Innovation mit moderner Software
Noch nie war die Entwicklung von Software dermaßen erfolgsversprechend – so der einhellige SaaS-Tenor. Cloud, Microservices, Container: Neue Technologien sorgen für mehr Skalierbarkeit und Effizienz. DevOps, CI/CD, Automatisierung: Ihre Entwickler sind nun agiler und überwinden so auch Innovationsschwellen rascher.
So viel zur Theorie.
In der Praxis gestaltet sich all dies aber wohl ein wenig anders. Ihr IT-Team hat nun also Cloud- Modernisierung und -Deployment mit Tempo skaliert. Ihren IT-Stack hat es dabei aber ebenso rasch auf eine neue Komplexitätsebene gehievt. Somit gibt es nun auch eine Vielzahl neuer Komponenten, für die es Monitoring zu implementieren gilt:
- Hybride Umgebungen mit verschiedenen Cloud-Anbietern
- Ihre über eine viel größere Fläche gespannte Tech-Landschaft mit unterschiedlichsten Telemetriedaten
- Häufigere Software-Änderungen – mehr und mehr Unternehmen berichten von Dutzenden Deployments pro Woche
- Verteilte Teams, deren Deployment- und Innovations-Agilität von der Transparenz für verschiedene Stack-Bereiche abhängt – auch denen anderer Teams
- Immer neue Monitoring-Tools, die neue Entwickler ganz selbstverständlich mitbringen und deren absolute Notwendigkeit sie leidenschaftlich und mit Nachdruck vertreten
Ergo: Während Ihre Tooling-Landschaft munter weiterwächst und an Komplexität gewinnt, wird es proportional immer wichtiger, Ihr gesamtes Software-System mit vollständigem Kontext und korrelierten Daten überblicken zu können. Und falls nicht? Nun, dann wird Ihnen kaum etwas anderes übrig bleiben, als jedes Software-Unternehmen, das Ihnen sein „Noch nie war die Entwicklung von Software dermaßen erfolgsversprechend“-Mantra entgegensäuselt, mit einem Fluch zu belegen. Ohne qualifizierte Geisterbeschwörung mindestens genauso aufwändig. Und auch dann immer noch keine Lösung für Ihr eigentliches Problem.
Die weitaus zielorientiertere Alternative finden Sie in diesem Whitepaper: Wir betrachten die Herausforderungen, die eine fragmentierte Tooling-Landschaft mit sich bringt, im Detail. Weiter zeigen wir Ihnen, wie eine moderne Monitoring-Methodik und End-to-End-Observability das Komplexitäts-Ungetier in Ihrem Stack zähmen.
Tool-Fragmentierung: Ein allgegenwärtiges Phänomen
Um komplexen Infrastrukturen beizukommen, setzen Unternehmen für gewöhnlich auf Masse. Masse in Form von Monitoring-Tools. Immer mehr, open source wie proprietär, mit Einführung in immer kürzeren Abständen. Im Durchschnitts-Stack finden sich so nunmehr dutzende vergleichbare Tools, die verschiedene Teams für unterschiedliche Bereiche zum Einsatz bringen. Entgegen aller Erwartungen sorgen sie aber nicht für mehr Innovationspotenzial, schnellere Problemerkennung und -behebung, sondern eine ganze Flutwelle neuer Herausforderungen:
- Datensilos und in der Folge blinde Flecken
- Unproduktiv investiertes Hin- und Herwechseln zwischen einzelnen Tools, die in der Fehlerbehebung wertvolle Zeit kostet
- Mangelnde Datenkorrelation zwischen komplett zusammenhangslosen Toolsets
- Unnötig hohe MTTD und MTTR
- Isolierte, schlecht skalierbare Punktlösungen
- Lizenz- und Kostenredundanzen ohne Mehrwert und gleichzeitig unzureichende Transparenz über Deployments und Systeme hinweg
- Versteckte Kosten im Zusammenhang mit der Verwaltung von Open-Source-Tools
Eigentliche Zielsetzung und Status quo stehen sich so teils recht diametral gegenüber. Dies ist umso bedauerlicher, denn eine Monitoring-Methodik, die mehr Stückwerk als Strategie ist, kann mit den Erwartungen Ihrer Kunden an Produkt- und Service-Erlebnisse kaum mithalten. Eine fragmentierte Tooling-Landschaft macht Observability schlicht und ergreifend unmöglich.
