Vous souhaitez mieux comprendre vos données New Relic ? Le langage NRQL peut vous y aider en vous permettant d'analyser vos données en temps réel. Si à première vue, cette tâche peut vous paraître insurmontable, n'ayez crainte. Ce blog en deux parties vous explique 10 fonctions et clauses NRQL essentielles qui vous aideront à mieux comprendre NRQL et surtout à mieux comprendre vos données. Ces fonctions et clauses vous aideront à calculer des pourcentages, à créer des cartes thermiques, à développer des widgets conditionnels, et bien plus encore. Avec NRQL, vous pouvez obtenir plus de vos analyses de données. Pour commencer, apprenons à utiliser NRQL pour tirer des informations précieuses de vos données.
1 : Sélectionnez X dans Y
SELECT X from Y , FROM Y SELECT X
Il s'agit du moyen le plus simple d'effectuer une interrogation. Chaque requête NRQL commence par une instruction SELECT ou une clause FROM. Il est préférable de commencer votre requête initiale avec FROM, car vous obtenez une liste des valeurs de l'événement ou de la métrique à votre disposition et SELECT indique la partie d'un type de données que vous souhaitez interroger en spécifiant un attribut ou une fonction. Par exemple, SELECT * FROM Transaction collectera les valeurs de tous les attributs disponibles en utilisant le caractère générique *.

Pour utiliser les suggestions automatiques du générateur de requêtes, utilisez la clause FROM . Par exemple, FROM Transaction SELECT transactionSubType suggérera uniquement l'attribut pertinent du dataset sélectionné.

Chaque requête NRQL doit commencer par une instruction SELECT ou une clause FROM. Toutes les autres clauses sont facultatives, mais nous pouvons améliorer notre requête initiale pour être plus précis en y ajoutant une plage horaire, pour comparer ou ajouter des étiquettes personnalisées. Essayez ce qui suit :
SINCE
utilisez la clause SINCE pour définir le début d'une plage horaire pour les données renvoyées. Vous pouvez spécifier un fuseau horaire pour la requête, mais pas pour les résultats. Les résultats NRQL sont basés sur l'heure de votre système, par exemple since 5 minutes ago, since 1 months ago limit max. Remarque : La valeur par défaut est 1 hour ago.
UNTIL
est utilisé pour spécifier un point final autre que celui par défaut. Une fois la plage horaire spécifiée, les données sont conservées et consultables après la fin de la plage horaire indiquée. Remarque : la valeur par défaut est NOW.
Voici un scénario pratique dans lequel nous pouvons combiner SINCE et UNTIL pour tracer un graphique chronologique de la durée maximale des transactions pendant 1 mois moins les données d'aujourd'hui :
FROM Transaction
SELECT MAX(duration)
WHERE appName = 'node-express-mongodb'
since 1 months ago until 1 DAY ago TIMESERIES auto

Remarque : il est également possible d'utiliser la date et l'heure absolue : SINCE '2022-10-10 09:00:00' ou UNTIL '2022-10-10 10:00:00'
COMPARE WITH
Pour comparer les valeurs de deux plages horaires différentes, COMPARE WITH nécessite une instruction SINCE ou UNTIL. L'heure spécifiée par COMPARE WITH est relative à l'heure spécifiée par SINCE ou UNTIL. Par exemple, SINCE 1 day ago COMPARE WITH 1 day ago compare la veille avec l'avant-veille. Voici un exemple pour comparer les valeurs de deux plages de temps différentes :
SELECT average(duration) FROM Transaction SINCE 1 DAY AGO COMPARE WITH 1 WEEK AGO

AS
La clause AS peut être utilisée pour étiqueter un attribut, un agrégateur ou le résultat d'une fonction mathématique. Cela peut être extrêmement utile lors de la création de graphiques, car cela permet d'identifier plus clairement le résultat d'une équation ou d'une requête. Ce qui suit est un exemple de graphique dans lequel AS a été utilisé pour étiqueter un dataset. Cette étiquette peut faciliter la compréhension des résultats du graphique, car elle indique clairement la source des données dans le graphique.
SELECT count(*)/uniqueCount(session) AS 'Pageviews per Session'
FROM PageView

