No mundo do monitoramento tradicional, você, provavelmente, observava o consumo de recursos (como CPU, disco e memória) porque essas métricas eram fáceis de obter, e tinham uma correlação básica com disponibilidade e desempenho. Se você se envolveu em práticas de melhoria contínua, como eu fiz, e rapidamente acabou coletando uma lista enorme de métricas granulares de recursos, precisou manter um labirinto de regras de correlação para tentar entendê-las.
Agora que você está no mundo DevOps e da observabilidade, você precisa de mais do que isso. Aqui está o porquê:
- Alguns tipos de consumo de recursos não podem (ou não deveriam) ser medidos em um ambiente de nuvem.
- As cargas de trabalho podem ser altamente variáveis, por isso, os limites podem ser difíceis de definir.
- Você precisa de mais flexibilidade sobre o que está medindo, e controle sobre como medi-lo.
- Você precisa comunicar o seu status de forma rápida e concisa para muitas pessoas.
Mais importante ainda, os ambientes de TI estão se expandindo (pense nos microsserviços), então você precisa simplificar o que coleta e, ao mesmo tempo, tornar esses dados mais relevantes. Se você não o fizer, o seu armazenamento de métricas passará de grande a gigante, e isso aumentará o seu trabalho administrativo sem agregar valor.
Adotando uma abordagem diferente, medindo velocidade e qualidade
Os seus clientes (internos e externos) esperam uma tecnologia que forneça respostas rápidas e de alta qualidade; eles não estão preocupados com os detalhes. Se você deseja atender às expectativas nos termos deles (e deveria, já que eles o contrataram), então você deve se concentrar em medir o tempo de resposta (velocidade) e os erros (qualidade). Além disso, você precisa resumir tudo em um número único e fácil de entender, que mostra às suas equipes de Ops e Engenharia onde devem concentrar a atenção, e isso permite que as partes interessadas não-técnicas entendam intuitivamente o status atual, para que possam tomar decisões de negócios críticas.
