応の総時間を、その期間中の復旧件数で割ることで求められます。
<MTTRの計算式>
MTTR=復旧にかかった合計時間÷復旧件数
例えば、1週間に3件の障害が発生し、それぞれの復旧に2時間、1.5時間、2.5時間かかった場合、合計時間は6時間、復旧件数は3件となるため、この1週間のMTTRは「6÷3=2時間」となります。
単位としては「時間(h)」または「分(min)」が一般的です。
MTTRの測定に必要なデータ
MTTRを測定するには、インシデント発生から復旧完了までのそれぞれのタイミングを記録する必要があります。
例えば、「発生時刻」「検知時刻」「対応開始時刻」「復旧時刻」などのタイムスタンプに加え、対応履歴や関連ログなども重要なデータです。
どの段階に時間がかかっているかを把握できれば、改善にもつなげやすくなるでしょう。
MTTRと関連する指標・概念
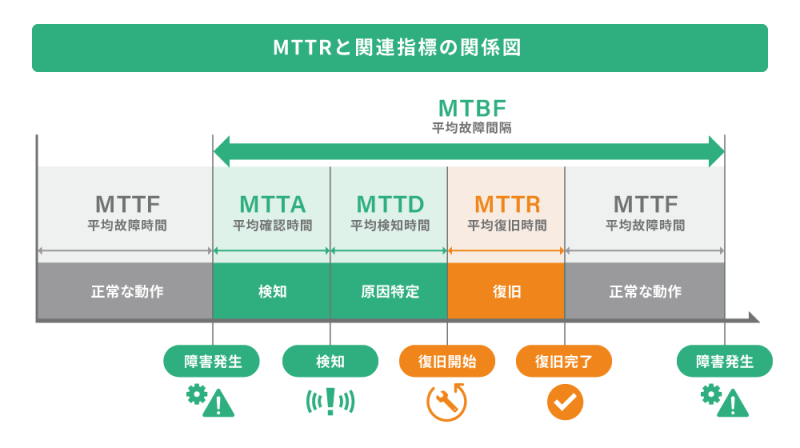
MTTRは単体でも有用な指標ですが、インシデント対応全体を正しく把握・改善するためには、ほかの関連指標と併せて活用することが重要です。
ここでは、MTTRと密接に関係する代表的な指標について解説します。
<MTTRと密接に関係する代表的な指標>
MTTD(平均検知時間)
MTTD(Mean Time to Detect)とは、障害や異常が発生してから、それを検知するまでにかかる平均時間を示す指標です。
検知が遅れると対応開始も遅れ、結果としてMTTRが長引き、ユーザーへの影響が拡大します。反対に、素早い検知は復旧の迅速化につながります。
MTTDを短縮するには、監視ツールの導入やログ分析の自動化、リアルタイムアラートの整備が有効です
MTTA(平均確認時間)
MTTA(Mean Time to Acknowledge)とは、障害や異常の検知から、担当者がそれに気づき、対応を開始するまでの平均時間を示す指標です。
アラートへの初動の早さを測る指標で、MTTRを左右する重要な要素です。検知が速くても、対応開始が遅れれば復旧は遅れます。
MTTAを短縮するには、アラートの信頼性向上や通知経路の最適化、当番体制の整備、ノイズの削減などが有効です。
MTBF(平均故障間隔)
MTBF(Mean Time Between Failures)とは、システムや機器が故障せずに正常稼働し続ける平均時間を示す指標です。
MTTRが「復旧にかかる時間」なら、MTBFは「どのくらい故障が起きにくいか」を測る指標です。ITサービスでは、「サービスに影響を与える障害」を故障と見なし、MTBFを算出します。
たとえMTTRが短くても、故障が頻発すれば信頼性は低く評価されます。MTTRとMTBFを合わせて評価することで、システム全体の可用性が明確になります。
MTBFを高めるには、設計品質の向上や予兆検知、予防保守などが有効です。
MTTF(平均故障時間)
MTTF(Mean Time To Failure)とは、修復できない製品や部品が故障せずに正常に稼働し続けるまでの平均時間を示す指標です。
主に使い切り型のハードウェアや消耗品などに使われ、故障後は修復ではなく交換が前提となるケースで用いられます。
MTTFは、計画的な交換スケジュールや在庫管理の最適化に役立ちます。また、MTTRやMTBFと並び、システム全体の信頼性評価として重要です。
システム稼働率
システムの稼働率は、特定の期間における機器やサービスの稼働効率を表す指標です。具体的には、以下の式で求められます。
<システム稼働率の計算式>
システム稼働率=MTBF÷(MTBF+MTTR)
例えば、システム稼働率が95%であれば、全体の5%の時間は故障やメンテナンスなどで停止していたことを意味し、改善の余地があると判断される場合があります。
稼働率を高めるには、MTTRの短縮だけでなく、MTBFの延長も重要です。