2: Fonctions mathématiques
NRQL vous permet d'utiliser des opérateurs mathématiques simples et complexes dans une clause SELECT. Vous pouvez utiliser des calculs mathématiques sur des attributs individuels ainsi que sur la sortie des fonctions d'agrégation.
-
count : Obtenez le nombre d'enregistrements disponibles. Le comportement est similaire à celui du langage SQL et compte tous les enregistrements pour l'attribut donné.
FROM Transaction SELECT count(*)
") count(*)")
count(*)")
-
average , min, max : Calculez le minimum, le maximum et la moyenne d'un attribut. Par exemple, vérifiez la durée de la transaction
FROM Transaction SELECT average(duration) ,max(duration), min(duration) WHERE host LIKE '%west%'
, min() & max()")
-
pourcentage : Calculez le pourcentage d'un dataset cible. Le premier argument exige une fonction d'agrégation sur l'attribut souhaité.
FROM TRANSACTION SELECT percentage(count(*), WHERE error IS true) AS 'Error Percent' WHERE host LIKE '%west%' EXTRAPOLATE
-
percentile : Calculez le centile pour l'attribut requis
FROM TRANSACTION SELECT percentile(duration, 95, 75, 60) WHERE host LIKE '%west%' EXTRAPOLATE

Références
- En savoir plus sur les FONCTIONS D'AGRÉGATION
3 : Séries chronologiques
Utilisez la clause TIMESERIES pour obtenir des données sous la forme d'une série chronologique découpée en tranches de temps. Ces tranches de temps sont également appelées « bucket » et peuvent être définies en secondes, minutes, heures, etc.
Le mot-clé TIMESERIES peut être ajouté à toute requête utilisant la fonction d'agrégation pour tracer les valeurs au fil du temps.
FROM Transaction
SELECT MAX(duration)
WHERE appName = 'node-express-mongodb'
SINCE 1 MONTHS AGO
TIMESERIES AUTO

Vous pouvez également définir les tranches de temps pour la série, telles que TIMESERIES 30 seconds pour capturer des points de données dans la série à des intervalles de 30 secondes, TIMESERIES 1 minute pour capturer les points de données de la série à des intervalles de 1 minute, et TIMESERIES max pour capturer tous les points de données de la série sans aucun intervalle défini.Cela vous permet de personnaliser les tranches horaires de la série en fonction de la période avec laquelle vous préférez travailler.
Références
- En savoir plus sur TIMESERIES
4 : FACET (ou regrouper par)
FACET
Utilisez facet pour regrouper conditionnellement vos résultats par valeurs d'attribut et les séparer pour chaque groupe. Cela peut être utile lorsque vous souhaitez analyser vos données selon différentes catégories ou dimensions.
Voici un exemple simple utilisant la clause FACET où vous pouvez regrouper l'attribut PageView en fonction de chaque ville présente dans votre dataset :
SELECT count(*) FROM PageView FACET city
Le résultat de cette requête vous montre le nombre de pages vues pour chaque ville de votre dataset, séparées en différents groupes en fonction de l'attribut de ville.

