The Site Reliability Engineering (SRE) function is becoming increasingly common in a wide variety of companies. That’s why New Relic has put together a new ebook on the topic. Called Site Reliability Engineering: Philosophies, Habits, and Tools for SRE Success, the ebook combines thought leadership, best practices, and real-world learnings for companies and professionals interested in leveraging the power of SRE.
To learn more, check out these eight highlights, then read the free ebook for additional detail and insights:
1. SRE was invented at Google
The phrase “site reliability engineering” is credited to Benjamin Treynor Sloss, vice president of engineering at Google. Tasked with building a team to help ensure the health of Google’s production systems at scale, Sloss came up with the cross-functional site reliability engineering role—it’s “what happens when you ask a software engineer to design an operations function.”
2. SREs are in demand!
For site reliability engineers with the right mix of talent and experience, there are plenty of opportunities. Last year LinkedIn named SRE one of the most promising jobs in tech, and recently TechCrunch wondered, “Are site reliability engineers the next data scientists?” Job-site searches turn up tens of thousands of SRE positions, from both tech companies and legacy enterprises.
3. SRE is the purest form of DevOps
New Relic Vice President of Site Reliability Matthew Flaming says site reliability engineering is perhaps “the purest distillation of DevOps principles into a single role.” Just as in DevOps, the fundamental goal of SRE is greater reliability with less manual intervention as a system scales.
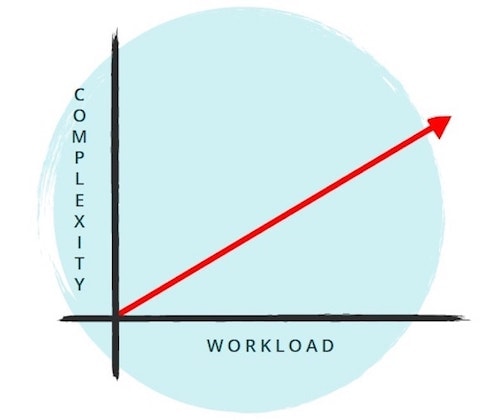
4. There are two axes of scaling
Software organizations must plan for two types, or “axes,” of scale, says Flaming. The first axis is workload—the number of physical hosts or virtual machines and other resources required to power the services that run on them. The second axis is complexity—the number of dependencies between those services and the growth of the organization itself. Site reliability engineering must support both axes of scalability.
5. SRE is all about automation
To achieve that goal, SREs rely on automation to increase the reliability of everything they touch without slowing their company’s ability to ship software quickly. According to New Relic SRE Jason Qualman, it’s all about taking the “inefficient and time-consuming things people are doing manually and putting a stop to them as soon as possible.” Maybe that’s why the word “automation” appears so often in SRE job descriptions. Don’t be surprised to see “Automate, automate, automate, and then … automate!” as a key responsibility.
6. SREs have to think big
Successful SREs have to think beyond the day-to-day and see the bigger picture, says Jason Qualman. Change often creates risks down the road, and SREs need to perform a thorough analysis of those impacts. They need to consider how their work is going to affect the rest of a particular system, team, or the larger infrastructure. “We are making decisions very low in the stack,” Qualman notes, “and those will affect people much farther up the stack.”
7. SLOs can be key to tracking reliability
Service level objectives (SLOs) are typically used to track the performance of service providers, but they can also be used in site reliability engineering to help organizations:
- Adjust high-level reliability goals to fit company strategy
- Prioritize to meet reliability goals
- Maintain and build internal and external customers’ confidence
- Help teams focus efforts on reliability
- Improve engineers’ assumptions about risk tolerance and development velocity
- Reduce unnecessary manual toil
For example, when teams consistently exceed their SLOs, they may be primed to move faster and take on more risk. But if a team is missing its SLOs, perhaps it’s time focus on reliability.
8. SRE is different in different organizations
As the SRE role expands into more and more companies, the range of what the term means is also growing. At tech giants like Google, Netflix, Amazon, and Heroku, SRE is all about hiring software engineers to do the work traditionally handled by IT operations folks. At smaller companies like New Relic, SREs are software engineers who focus on improving the reliability of our systems. That means they do everything from championing reliability best practices to guiding designs and processes toward resilience and low toil to reducing technical complexity and sprawl.
Want to learn more about Site Reliability Engineering’s operational benefits and career opportunities? Check out the new ebook Site Reliability Engineering: Philosophies, Habits, and Tools for SRE Success.
Las opiniones expresadas en este blog son las del autor y no reflejan necesariamente las opiniones de New Relic. Todas las soluciones ofrecidas por el autor son específicas del entorno y no forman parte de las soluciones comerciales o el soporte ofrecido por New Relic. Únase a nosotros exclusivamente en Explorers Hub ( discus.newrelic.com ) para preguntas y asistencia relacionada con esta publicación de blog. Este blog puede contener enlaces a contenido de sitios de terceros. Al proporcionar dichos enlaces, New Relic no adopta, garantiza, aprueba ni respalda la información, las vistas o los productos disponibles en dichos sitios.


