Kontext als geschäftskritischer Baustein in Zeiten der Veränderung
Die Standards für Software Delivery wie auch operative Abläufe waren im vergangenen Jahrzehnt einem immer dynamischeren Momentum unterworfen. In der Folge müssen IT-Teams nun auch ein viel ausgedehnteres Infrastruktur-Feld bestellen, dessen Größe wie auch Komplexität weiter zunehmen.
Veränderung. Einst massiver Belastungspunkt für IT-Infrastrukturen, nun die Grundlage zur Ausbildung von Wettbewerbsvorteilen.
DevOps für schnellere, häufigere Infrastruktur- und Anwendungs-Deployments. Modernisierung von Anwendungen, um mehr Speed, Skalierbarkeit und Performance zu erreichen. Cloud-Migration. Microservice-Einführung. Kubernetes zur Container-Orchestrierung.
Veränderung. Schnell und konstant. Und überall in der Blutbahn
Ihrer Infrastruktur.
Mehr Änderungen an Software, mehr Konfigurationen, mehr Alerts. Mehr...von allem. Ebenso auch mehr Druck. Mehr Druck, Probleme rascher zu dentifizieren und zu beheben. Mehr Druck, die Stabilität und Verlässlichkeit von Produktionssystemen zu garantieren.
Die Komplexität, die sich im Namen von Speed und Skalierbarkeit entwickelt hat, gilt es, im Monitoring mit dem Shift-Left-Prinzip zu adressieren. Denn in einer Vielzahl der Fälle ist bei Systemanpassungen vor dem Rollout in die Produktion noch so einiges nicht komplett zu antizipieren. Daher unabdingbar: Observability.
Mit dieser grundlegenden Änderung in Sachen Methodik bleiben auch noch so dynamische Systeme stets transparent.
Nur kommen aber je nach Team und Stack-Komponenten häufig ganz unterschiedliche Monitoring- Tools zum Einsatz. Eines für Entwickler, eines für IT-Ops, eines für Business Manager, eines für Logs, eines für Metrics, eines für Traces, eines für On-Prem-Tech, wieder ein anderes für die Cloud.
Und jedes einzelne dieser Tools ist sicher eine hervorragende Wahl für das jeweilige Team.
In der Praxis bedeutet diese Tech- Streuung nun aber auch für jedes Team mehr Alerts, mehr Telemetrie und mehr kritische – aber leider auch fragmentierte – Ops-Daten.
Fragmentierte Tooling-Landschaften bedeuten auch fragmentierte Observability. Und die nützt keinem.
Jedes Tool liefert nur einen Teil des Gesamtbilds, während dieses selbst jedoch weiter in flux und dynamisch bleibt. Die Grenzen zwischen den einzelnen Stack-Komponenten verschwimmen leicht. Die Ursache für einen Anwendungs-Ausfall in Code oder Infrastruktur ausfindig zu machen, bevor es zu einem Dominoeffekt kommt, ist eine Sache. Aus ihr wird jedoch eine Herausforderung völlig neuen Ausmaßes, wenn die punktuelle Natur der Einzellösungen für Ihre Systemkomponenten nun auch noch zusätzlich Zeit und Geld kostet.
Ihre Daten hängen nun plötzlich in Silos fest, von den Technologien zudem noch mit ihrem eigenen, proprietären Vokabular erfasst. Ihre Teams sprechen somit alles, nur keine gemeinsame Sprache, sehr zum Leidwesen Ihrer MTTD und MTTR.
Direkt finanziell quantifizierbarer Natur sind diese Effekte nur zu Beginn. Sie entfalten schnell zusätzliche Tücken an anderen Stellen im Unternehmen. So verbringen IT und Operations bald zu viel Zeit mit der Fehlerbehebung. Für Innovation bleibt immer weniger übrig. Gemeinsame Zielausrichtung und Zusammenarbeit für Ihre Teams werden immer schwerer. Die Moral Ihrer Mitarbeiter leidet.
Ihr Unternehmen bekommt die Folgen dieses Tooling- Tohuwabohu zu spüren.