FACET CASES
L'autre variante de facet est facet cases. En utilisant le mot-clé cases avec Facet, nous pouvons ajouter plusieurs conditions à la requête voire combiner plusieurs attributs dans chaque FACET CASE.
Voici un exemple où vous pouvez utiliser la clause FACET CASES pour interroger les données PageView et récupérer plusieurs résultats entre différentes valeurs de durée du dataset :
SELECT count(*) FROM PageView
FACET CASES
(WHERE duration < 1,
WHERE duration > 1 and duration < 10)
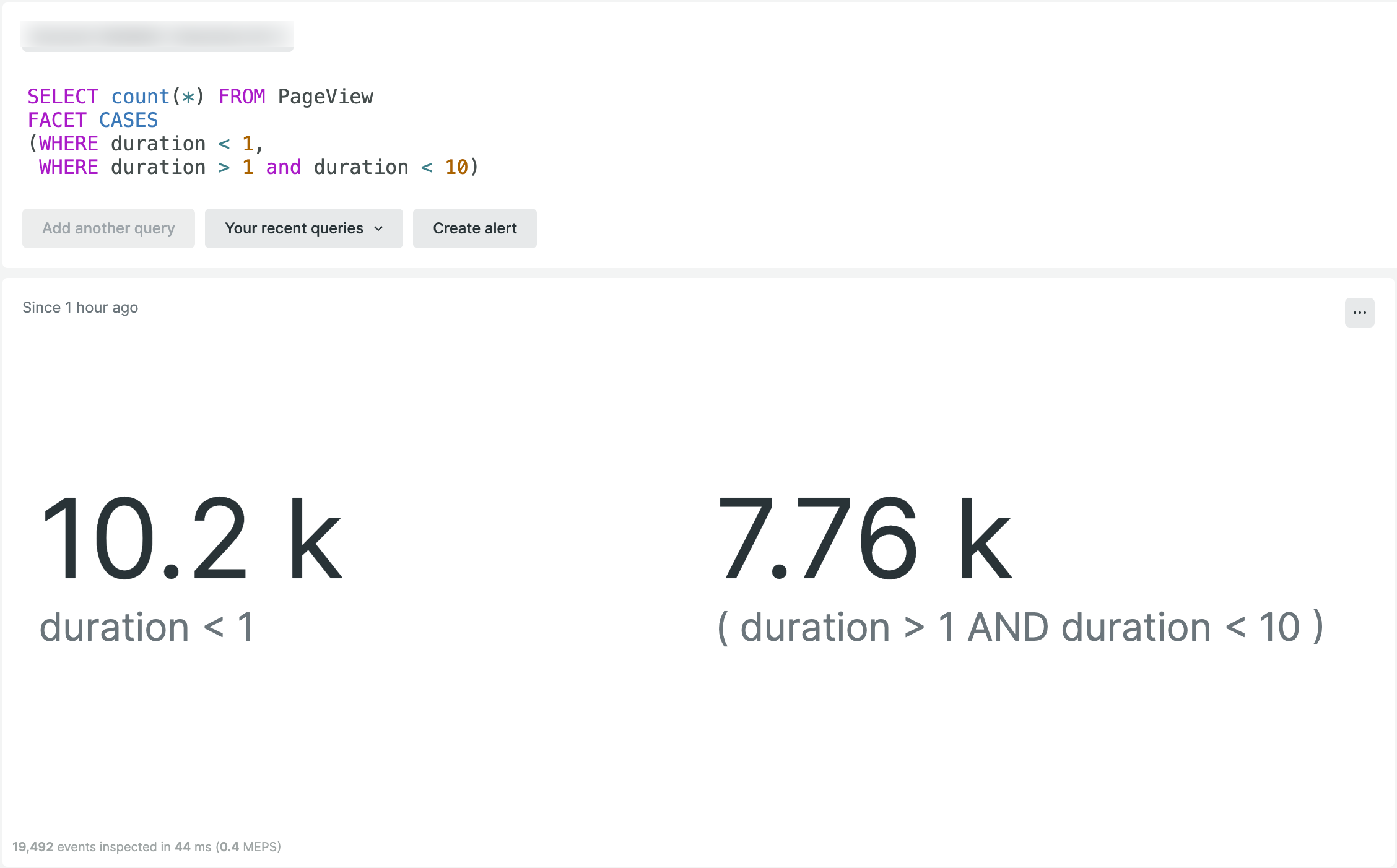
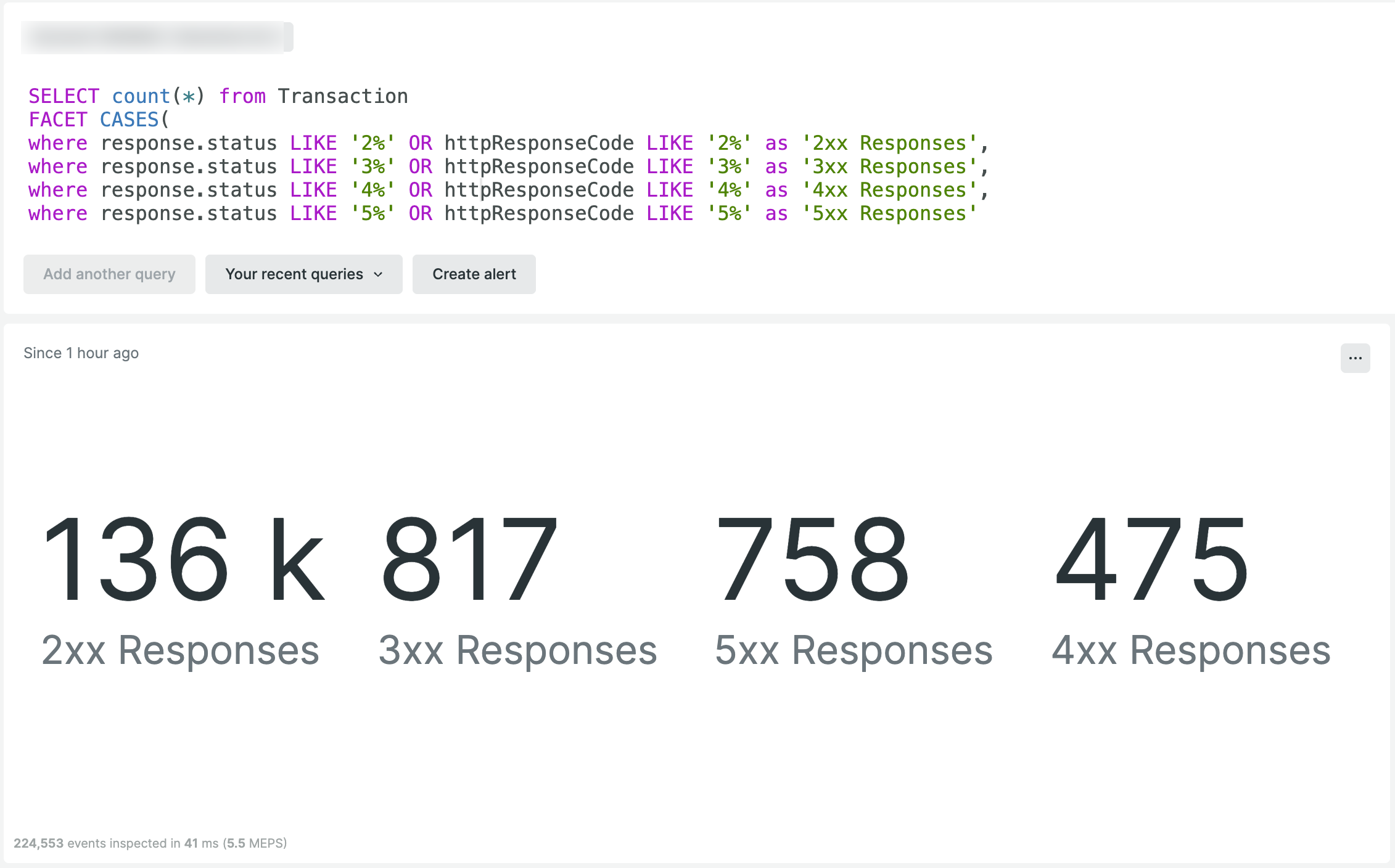
Pour que vos résultats de requête soient plus facilement lisibles et compréhensibles, vous pouvez affecter des étiquettes personnalisées à chaque condition au sein de FACET CASES en utilisant l'option as pour l'étiquetage :
SELECT count(*) from Transaction
FACET CASES(
where response.status LIKE '2%' OR httpResponseCode LIKE '2%' as '2xx Responses',
where response.status LIKE '3%' OR httpResponseCode LIKE '3%' as '3xx Responses',
where response.status LIKE '4%' OR httpResponseCode LIKE '4%' as '4xx Responses',
where response.status LIKE '5%' OR httpResponseCode LIKE '5%' as '5xx Responses'
)
Références
5 : Filtre
Le filtrage des résultats de votre requête peut être un moyen utile de limiter les résultats aux informations les plus pertinentes. NRQL propose plusieurs méthodes de filtrage de vos datasets.
Filtre générique
Les filtres génériques sont utiles lorsque vous essayez de filtrer le résultat d'une requête avec un certain modèle sur les propriétés du dataset sélectionnées. NRQL fournit un bon mécanisme pour ajouter des filtres génériques en utilisant le symbole %.
Dans l'exemple ci-dessous, nous prenons la moyenne de toutes les propriétés qui se terminent par .duration dans notre dataset. Dans les résultats, nous voyons deux propriétés correspondant à notre filtre :
FROM Metric SELECT Average(%.duration) FACET metricName TIMESERIES