Isso é importante, porque a empresa não se importa com o fato de algum processo estar consumindo 2% mais CPU do que antes—ela se preocupa com a experiência dos clientes. Isso significa que você mede e comunica duas coisas principais: velocidade e qualidade.
É aí que um Indicador de Nível de Serviço (SLI), e um Objetivo de Nível de Serviço (SLO) entram. Você os usará para atender às expectativas do negócio, identificando uma métrica de SLI que seja compreensível tanto para as partes técnicas interessadas, quanto para as não-técnicas. Em seguida, você definirá uma meta (um SLO) na forma de uma porcentagem simples, que mostra com que frequência você está cumprindo as suas obrigações de velocidade e qualidade.
Por exemplo, aqui estão os dados de um dos microsserviços do meu cliente, chamado B2B-Gateway. Eles coletaram dados sobre o volume de erros ao longo do tempo, como estes:
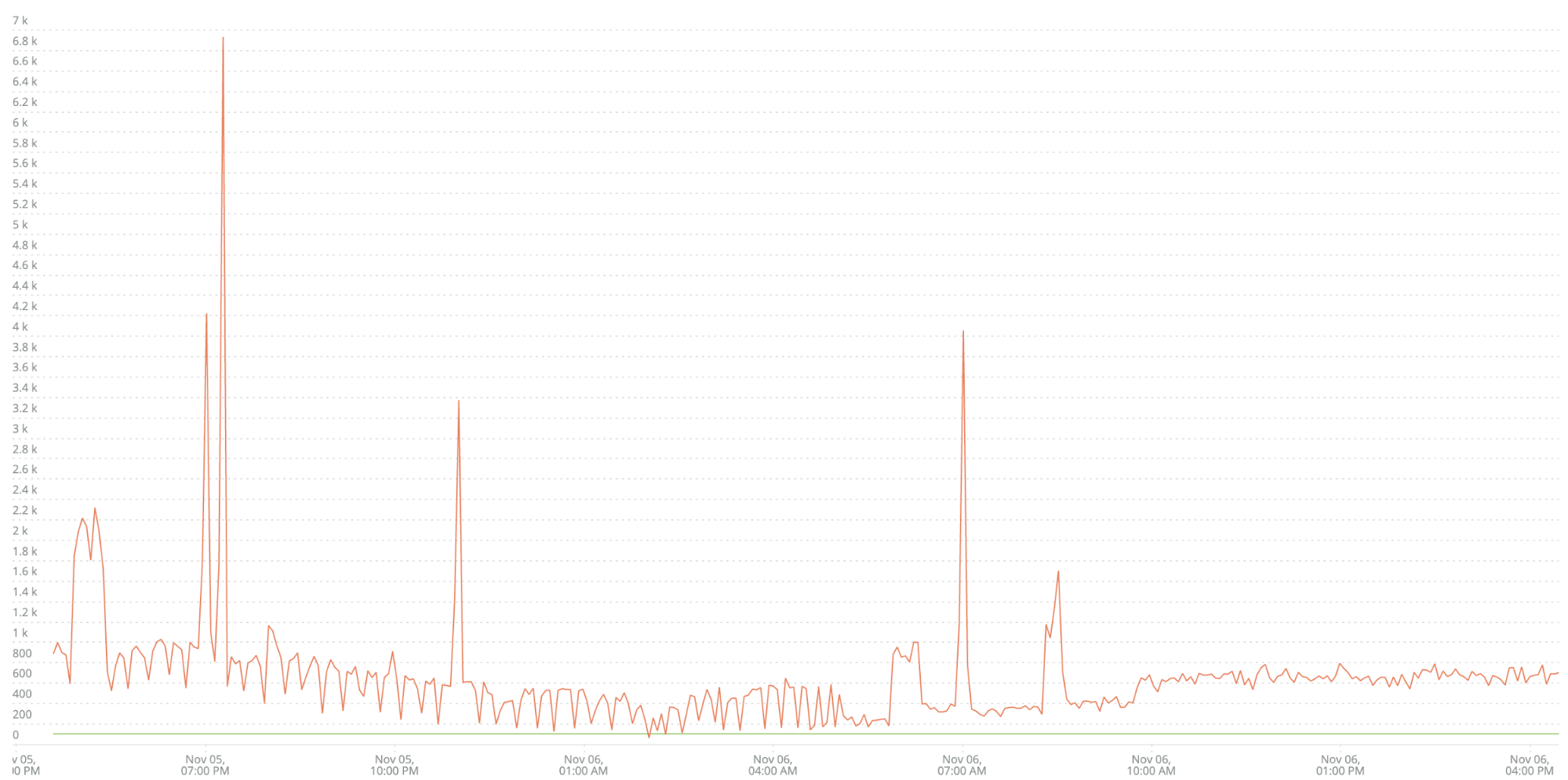
A linha verde na parte inferior é o limite de alerta do cliente. Como você pode ver, alertas são continuamente acionados para este serviço. Por causa disso, a equipe de operações parou de prestar atenção nesse alerta. Este é um ótimo exemplo de um alerta de baixa qualidade—ruído que é ignorado.
Você poderia lidar com isso da maneira tradicional, gastando muito tempo tentando definir um limite diferente ou olhando para algoritmos sofisticados de desvio do normal, mas isso ainda não mede os dois fatores principais de velocidade e qualidade. Felizmente, podemos fazer isso com apenas duas etapas.