Die Konsequenzen dieser Problemstellung erstrecken sich weit über die Reichweite der Technologie. Dafür muss man sich nur nochmals kurz die eigentlichen Gründe für die Einführung all dieser neuen Technologien und Monitoring-Tools ins Gedächtnis rufen: Ursprünglich ging es ja darum, Dev-Teams Tools an die Hand zu geben, mit denen sie Software rascher entwickeln, bereitstellen und Innovationen rund um sie ebenso schneller würden gestalten können. All dies letztlich im Zeichen von Business- und Wettbewerbs-Prioritäten. Der hieraus entstandene Flickenteppich ist der Erreichung entsprechender Geschäftsziele jedoch alles andere als förderlich. Eine Konsolidierung im Tooling-Stack, in der Praxis effektiv vielmehr eine Rationalisierung von Tools, bringt Perspektiven und Status quo wieder ins Gleichgewicht. Der Schritt ist dabei vor allem aber auch wichtiger Wegbereiter für Observability als strategische Tragsäule von Geschäftszielen.

Ungewollte Sabotage von Geschäftszielen durch Tool-Fragmentierung
Monitoring-Methodik: Zeit für ein Upgrade
Mit DevOps-Frameworks und einer Abkehr von der Waterfall-Entwicklung hin zu Agile bringen Software-Teams neue Releases schneller live denn je. So kam es bei Legacy-Betriebsmodellen zu Monolith-Deployments in On-Prem-Infrastrukturen. Im Zuge fortschreitender Cloud-Migration hingegen wurden Microservice-Deployments in Containern über Hybrid-Umgebungen mehr und mehr zum Standard – und so Innovationschancen und bessere Kundenerlebnisse. Auf eine Modernisierung in der Software-Entwicklung muss nun auch eine entsprechende Anpassung der Monitoring-Strategie folgen.
Denn das Festhalten an einem Legacy-Modell mit isolierten, angeblichen Best-of-Breed- Punktlösungen macht auch den Weg frei für Komplexität in einer Ausprägung, in der sie zunehmend unbeherrschbar wird. Ineffizienzen, Produktivitätsverluste und Downtime nehmen zu. Allgegenwärtig werden zudem auch Datensilos mit eingeschränktem oder schlicht keinem Kontext und so letztlich auch ungenügende Kundenerlebnisse, die Wettbewerber rasch zu ihrem Vorteil nutzen können.
Für die heute immer dynamischeren Systeme will auch die Monitoring-Strategie entsprechend adaptiert werden. Zu diesem Schluss kommen die Analysten von 451 Research und S&P Global Market Intelligence in ihrem Bericht Monitoring: Ein Tech-Segment im Wandel. Im Zuge der von New Relic in Auftrag gegebenen Studie wurden 700 IT-Entscheidungsträger befragt. Lediglich 11 % zeigten sich dabei mit ihren aktuellen Monitoring-Plattformen zufrieden. Ganze 83 % sind hingegen momentan auf der Suche nach neuen Monitoring-Tools oder planen, ihre Monitoring- Methodik zu erweitern oder zu verbessern. Der Schlüssel hierzu: Observability.
Ihr Kundenerlebnis und somit auch Ihr Geschäftsergebnis steht und fällt immer mehr mit der Stabilität Ihrer Software. In diesem Kontext verleiht Observability Ihren Dev-Teams einerseits die nötige Sicherheit für ein adaptiv-agiles Vorgehen und parallel zentrale Transparenz für den Health-Status Ihres Gesamtsystems. Observability vermittelt Ihnen:
- Eine De-facto-Informationsquelle für Monitoring-Daten
- Möglichkeiten zur Eliminierung von Datensilos und raschere Problembehebung
- Mehr Klarheit zu Problemursachen und bessere Produktivität
- Vor allem aber: Business-Entscheidungen, die sich auf verlässliche Daten stützen
Observability: Alles an einem Ort
Was aber sind die Voraussetzungen für Observability? Grundlegend erfordert Observability Transparenz. Transparenz, um Telemetriedaten zentral abfragen, erfassen, analysieren und so Insights ableiten zu können – aus jeder beliebigen Quelle und so auch aus Open-Source-Tools. Eine Observability-Plattform sollte so Folgendes ermöglichen:
- Erfassung, Analyse und Alerts für alle Metrics, Events, Logs und Traces aus jeder Quelle
- Einfache Visualisierung und Problembehebung für Ihren gesamten Software-Stack in einer kompakten Benutzeroberfläche
- Raschere Erfassung, Analyse und Behebung von Incidents mit künstlicher Intelligenz für IT-Operations (AIOps)
Wie bei Daten generell geht es hier aber nicht nur um die Erfassung, sondern – viel wichtiger noch – um die Korrelation und die Abstraktion von Einblicken aus dieser. Ihre Observability- Plattform sollte die Zusammenhänge zwischen den Daten zum Vorschein bringen. Dies zudem ganz unabhängig vom Telemetrie-Datentyp oder von seinem Ursprung im Stack. Sie muss abbilden, wie die Anwendungen, die Sie entwickeln, sich auf den Health-Status Ihrer Container auswirken. Mit diesen Einblicken machen Sie Probleme rascher aus und spüren ihre Ursachen auf, um so im Umkehrschluss Ihr digitales Geschäft proaktiv zu optimieren.