Fonction filter()
La fonction filter() est utile dans les cas où il faut interroger et combiner les résultats de plusieurs attributs. Nous pouvons simplement combiner plusieurs résultats de datasets avec filter(), séparés par une virgule dans notre requête.
Dans cet exemple, nous utilisons un agrégateur pour obtenir le nombre total de tous les événements de notre dataset étiquetés comme « Événements combinés » à partir des attributs PageView et Transaction.
SELECT COUNT(*) AS 'Combined Events' FROM Transaction, PageView SINCE 1 DAY AGO
_1.png "NRQL filter() sample")
Nous pouvons rendre la sortie plus intéressante en montrant le total de tous les événements, ainsi que le total individuel des événements PageView et Transaction. Ceci peut être facilement réalisé en utilisant la fonction filter() avec la requête suivante :
SELECT count(*) as 'Combined Events',
filter(count(*), WHERE eventType() = 'PageView') as 'Page Views',
filter(count(*), WHERE eventType()='Transaction') as 'Transactions'
FROM Transaction, PageView SINCE 1 DAY AGO
_2.png)
Voici un autre exemple où nous pouvons utiliser filter() pour obtenir le nombre de métriques différentes avec la clause WHERE de toutes les Transactions :
FROM Transaction SELECT
filter(count(*), where request.uri not like '/api/%') as 'Others',
filter(count(*), where request.uri like '/api/tutorials%') as 'Tutorial Endpoints',
filter(count (*), where request.uri like '/api/weather%') as 'Weather Endpoints'
where appName = 'node-express-mongodb'
since 2 months ago limit max
_3.png "NRQL WHERE clause with filter()")
Références
- En savoir plus sur FILTER()
Jusqu'ici, dans ce blog, nous avons couvert les fonctions NRQL de base qui sont nécessaires pour interroger les données. Dans la prochaine section, nous allons aborder des fonctions et fonctionnalités légèrement plus avancées de NRQL. Elles vous aideront à gérer les requêtes et les visualisations de données complexes, et vous permettront de tirer le meilleur parti de vos données télémétriques.
Étapes suivantes
Si vous n'utilisez pas encore New Relic, créez un compte gratuit pour tester toutes nos fonctionnalités. Votre compte gratuit comprend 100 Go/mois d'acquisition de données gratuites, un utilisateur à accès complet gratuit et des utilisateurs de base gratuits et illimités.
Revenez bientôt sur ce site pour la 2e partie de cette série de blogs et découvrir d'autres fonctions NRQL et bonnes pratiques.

Les opinions exprimées sur ce blog sont celles de l'auteur et ne reflètent pas nécessairement celles de New Relic. Toutes les solutions proposées par l'auteur sont spécifiques à l'environnement et ne font pas partie des solutions commerciales ou du support proposés par New Relic. Veuillez nous rejoindre exclusivement sur l'Explorers Hub (discuss.newrelic.com) pour toute question et assistance concernant cet article de blog. Ce blog peut contenir des liens vers du contenu de sites tiers. En fournissant de tels liens, New Relic n'adopte, ne garantit, n'approuve ou n'approuve pas les informations, vues ou produits disponibles sur ces sites.