信頼性の高い設計、予防保守、監視体制の強化などを組み合わせることで、稼働率の向上が期待できます。
MTTRを短縮するメリット
MTTRを短縮することで得られる具体的なメリットについて解説します。代表的なメリットは次の4つです。
<MTTRを短縮するメリット>
顧客満足度・信頼性の向上
MTTRの短縮は、ユーザー体験の向上とサービスへの信頼確保に直結します。
復旧対応が早いほど、「信頼できるサービス」としての印象が高まり、継続利用や契約更新にもつながります。
また、SLAやSLOの達成にも貢献し、安定した運用の指標としても重要です。
生産性の向上
MTTRを短縮することで、システム停止時間を最小限に抑え、業務全体の生産性向上につながります。
障害対応にかかる時間が減れば、開発・運用チームは本来の業務や価値創出に集中でき、組織の効率が高まるでしょう。
併せて、対応手順の標準化や属人化の解消も進み、組織全体の効率向上につながります。
コスト効率化
MTTRの短縮は、障害対応にかかる工数やリソースの削減につながることもメリットです。
復旧時間を可視化することで、無駄な対応やボトルネックを特定し、プロセスの最適化や再発防止が進みます。
結果として、緊急対応の頻度が減り、予算や人材面での負担軽減にも効果があります。
プロセス改善
MTTRの継続的な短縮は、復旧対応だけでなく、組織全体の運用プロセスの改善にもつながります。
各対応ステップの明文化やSLOに沿った運用により、ミスや遅れを防ぎ、品質向上も期待できます。
さらに、復旧プロセスの見直しは、BCP(事業継続計画)やDR(災害復旧)などのリスク対策とも連動し、持続的なサービス提供体制の強化にもつながるでしょう。
MTTR短縮のためのアプローチ
MTTRを短縮するには、単に復旧のスピードを上げるだけでは不十分です。ここでは、MTTR短縮を実現するために有効なアプローチを、具体的な視点から解説していきます。
<MTTR短縮を実現するために有効なアプローチ>
サービスリカバリーへの視点転換
MTTRを効果的に短縮するには、「障害を復旧する」視点から、「サービスを早く回復させる」視点への転換が必要です。
従来のように機器やシステム単位での復旧完了をゴールとするのではなく、ユーザーへの影響が最小限になり、通常のサービス提供が再開された時点を「復旧完了」と定義することが求められます。
この視点の転換は、復旧プロセス全体の優先順位や判断基準にも影響します。
例えば、一部の内部機能が復旧していなくても、ユーザーに影響がなければサービスは提供可能と判断し、優先度の高い領域から順に対応を進めるといった柔軟な判断が可能です。
この考え方は、SREやDevOpsの文化とも親和性が高く、真に価値ある復旧体制の実現につながります。
ツール活用による自動化と連携
正確なMTTRの把握と改善には、インシデントの発生から復旧までの各フェーズをリアルタイムで追跡・分析できる体制が必要です。
ツールを活用すれば、異常検知からアラート通知、エスカレーションまでを自動化し、対応情報も一元管理できます。
属人化を防ぎつつ、検知から復旧までの各フェーズを可視化・計測することで、改善に向けた判断がしやすくなります。
根本原因の分析と再発防止の徹底
MTTRを継続的に短縮するには、復旧後の原因分析と再発防止の徹底が欠かせません。
障害の原因だけでなく、対応が遅れた理由も振り返り、ボトルネックや手順の課題を特定・改善していく必要があります。
可視化されたデータを活用し、チーム全体で改善策を共有することで、再発防止と運用力の底上げが可能になります。
ナレッジ共有と組織学習の仕組み化
MTTRを持続的に改善していくためには、対応のノウハウや学びを組織に蓄積し、チーム内で共有する体制が必要になります。
特定の担当者に依存する属人化を排除し、誰でも迅速かつ適切に対応できるようにするためには、ナレッジベースの整備や教育プログラムの実施が効果的です。