Roadmap für Ihre Tool-Konsolidierung
Wie erwähnt müssen für Observability Daten zentral erfasst, analysiert und korreliert werden. Als vorbereitender Schritt empfiehlt sich somit eine Evaluierung und Rationalisierung Ihres bestehenden Toolsets. Es gilt, alle bestehenden Technologien mitsamt Ihrer Benutzer und Vorteile aufzulisten und dann eine Modernisierung zu initiieren.
Für eine bewährte, gut iterierbare Methodik ist abteilungsübergreifende Zusammenarbeit unabdingbar. Nur so lassen sich Kosten reduzieren, Problemerkennung und -behebung substanziell verbessern, der Wissensaustausch und Ihr Geschäft voranbringen.
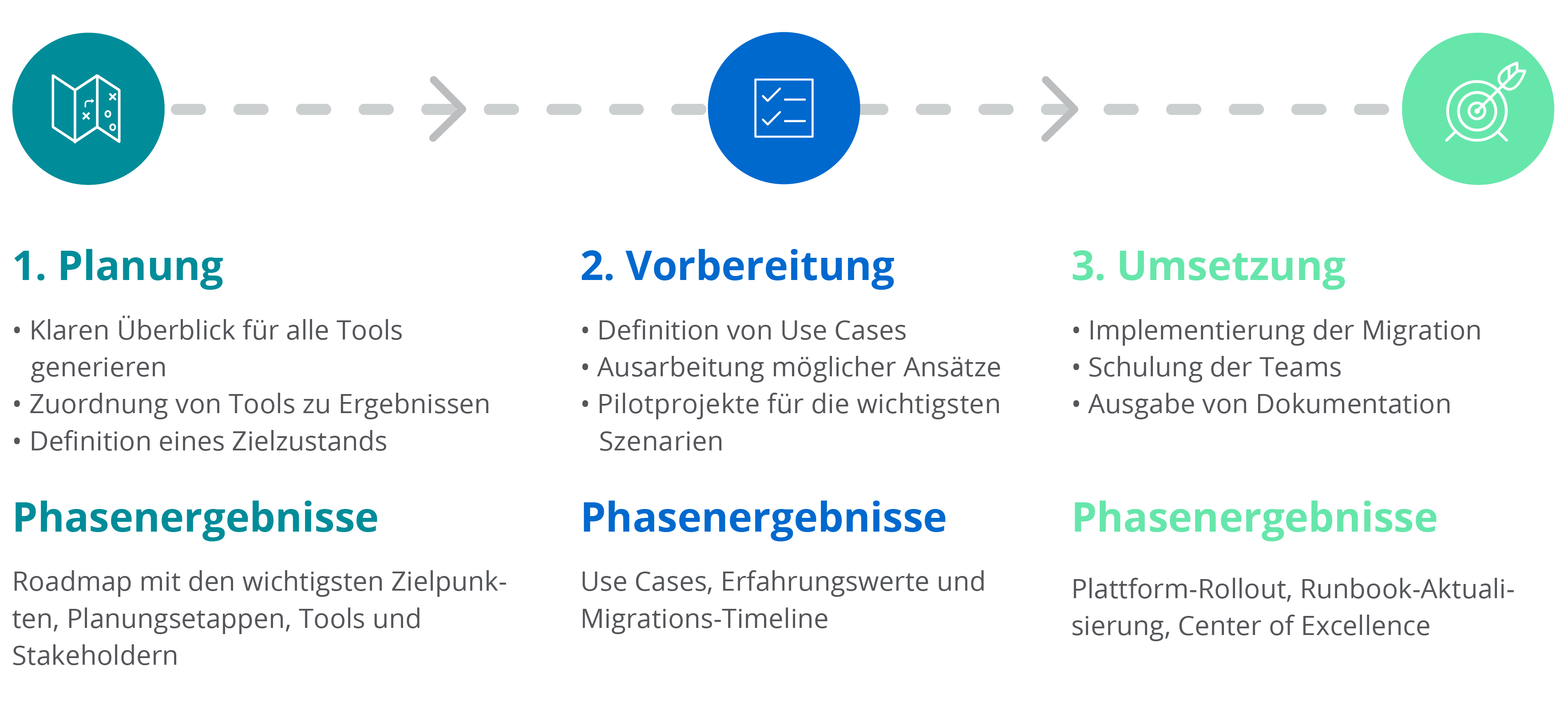
Planung, Vorbereitung, Umsetzung: Erfolgreiche Tool-Rationalisierung in drei Stufen
Phase 1: Planung
In der Planungsphase sollten zunächst ein klarer Überblick und Klarheit zu folgenden Punkten gewonnen werden:
- Alle Tools im Unternehmen
- Konkrete Zielsetzungen wie etwa:
- Bessere Team-Produktivität und -Zusammenarbeit
- Raschere Problemidentifikation und -beseitigung
- Geringere Lizenz-, Schulungs- und Wartungskosten
- Diagramm Ihrer Architektur in einem allgemein leicht verständlichen Format
- Im Migrationsverlauf wichtige KPIs
Die wichtigsten Projektergebnisse dieser Phase:
- Roadmap mit den wichtigsten Zielpunkten und Migrationsumfang
- Informationsaustausch und Kooperation zwischen involvierten Geschäftsbereichen und Teams
- Liste aktuell im Einsatz befindlicher Tools, interner Stakeholder und Budgetträger
- Aktuelle Architektur und Übereinkunft zu ihrer Zukunft
Im Verlauf dieser Discovery-Schritte sollte jeder beteiligte Geschäftsbereich eingehend zu den Projektzielen und dem anfallendem Arbeitsaufwand gebrieft werden.
Für jedes im Unternehmen verwendete Tool ist Folgendes visuell abzubilden:
- In welchen Teams es zum Einsatz kommt, in welchem Maße und welches Kontextwissen vonnöten ist
