Introdução
A observabilidade transformou o mundo do monitoramento e por um bom motivo. Graças às diferentes ferramentas disponíveis, nunca foi tão fácil implementar códigos. No entanto, isso também significa que os ambientes de software estão ainda mais complexos. Com a evolução das nossas práticas de desenvolvimento de software, nossos sistemas também evoluíram. Não basta só perguntar se algo está errado no stack de nosso software, agora também precisamos perguntar por quê. Essa é a função fundamental da observabilidade.
Para obter a observabilidade, você precisa instrumentar tudo e visualizar todos os seus dados de telemetria em um só lugar. Muito se debate sobre as melhores maneiras de se fazer isso, mas na New Relic acreditamos que métricas, eventos, logs e traces (ou seja, M.E.L.T., para abreviar) são os tipos de dados essenciais da observabilidade. Quando instrumentamos e usamos M.E.L.T. para formar um conhecimento fundamental útil das conexões, ou seja, dos relacionamentos e das dependências em nosso sistema, além dos detalhes de desempenho e integridade, estamos praticando a observabilidade.
Mas, se você estiver apenas dando seus primeiros passos no campo da observabilidade, talvez o verdadeiro valor do M.E.L.T. não esteja totalmente claro. Você provavelmente já ouviu esses termos antes, mas consegue descrever com segurança as diferenças entre eles?
Começando com uma simples máquina de venda automática como referência, este guia proporcionará uma explicação de métricas, eventos, logs e traces, além de demonstrar:
- Suas diferenças
- Como saber quando usar um e não a outro
- Como são usados no New Relic, a primeira plataforma de observabilidade
Parte 1: eventos
Um evento é uma ação única que acontece em um momento específico. Então, para começarmos com nossa analogia da máquina de venda automática, podemos definir um evento para captar o momento em que alguém faz uma compra nela:
Às 15h34 de 21/02/2019, um saco de batatinhas BBQ chips foi comprado por 1 real.
Veja como esse dado de evento seria armazenado em um banco de dados:

Também podemos definir eventos para ações que não incluem um cliente, como o fornecedor abastecer a máquina ou para estados oriundos de outros eventos, como um item ficar esgotado após uma compra. Perceba que eventos são simplesmente "algo que aconteceu em algum momento".
Ao definir um evento, você pode escolher quais atributos são importantes e devem ser enviados. Não há uma regra única e simples sobre quais dados um evento pode conter. Você define o evento da maneira que achar melhor. No New Relic, por exemplo, todos os eventos têm pelo menos um carimbo de data/hora Timestamp e um atributo EventType.
Como os eventos são usados?
Os eventos são importantes porque você pode usá-los para validar a ocorrência de uma ação específica em um momento específico. Por exemplo, podemos querer saber a última vez que nossa máquina foi reabastecida. Usando os eventos, podemos observar o carimbo de data/hora mais recente do tipo de evento Refilled e responder a essa pergunta imediatamente.
Já que os eventos são basicamente um histórico de cada ação individual que aconteceu em seu sistema, você pode disponibilizá-los em agregados para responder a perguntas mais complexas na hora.
Continuando nosso exemplo do evento de compra PurchaseEvent acima, imagine que temos os seguintes eventos armazenados:
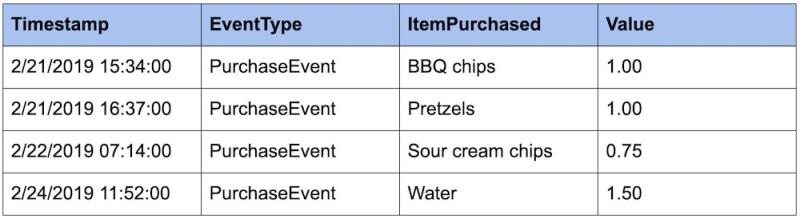
Uma pergunta comum que podemos fazer a esses dados é: quanto dinheiro eu ganhei esta semana?
Já que temos um histórico de todos os eventos de compra armazenados, basta somar a coluna Value para ver que ganhamos 4,25 reais.
Os eventos são ainda melhores quando você adiciona mais metadados a eles. Por exemplo, podemos adicionar outros atributos, como ItemCategory e PaymentType para fazermos consultas detalhadas em relação a nossos dados de PurchaseEvent.
