A version of this post previously ran on The New Stack.
Many software teams have made the jump from monoliths to microservices, and the benefits of developing apps using microservices are clear. Smaller, easier to understand services can be deployed, scaled, and updated independently. And by breaking down applications into smaller services, you have the flexibility to choose whatever technologies and frameworks work best for each component. This flexibility enables you to increase the velocity of getting software from code to production. But it also introduces greater complexity.
DevOps teams working in modern application environments are responsible for highly distributed systems where services can have many dependencies and can communicate with many other services. Add to that the complexity of each service potentially running different technologies, frameworks, infrastructure, and using different deployment mechanisms. Also, most real-world environments have a mix of legacy monolith apps running alongside newer microservices-based apps.
All this complexity can create major headaches when you have to track down and resolve issues. Take a basic e-commerce application stack, for example. When end users make an online purchase, a series of requests travel through a number of distributed services and backend databases. The path of those requests may go through storefront, search, shopping cart, inventory, authentication, third-party coupon services, payment, shipping, CRM, social integrations, and more. If there’s an issue with any one of those services, customer experience can suffer. And according to one study, a whopping 95% of respondents will leave a website or app due to a bad experience.
Cutting through the complexity
You need to troubleshoot errors and bottlenecks in complex distributed systems quickly, before customers are affected. Distributed tracing enables your teams to track the path of each transaction as it travels through a distributed system and analyze the interaction with every service it touches. This capability helps you:
- Deeply understand the performance of every service
- Visualize service dependencies
- More quickly and effectively resolve performance issues
- Measure overall system health
- Prioritize high-value areas for improvement
Fast problem resolution means you understand how a downstream service “a few hops away” is creating a critical bottleneck. Just as important, effective problem resolution means you gain insight into how to prevent reoccurrence, either by optimizing code or some other means. If you can’t determine when, why, and how an issue happens, small defects may continue to linger in production. When a perfect storm of events aligns, the system breaks all at once. Distributed tracing provides you with a detailed view of individual requests so you can see precisely what parts of the larger system are problematic.
Surfacing useful information with distributed tracing
Distributed tracing is a powerful tool, but not all traces are equally actionable. When you use a distributed tracing tool, you’re most likely trying to answer a few critical questions quickly, such as:
- What’s the overall health and performance of my distributed system?
- What are the service dependencies across my distributed system?
- Are there errors in my distributed system, and if so, where are they?
- Is there unusual latency between or within my services, and if so, what’s causing it?
- What services are upstream and downstream of the service that I manage?
When every service in a distributed system is emitting trace telemetry, even if there are only a handful of services, the amount of data can quickly become overwhelming. And the vast majority of transaction requests across a distributed system will complete without any issue, making most trace data statistically uninteresting and generally unhelpful for quickly finding and resolving problems.
Sifting through every trace to find errors or latency becomes the classic “needle in the haystack” problem. No human would be able to observe, analyze, and make sense of every trace across a distributed system in real time. You can use a distributed tracing tool to sample the data and surface the most useful information on which to take action.