また、障害対応後に必ず振り返りを行い、得られた教訓をドキュメント化することも大切です。このような学習サイクルを組織に組み込むことで、属人化しない強固な復旧体制を築くことができます。
MTTRに関する注意点
MTTRは復旧スピードを測る上で有用な指標ですが、正しく活用するには数値の性質や文脈を踏まえた慎重な評価が欠かせません。
ここでは、MTTRの解釈や運用において見落とされがちな3つの注意点を解説します。
<MTTRに関する注意点>
MTTRの数値は正しく読み解くのが困難
MTTRは「平均値」であるため、数値だけで評価すると実態を正確に反映しないことがあります。
特に、障害件数が少ない期間や、極端に長時間かかった事例が含まれると、平均が大きく引き上げられ、実態よりも悪い数値になることも少なくありません。
また、軽微な障害が頻発する場合と、重大な障害がまれに発生する場合では、必要なリソースや影響範囲が大きく異なります。それでも同じMTTRとして扱ってしまうと、誤った判断につながるおそれもあります。
そのため、数値そのものよりも、そこに隠れた分布の傾向が重要です。
件数の分布・最大最小値・標準偏差といった統計情報に加え、インシデントの重大度や影響範囲といった文脈も踏まえて評価することが重要です。
MTTRを補完する他指標との併用が重要
MTTRは復旧時間を示す有用な指標ですが、それだけでは障害対応の全体像を把握するには不十分です。
例えば、MTTRが短くても障害が頻発すれば「不安定なサービス」と見なされる一方、発生頻度が低くても復旧に時間がかかれば信頼性を損なう要因になります。
こうしたバランスを正しく評価するには、MTBFやMTTFといった指標との併用が不可欠です。さらに、MTTDやMTTAなど前段階の指標も併せて見ることで、どのフェーズに課題があるのかを明確にできます。
加えて、数値だけでなく、ユーザーへの影響度や障害の優先度も考慮することで、実態に即した判断が可能になります。
複数の指標と文脈を併せて評価することが、MTTRの本質的な改善と、信頼性の高い運用体制の構築につながるでしょう。
自社のサービスレベル(SLA/SLO)に対するMTTRの適正性
MTTRを評価・改善する上で見落としがちなのが、「その数値が自社のサービスレベルに対して適切かどうか」という視点です。
例えば、SLAやSLOで「障害発生から1時間以内に復旧」と定めている場合、その目標に対してMTTRが上回っているか下回っているかを定期的に確認する必要があります。
仮に、MTTRが短く見えても、SLOを達成できていなければ、ユーザーへの影響や契約違反につながるリスクが高まります。反対に、MTTRがSLOを安定的に下回っていれば、復旧体制が信頼できるものであることを示す根拠にもなるでしょう。
このように、MTTRは単なる性能評価ではなく、SLA/SLOとの整合性を前提とした「運用品質の達成度」を測る指標として活用すべきなのです。
失敗を許容する組織文化が必要
MTTRを本質的に短縮するには、ツールや自動化だけでなく、「失敗を責めず、学びを共有する」組織文化が重要です。
個人の責任を追及する文化では、担当者が報告をためらい、情報共有が遅れることで、結果としてMTTRが悪化しがちです。一方で、失敗を許容する文化は心理的安全性を高め、迅速な報告を促すことで、本質的な原因究明や再発防止につながります。
また、開発と運用が日常的に連携し、現場で自律的に判断できる体制があることも、MTTR短縮に大きく寄与します。
MTTR改善にはオブザーバビリティの整備が不可欠
MTTRを本質的に改善するには、オブザーバビリティ(Observability)の整備が欠かせません。
オブザーバビリティとは、システムに異常が発生した際に、「どこで」「なぜ」問題が起こったのかを把握する能力を指し、単なる通知ではなく、原因の特定と復旧を支える仕組みです。