In diesem Leitfaden betrachten wir, wie sich fragmentierte Tooling-Landschaften auf Ihr Unternehmen auswirken können. Genauso aber betrachten wir die positive Seite der Medaille – nämlich alle Chancen, die sich für Ihr Team auftun, wenn Sie diese Herausforderungen angehen.
Tooling-Tohuwabohu: Wie schwer wiegt es wirklich?
Die ganze Geschichte erzählen mögen Zahlen allein vielleicht nicht, sie sind aber ein wichtiger Anfang zur objektiven Erfassung. So gaben in einer Umfrage von 451 Research 39 % aller Befragten an, fortlaufend zwischen 11 und 30 Monitoring-Tools für ihre Anwendungen, Infrastruktur und Cloud- Umgebungen im Einsatz zu haben. Bei 8 % waren es sogar zwischen 21 und 30.
Bei vielen davon handelte es sich höchstwahrscheinlich um Open- Source-Technologien und somit zunächst „kostenlose“ Lösungen. Doch die zugehörigen Kosten, die anfallen, bevor es überhaupt zu Downtime kommt, ergeben addiert schnell eine stattliche Summe.
Langsamer am Problem
Das erste Problem infolge dieser fragmentierten Tooling- Konstellation begegnet uns im Faktor Zeit. Genauer gesagt in Form all der Zeit, die Ihre Mitarbeiter beim Hin- und Herwechseln zwischen verschiedenen Tools verlieren. Aus augenscheinlichen Sekunden oder Minuten in einer bestimmten Situation wird rasch ein viel größeres Problem-Ungetier, das sich nun an allen Ecken und Enden aufbaut.
Schlechtere Datenauflösung
Kommen für verschiedene Stack- Bereiche beim Monitoring unterschiedliche Tools zum Einsatz, geht dies unweigerlich auf Kosten der Transparenz für Ihre Gesamtumgebung. Die System- Health lässt sich schließlich nicht mehr mit der Anwendungs- Performance in allen Komponenten korrelieren.
Mehr Admin-Aufwand
Wenngleich bestimmte Tools an sich zunächst kostenfrei nutzbar sind, müssen sie aber immer noch eingerichtet und verwaltet werden. Zu Buche schlagen hier unter anderem Software-Lizenzen, interne Ressourcen, Add-on-Module, Speicher, Hardware, API-Zugriff und der Aufwand für allgemeine Abläufe. Schon für ein Team allein ist das nicht wenig Arbeit.
Potenzieren sich diese Probleme nun über eine verteilte Umgebung, treten die inhärenten Ineffizienzen nur allzu schmerzlich zutage.
Unter dem Strich steht: Incidents zu beheben ist nun eine längere Angelegenheit als zuvor. Im Falle einiger Probleme lässt sich die Ursache auch überhaupt nicht ausmachen, da alle Daten zu weit verteilt sind. Es entstehen also leicht Probleme, die sich negativ auf das Erlebnis Ihrer Endbenutzer auswirken. Insbesondere, wenn diese vor Ihnen auf die Fehler aufmerksam werden.
Downtime und Geschäftskosten stehen in einem direkten Verhältnis, das leicht aus den Fugen geraten kann.
Einer Studie von Gartner zufolge fällt Downtime pro Stunde mit Kosten von durchschnittlich 300.000 US-Dollar ins Gewicht. 33 % aller Unternehmen beziffern eine Stunde gar auf einen Verlustbetrag zwischen 1 und 5 Millionen US-Dollar.
Am wichtigsten dabei: Um Problemen vorzubeugen, ist ein klarer Blick auf etwaige Schieflagen vonnöten.
Noch viel klarer wird dieser Blick, wenn Sie Kontext an Ihrer Seite wissen.

Kompletter Kontext – der Game Changer
Observability und Monitoring existieren nicht einfach nur als Konzepthülsen.
Eine erfolgreiche Observability- Strategie fußt in erster Linie auf drei Primärzielen:
- Einnahmen steigern
- Kundeninteraktionen verbessern
- Operative Optimierungen gestalten
Allen drei gemein: Es geht um Ihr Geschäft.