Let’s take a look at a couple of different types of sampling methods for distributed tracing:
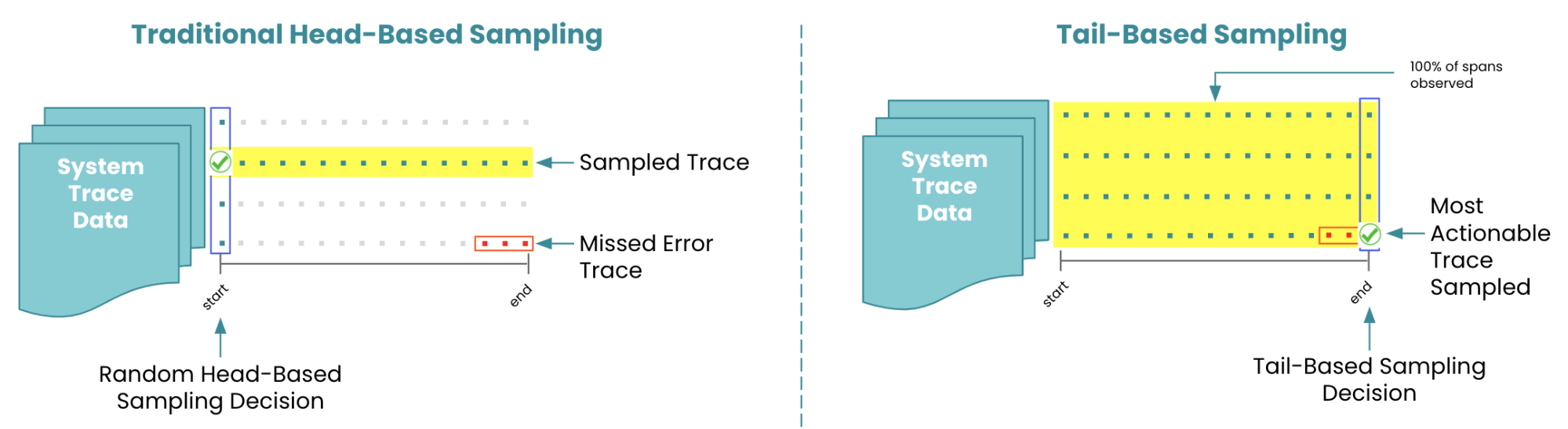
Head-based sampling overview
To process large amounts of trace data, most traditional distributed tracing solutions use some form of head-based sampling. With head-based sampling, the distributed tracing system randomly selects a trace to sample before it has finished its path through many services (hence the name “head”-based). Here are the advantages and limitations of head-based sampling:
Advantages:
- Works well for applications with lower transaction throughput
- Fast and simple to get up and running
- Appropriate for blended monolith and microservice environments, where monoliths still reign supreme
- Little-to-no impact on application performance
- Low-cost solution for sending tracing data to third-party vendors
- Statistical sampling gives you enough transparency into your distributed system
Limitations:
- Traces are sampled randomly
- Sampling is done before a trace has fully completed its path through many services so there’s no way to know upfront which trace may encounter an issue
- In high-throughput systems, traces with errors or unusual latency might be sampled out and missed
Tail-based sampling overview
In high-volume distributed systems that contain critical services, and where every error must be observed, tail-based sampling provides a solution. With tail-based sampling, the distributed tracing solution observes and analyzes 100% of traces. Sampling is done after traces have fully completed (hence the name “tail”-based). Because sampling is done after traces have fully completed, traces with the most actionable data—like errors or unusual latency—can be sampled and visualized so you can quickly pinpoint exactly where the issues are. This capability helps to solve that classic “needle in the haystack” problem. Here are the advantages and limitations of tail-based sampling:
Advantages:
- 100% of traces are observed and analyzed
- Sampling is done after traces have fully completed
- You can visualize traces with errors or uncharacteristic slowness more quickly
Limitations (of existing solutions):
- Additional gateways, proxies, and satellites are required to run sampling software
- You must endure further toil of managing and scaling third-party software
- You face additional costs for transmitting and storing vast amounts of data
Flexibility to choose
As the adoption of new technologies proliferates across the software world, application environments will continue to become increasingly complex. Your DevOps and software teams will be developing and managing apps in both monolith and microservices environments, and you will need distributed tracing tools to help you quickly find and resolve issues across any technology stack.
Not every trace is equal, and the different types of sampling for distributed tracing data each have advantages and limitations. You need the flexibility to choose the best sampling method based on the use case and cost/benefit analysis, taking into consideration the monitoring needs for each application.
Register for our Lowering MTTR with Tail-Based Trace Sampling webinar to learn how you can gain complete visibility into your distributed systems.

As opiniões expressas neste blog são de responsabilidade do autor e não refletem necessariamente as opiniões da New Relic. Todas as soluções oferecidas pelo autor são específicas do ambiente e não fazem parte das soluções comerciais ou do suporte oferecido pela New Relic. Junte-se a nós exclusivamente no Explorers Hub ( discuss.newrelic.com ) para perguntas e suporte relacionados a esta postagem do blog. Este blog pode conter links para conteúdo de sites de terceiros. Ao fornecer esses links, a New Relic não adota, garante, aprova ou endossa as informações, visualizações ou produtos disponíveis em tais sites.