この仕組みがあることで、異常の兆候を早期に察知し、原因や影響範囲を迅速に特定できます。さらに、可視化されたデータをもとに復旧プロセスを継続的に改善できるため、過去の傾向やボトルネックを分析し、フローの見直しにもつなげられます。その結果、ダウンタイムの大幅な削減にもつながるのです。
実際に、New Relicの「2024年版オブザーバビリティ予測レポート」では、フルスタックオブザーバビリティを実現している組織は、そうでない組織に比べて、年間ダウンタイムが79%短縮されていると報告されています。
さらに、DevOpsの分野ではGoogleのDORAチームが提唱する「デプロイ頻度・変更リードタイム・MTTR・変更障害率」の4つの指標が業界標準となっており、スピードと安定性の両立が求められています。
オブザーバビリティはMTTR(安定性)の改善だけでなく、デリバリーの速度や変更の品質向上にも効果的です。
MTTRへの取り組みをデプロイ頻度やリードタイムといったスピード指標と合わせて継続的に評価することで、組織全体のパフォーマンス最大化につながるでしょう。
オブザーバビリティについては、下記の記事をご覧ください。
オブザーバビリティとは?監視との違い、必要性について解説
https://newrelic.com/jp/blog/best-practices/what-is-observability-difference-from-monitoring
2024年オブザーバビリティ予測レポートについては、下記よりダウンロードください。
2024年オブザーバビリティ予測レポート
https://newrelic.com/jp/resources/white-papers/observability-forecast-report-2024
MTTR改善のライフサイクルを加速するNew Relicの強み
MTTRの改善は、単一の施策で達成できるものではありません。検知、診断、復旧、振り返りというインシデント対応のライフサイクル全体を、いかに高速で回していくかがカギとなります。
New Relicは、この一連の流れを一気通貫で支援する統合型オブザーバビリティ・プラットフォームとして、多くのSREや運用チームに選ばれています。
マイクロサービスや分散アーキテクチャなど複雑なシステムでも、アプリケーション、インフラ、ネットワーク、ユーザー体験などの多層的なデータをリアルタイムで収集・統合できる点が大きな特徴です。
<New Relicの主な強み>
・検知の高速化:AIOpsによるアラートの相関分析でノイズを削減し、初動を迅速化
・診断の効率化:アプリ・インフラ・ログなどを統合し、単一の画面で根本原因を特定
・復旧の質向上:SLOと連携し、ユーザー影響を踏まえた復旧判断が可能
さらに、New Relicは、単なるツールにとどまらず、MTTR短縮に必要な学びを共有する文化を支える基盤としても機能します。
インシデント発生時に、「何が起きたのか」をチーム全体がデータにもとづいて振り返ることで、継続的な改善と健全な組織文化の醸成につながります。
安定したサービス運用と継続的な改善を目指すなら、New Relicの導入をぜひご検討ください。

次のステップ
- まだNew Relicをお使いではありませんか? New Relicでは、無料でお使いいただける無料サインアップをご用意しています。 無料プランは、毎月100GBの無料データ取込み、1名の無料フルプラットフォームユーザー、および無制限の無料ベーシックユーザーが含まれています。
無料サインアップはこちらから

本ブログに掲載されている見解は著者に所属するものであり、必ずしも New Relic 株式会社の公式見解であるわけではありません。また、本ブログには、外部サイトにアクセスするリンクが含まれる場合があります。それらリンク先の内容について、New Relic がいかなる保証も提供することはありません。