Beim Erreichen dieser Ziele geht es aber nicht einfach nur darum, so viele Daten zu akkumulieren wie nur irgendwie möglich. Vielmehr gilt es, verschiedenste Datenpunkte korreliert in Kontext bringen und anhand dieser zielführende Systemfragen stellen zu können.
Mehr Daten mögen dabei in mehr Einblicken münden. Nur macht eine höhere Anzahl an Tools diese entsprechend auch schwerer abrufbar.
Mehr Tools ≠ Mehr Einblicke
Wenn Monitoring nun also ein Mittel zum Zweck ist, sind auch nur folgende Faktoren wirklich von Bedeutung:
- Wie viel geschäftlichen Wert hat Ihre Monitoring-Lösung?
- Als wie effektiv und nützlich erweist sie sich bei der Fehlerbehebung?
- Wie gut lassen sich anhand der Daten kritische Probleme identifizieren und adressieren?
Die Zeit, die beim Wechsel zwischen separat betriebenen Tools und bei Problemdiagnose und -behebung zusätzlich vergeht, kann sich als Zünglein an der Waage herausstellen.
Denn lassen sich mit Monitoring zwar Metrics aus dem gesamten Stack erfassen, jedoch keine Rückschlüsse zur Lösung wichtiger Probleme ziehen, vergeudet dies nur wertvolle Ressourcen.
Hier kommt Kontext als Game Changer ins Spiel, und mit ihm eine zentrale Observability-Plattform als Fundament.
Kontext und sein Potenzial
Aus eben dieser zentralen Observability-Plattform speist sich der Kontext für Ihren gesamten Stack.
End-to-End für Ihre Infrastruktur, Ihre Anwendungen und Ihr Endbenutzer-Erlebnis auf Web- und mobilen Applikationen. Dies unter Einbezug aller Telemetrie- Aspekte – Metrics, Events, Logs und Traces – zentral konsolidiert.
Dabei werden aus und für Ihre Daten relevante Zusammenhänge korreliert, die Ihren Teams zu schnelleren Problemlösungen verhelfen.
Ebenso können Sie rasch für Ihre Teams nützliche Anwendungen erstellen. Diese bilden damit Infrastruktur-Health und -Performance im Zusammenhang mit Geschäftsergebnissen und Kundenerlebnis ab.
Anhand von eigenen interaktiven Visualisierungen konfigurieren Ihre Teams die Daten passgenau und für ihre individuellen Anforderungen relevant.
Kombinieren Sie alles, was Sie über Ihr Unternehmen und Ihr Geschäft wissen, mit innovativen Features zur Anwendungsentwicklung. Sie erlangen so Kontext, der ganz spezifisch zu Ihnen passt. Und bewegen sich dadurch weg von der Bekämpfung von Brandherden hin zu ihrer Vermeidung im Vorfeld.
Ganz konkret lässt sich dies dann beispielsweise so ausgestalten. Was könnten Sie programmieren, um Ihr Unternehmen bei der Lösung kritischer Probleme zu unterstützen?
Cloud-Ausgaben stets messbar im Blick
Können Sie die Größe Ihrer Cloud- Instanzen mit ihrer Auslastung abgleichen, sind Sie auch in der Lage, potenziell überprovisionierte Ressourcen auszumachen. Es geht aber noch genauer: Wählen Sie bestimmte Hosts, Regionen und andere Konfigurationen aus und definieren Sie Ihre eigenen Use Cases.