- Wie es verwendet wird und welche kritischen KPIs es unterstützt
- Welche Rolle es im Incident Management einnimmt
- Welche Tools miteinander im Zusammenhang stehen und wie Events oder Incidents die Umgebung durchlaufen
- Kosten und vertragliche Commit-Zyklen
- KPIs mit kritischer Bedeutung und ihr Zusammenhang mit Service-Monitoring
Hat jeder Geschäftsbereich seine Tools und wichtigsten Anforderungen dokumentiert, sollten in Gesprächen die folgenden Punkte eruiert werden:
- Für welche kritischen KPIs und Services ist eine Monitoring-Methodik implementiert?
- Wie kritisch sind sie tatsächlich? Können Sie ersetzt werden bzw. kann die jeweilige Monitoring-Methodik angepasst werden?
- Ist für jedes Tool ein direkter Ersatz notwendig? Oder weist das Toolset auch Redundanzen auf, im Falle derer eine Konsolidierung keine Konsequenzen hat?
- Welche wichtigen Funktionen und Integrationen bestehen für die verbleibenden Tools?
Eine Erfassung dieser Informationen zu einem frühen Zeitpunkt hilft bereichsübergreifenden Teams, adäquate Prioritäten und passende Use Cases für neue Lösungen auszuarbeiten.
Parallel muss basierend auf dem Status quo eine zukünftige Umgebungsarchitektur konzipiert werden:
- Welche Incident-Management-Tools kommen aktuell zum Einsatz? Erfüllen sie alle Anforderungen?
- Wie durchlaufen Incidents und Alerts die Umgebung gegenwärtig?
- Werden Tools von mehr als ein und demselben Team bzw. Geschäftsbereich verwendet?
- Welche Teams bzw. Geschäftsbereiche müssen über welche Art von Incident informiert werden?
- Welche Beschwerdepunkte oder Verbesserungsanfragen kommen vom Support?
- Mit welchen Änderungen könnten Problemerkennung und -behebung optimiert werden?
Die nun ausgearbeitete zukünftige Umgebungsarchitektur kann an dieser Stelle in einem Diagramm visuelle Formen annehmen.