Etapa um: identificar um SLI para medir a qualidade—a porcentagem do total de transações que estão livres de erros. Em um dashboard da New Relic, a sua consulta ficaria assim:
FROM Transaction SELECT percentage(count(*), WHERE error IS False) WHERE appName ='b2b-gateway' TIMESERIES MAX SINCE 1 day ago
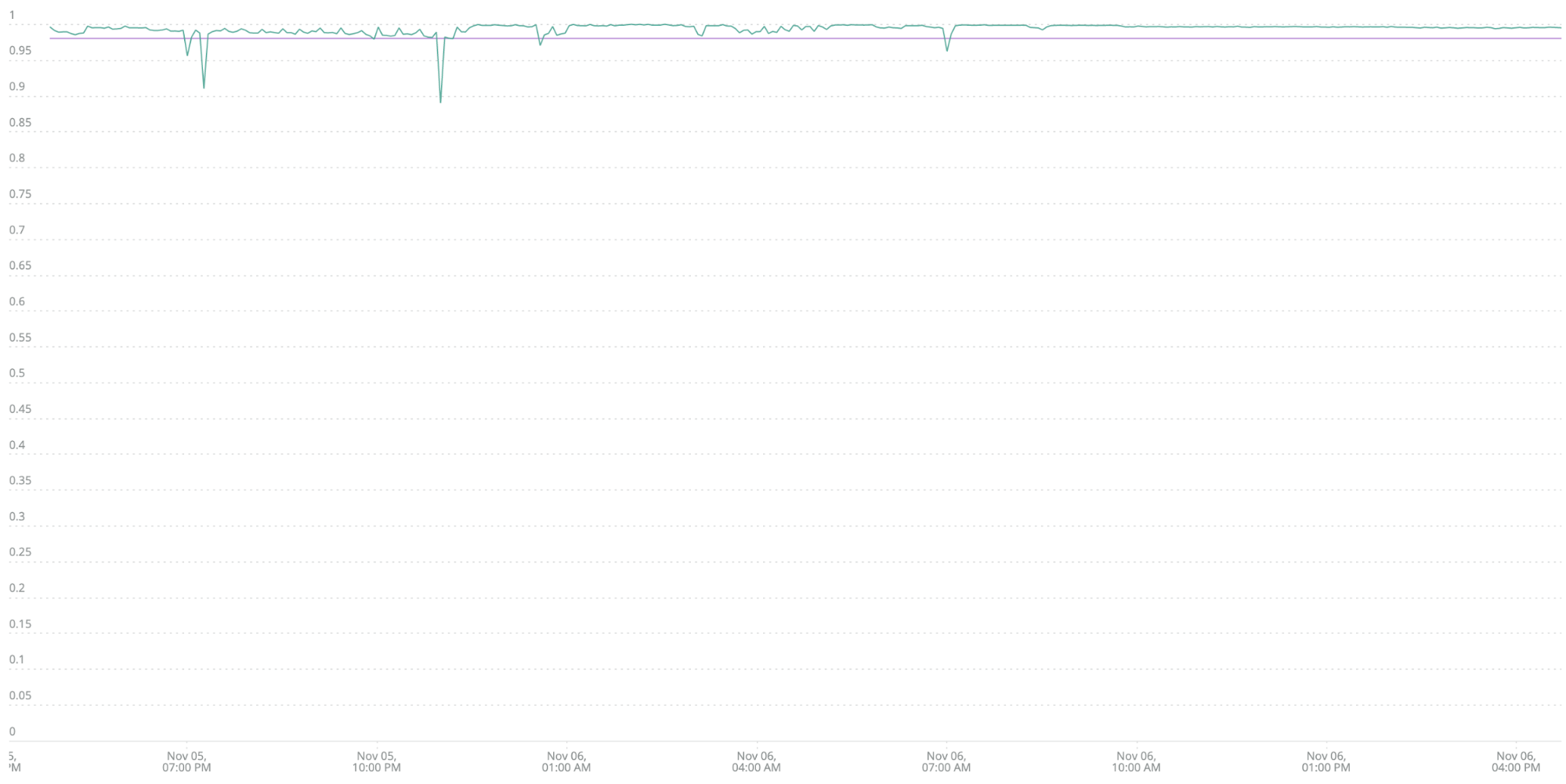
As quedas descendentes na linha mostram os problemas mais significativos. A linha horizontal roxa mostra a taxa de sucesso de 98% (o seu SLO). Qualquer coisa abaixo desse limite é um problema que requer um alerta. Há quatro casos aqui em que o seu erro SLI cai abaixo do limite de 98% (violando o seu SLO), então você receberia quatro alertas durante o dia (em contraste com um alerta, ativo 24 horas por dia, sete dias por semana, que todos ignoram).