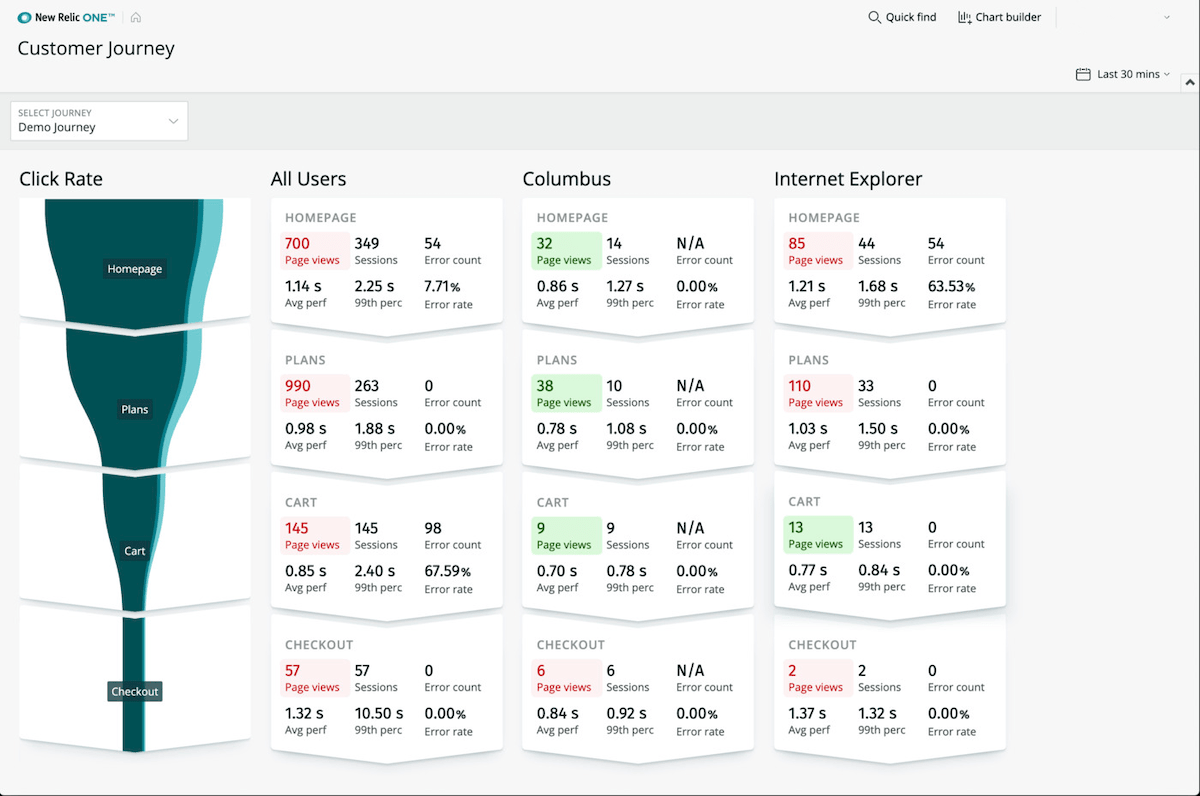
Konversionsvorgänge präziser analysieren
Evaluieren Sie die Schritte Ihrer Buyer Journey komplett anpassbar über ein interaktives Interface. Zu jedem Schritt können Standard-Daten wie Seitenansichten, Fehlerrate und -zahl ausgegeben werden. Prüfen Sie Ihre Metrics in jedem Funnel-Schritt auf Herz und Nieren.