Alle involvierten Geschäftsbereiche sollten die Konsolidierung aktiv unterstützen und in der Task Force repräsentiert sein.
Phase 2: Vorbereitung
In dieser Phase werden alle Schritte zur Umsetzung der Rationalisierung vorbereitet. Hierzu müssen umfassende Use Cases mit möglichen Lösungen erarbeitet und kritische Szenarien im Abgleich getestet werden. Dabei sollen nicht etwa exakte technische Möglichkeiten, sondern höher geschaltete Ziele abgebildet werden.
Etwa im Stile von „Wir benötigen im Mittel CPU/Speicher/Verbindungen/Abfragen pro Sekunde.“ Es handelt sich nicht um einen offenen Use Case, da eine bestehende Lösung die Parameter automatisch begrenzt. Eine passende Formulierung wäre also etwa „Wir benötigen Transparenz für den Health-Status und die Performance unserer Datenbank-Instanzen“, da hier der Weg für andere Lösungen offen bleibt.

Beispielstruktur zur Dokumentation von Use Cases
Nächste Schritte:
-
Zuordnung jeder funktionalen Anforderung bzw. von Funktionsgruppen zu einem Use Case
-
Erstellung einer Liste mit Use Cases und Tools, die dabei zum Einsatz kommen
-
Test spezifischer Use Cases anhand von Lösungen zur Verifizierung
Hier sollen Use Cases im Zusammenhang mit bestimmten Tools identifiziert und basierend hierauf kann dann ein Migrationsplan erstellt werden.
Dabei werden Ziele über verschiedene Cycles hinweg abgebildet, beginnend bei einfach zu migrierenden Umgebungen bis hin zu den komplexesten, etwa solchen also, bei denen die gegenwärtige Situation nicht komplett bekannt ist.
Zu Anfang geht es um die Einrichtung eines Observability Center of Excellence (siehe Beispiel hier) und die Ausarbeitung von Unternehmensstandards.
Phase 3: Umsetzung
In dieser Phase werden nun die gemeinsamen Beschlüsse aus der Vorbereitungsphase umgesetzt. Soweit möglich sollten dabei alle zur Tool-Konsolidierung notwendigen Änderungen durchgeführt werden, so etwa:
-
Implementierung von Änderungen und Deployment dieser in Test-, Staging- und schließlich Produktionsumgebung
-
Schulung von Teams zur neuen Plattform für effektiven Betrieb im Tagesgeschäft
-
Implementierung der Strategie für Alerting und Event Management aus der Planungsphase
-
Dokumentation und Weitergabe von Erfahrungen, die in etwaigen zukünftigen Phasen nützlich sein könnten
Die Teams können dabei ihre bevorzugte Methodik zur Planung der Migration nutzen. Wichtig bleibt, dass die Umsetzung im vorab beschlossenen Zeitfenster abgeschlossen wird.
Wurde die Umsetzung vollständig durchgeführt bzw. der vorab definierte Zielzeitpunkt erreicht, analysieren die involvierten Teams in einer Retrospektive gemeinsam den Fortschritt, erreichte Verbesserungen und nächste Schritte. Die dabei erlangten Details kommen dann als Dokumentation bei iterativen Migrationsprozessen zum Einsatz.
Diese drei Phasen werden bis zur vollständigen Migration der Umgebung und bis zum Erreichen der gemeinsam beschlossenen Ziele wiederholt.
Fazit
Eine Zusammenarbeit bei der Tool-Konsolidierung mit New Relic vermittelt Ihnen Zeiteinsparungen, neue Kosteneffizienzen und Produktivitätsgewinne sowie geringere Kapitalaufwendungen. Mit unserer Methodik erhalten Ihre Teams zentrale End-to-End- Transparenz, leicht nachvollziehbare Preismodelle mit Planungsgenauigkeit sowie Support von unserem Expert Services Team in allen Phasen.
Bringen Sie Ihre Tool-Konsolidierung von Anfang an auf die Erfolgsspur mit weniger Komplexität und mehr Zusammenarbeit. Richten Sie den Fokus Ihrer Teams dauerhaft auf Innovation und Kundenerlebnisse, die begeistern. Weiterführende Informationen finden Sie in dieser Kunden-Erfolgsstory für gelungene Tool-Konsolidierung.
Sie möchten sich ein Bild davon machen, wie eine Tool-Konsolidierung für Sie möglich ist? Sprechen Sie uns an. Unsere Experten zeigen Ihnen auf, wie Sie diesen Weg beschreiten.