Você acabou de atingir um grande objetivo: em uma operação simples, criou uma métrica de negócios super relevante e fácil de entender (98% das nossas transações estão livres de erros). Além disso, você transformou um alerta incômodo em um alerta valioso, com um impacto real nos negócios. É claro e óbvio que um aumento nos erros influencia a experiência do usuário.
Você pode facilmente tornar essa medição mais ou menos significativa alterando o limite do SLI. Por exemplo, se ainda estiver com muito ruído, você pode configurá-lo para 97% ou, se precisar melhorar, pode configurá-lo para 99%.
Etapa dois: Velocidade = tempo de resposta, então vamos adicionar isso à ''receita''.
Continuando com o exemplo, vamos supor que o limite de tempo de resposta do Gateway B2B seja de 100 milissegundos (0.1 segundo). (Fique ligado em nosso próximo blogpost sobre como definir limites de SLO).Para modificar a sua consulta e incluir o tempo de resposta, altere-a para ficar assim:
FROM Transaction SELECT percentage(count(*), WHERE error IS False and duration < 0.1) WHERE appName ='b2b-gateway' TIMESERIES MAX SINCE 1 day ago
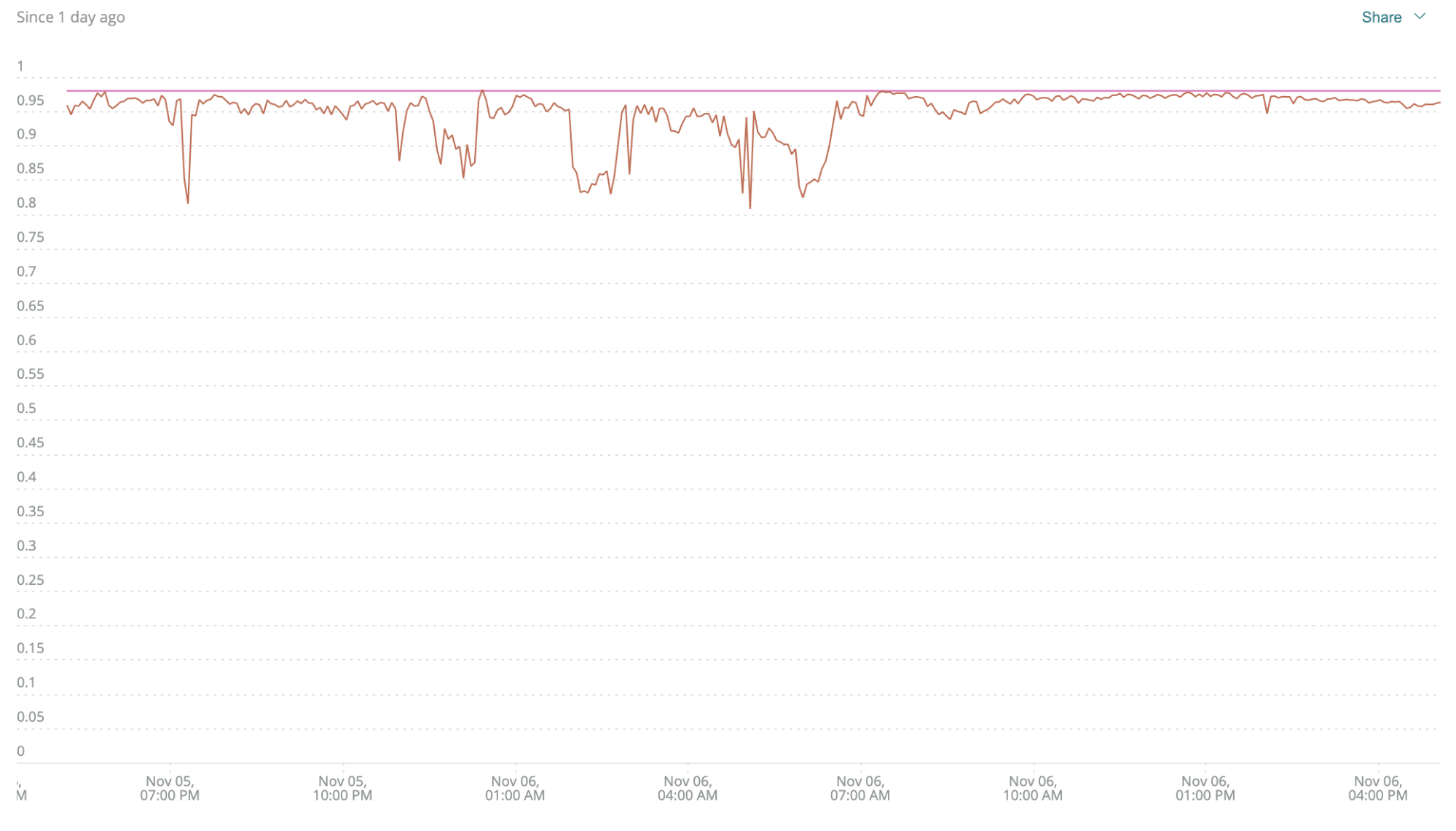
Novamente, as quedas mostram os problemas mais significativos, e a linha roxa mostra o limite de 98%. Quando você leva em consideração o desempenho, pode ver que este serviço não está indo tão bem quanto pensava. A qualidade é boa, mas o serviço não está cumprindo as suas obrigações de velocidade. Isso é algo que você nunca veria ao observar um conjunto de métricas de consumo de recursos. Isso ajuda muito a diminuir a desconexão entre a TI (cujas métricas de consumo de recursos são “perfeitamente normais”), e a empresa (que ouve falar de um serviço lento)—esta é uma grande vitória.
Para encerrar, vamos revisar os ganhos que você obterá medindo a velocidade e a qualidade, ao invés do consumo de recursos:
Forte alinhamento de negócios: você tem uma métrica de compreensão fácil e intuitiva, que conecta verdadeiramente os requisitos do negócio à tecnologia que os fornece. Métricas como essa tornam muito mais fácil ir até as partes interessadas da empresa, e dizer: “Ei, em média, cumprimos nossas obrigações de desempenho em apenas 94% do tempo, por isso precisamos fazer algumas mudanças”.
Indicadores claros de problemas: o seu SLI destacará problemas que têm impacto no negócio. Isso significa que você atrairá a atenção para problemas reais com mais rapidez, o que lhe dará uma vantagem para corrigi-los mais rapidamente, e reduzir o seu escopo e gravidade. Não se esqueça que isso também reduzirá a fadiga por alerta.
Simplicidade: os seus SLIs e SLOs (tempo e qualidade de resposta) são fáceis de entender e podem ser facilmente modificados conforme o necessário.
“Isso é bom”, você pode estar dizendo, “mas o que devo fazer a seguir?”. Comece escolhendo alguns serviços, implementando a observabilidade baseada em SLI/SLO, e comparando os resultados com o monitoramento existente. Depois de algumas semanas, você provavelmente verá que o seu SLO detecta menos problemas, porém mais críticos, e pode até destacar problemas que o seu monitoramento existente não percebeu.
Saiba mais sobre como preparar a sua equipe para um sucesso mensurável.

As opiniões expressas neste blog são de responsabilidade do autor e não refletem necessariamente as opiniões da New Relic. Todas as soluções oferecidas pelo autor são específicas do ambiente e não fazem parte das soluções comerciais ou do suporte oferecido pela New Relic. Junte-se a nós exclusivamente no Explorers Hub ( discuss.newrelic.com ) para perguntas e suporte relacionados a esta postagem do blog. Este blog pode conter links para conteúdo de sites de terceiros. Ao fornecer esses links, a New Relic não adota, garante, aprova ou endossa as informações, visualizações ou produtos disponíveis em tais sites.