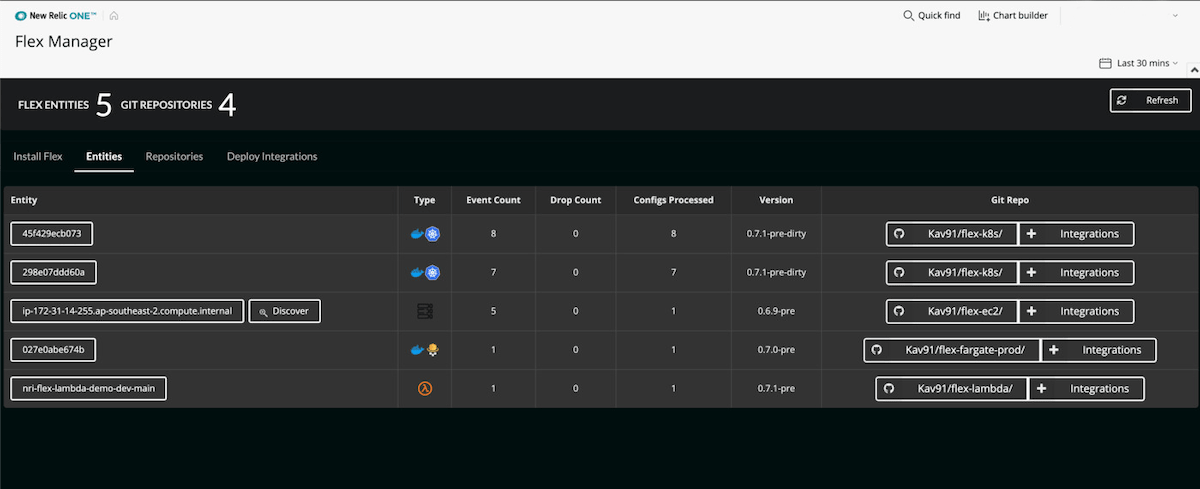
Neue Infrastruktur- Integrationen nahtlos erstellen
Ops-Teams nutzen eine fortlaufend exponentiell wachsende Anzahl an Endpunkten. Hier kommt eine agnostische All-in-one-Integration umso mehr zum Tragen. Sie macht die Aggregation von Daten aus externen Quellen einfach wie nie zuvor. Ihren Teams liegt so immer der Kontext vor, den sie benötigen, um Fehler in ihrer Infrastruktur-Umgebung zu beheben.
Kontext und Infrastruktur bedingen einander
Wie auch Observability besteht Infrastruktur nicht einfach um ihrer selbst willen, sondern im Kontext eines Gesamt-Stacks. Dieser selbst wiederum besteht im Kontext von Kundenerlebnissen – die es unbedingt erfolgreich zu gestalten gilt.
Konstante Veränderungen dominieren und definieren modernes Infrastruktur- Management nunmehr, machen die Identifikation von Anwendungsproblemen zunehmend schwerer. Dieses Konstrukt stabil und transparent zu errichten und zu erhalten war dabei nie wichtiger.
Mit punktuellen Lösungen, die sich auf Silodaten stützen und Monitoring nur für eine bestimmte Stack-Komponente wie Logs oder Linux-Infrastruktur möglich machen, ist dies immer nur eingeschränkt möglich. Sie mögen einem bestimmten Team ganz hervorragend nützen, über dessen Stack-Grenzen hinaus sorgen sie aber nur für Chaos.
Für die so wichtigen Anstrengungen rund um optimale MTTR, minimale Downtime und möglichst keine Auswirkungen auf das Endbenutzer-Erlebnis sind bei Ausfällen zwei Fragen ganz zentral: Wo finde ich das Problem? Und warum ist es überhaupt aufgetreten?
Nur mit dem vollständigen Kontext einer Observability-Plattform wird aus der Lokalisierung schnell Ursachenidentifikation. Können Ihre Teams also die direkt weiterführenden Fragen schnell stellen, reduzieren Sie sofort Downtime und das Risiko negativer Erlebnisse für Ihre Kunden.
Eine moderne Infrastruktur- und Observability-Plattform liefert dabei die notwendigen Daten zentral im richtigen Kontext. Dies gelingt durch Korrelation zunächst noch komplett separater Daten aus Infrastruktur, Logs, Konfigurationsänderungen, Anwendungen und Frontend- Services.
Ops-Teams wissen so genau, welchen Einfluss ihre Infrastruktur auf ihre Anwendungen nimmt und umgekehrt.
Sie haben das Gefühl, in Ihren Daten schlummern wertvolle Geheimnisse? Dann sollten wir uns sprechen.
Mit New Relic One erhalten Dev- und Ops-Teams Zugang zu denselben Daten über eine zentrale Plattform. Sie nutzen dabei die schnellsten und präzisesten Features zur Korrelation von Anwendungen und Infrastruktur und identifizieren und beheben Probleme so direkter.
Auf welches Problem Sie dabei auch stoßen mögen – Ihre Kunden werden es zukünftig nicht mehr antreffen.