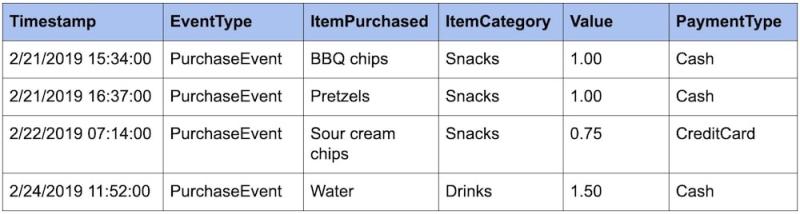
Agora, podemos fazer perguntas como:
- Quanto ganhei com cada categoria de item? (Categoria de petiscos "Snacks": R$ 2,75; categoria "Drinks": R$ 1,50)
- Com que frequência as pessoas usam métodos de pagamento diferentes? (Dinheiro, tipo "Cash": 3; cartão, tipo "CreditCard": 1).
- Quanto eu ganhei por dia? (21/02: R$ 2,00, 22/02: R$ 0,75, 23/02: R$ 0, 24/02: R$ 1,50)
Exemplo: uso de eventos no New Relic
Nesse exemplo, digamos que somos uma empresa de telecomunicações e vários clientes relatam crashes em nosso aplicativo para dispositivos móveis, o "ACME Telco Android", portanto, chegou a hora de fazermos algumas análises.
Já que implementamos o agente New Relic Mobile, que captura os dados de crashes de qualquer aplicativo sendo monitorado, podemos acessar os dados brutos do evento MobileCrash subjacentes no New Relic.
No criador de gráficos do New Relic One, realizaremos a seguinte consulta:
SELECT * FROM MobileCrash
Cada linha na tabela a seguir corresponde a um evento específico de crash que ocorreu para um usuário específico em determinado momento.
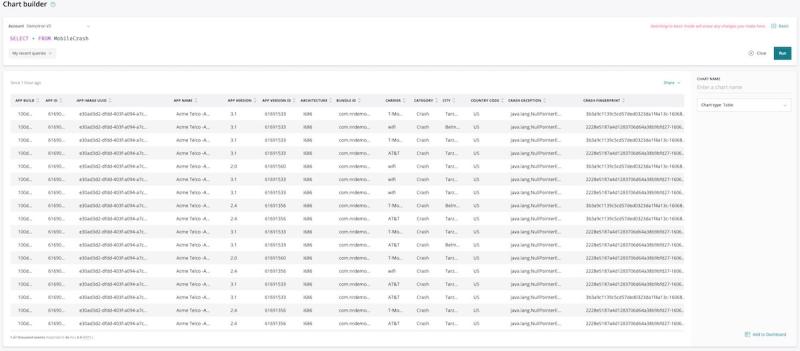
Agora, digamos que queremos fazer perguntas mais úteis sobre esses dados. Por exemplo, podemos querer saber se houve mais crashes do nosso aplicativo nos dispositivos de um fabricante específico no último dia.
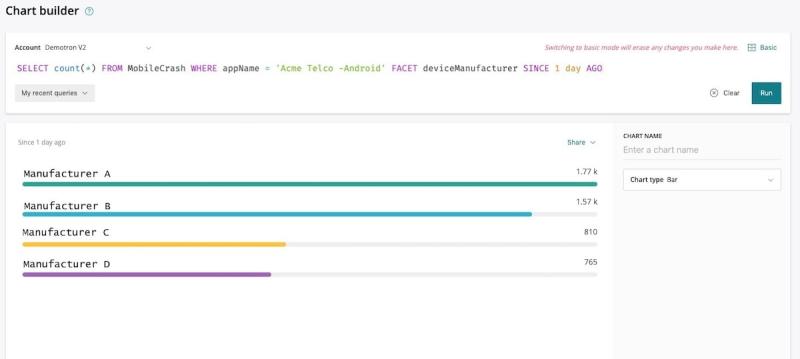
Aqui, faríamos a seguinte consulta no criador de gráficos "Chart builder":
SELECT count(*) FROM MobileCrash WHERE appName = 'Acme Telco -Android' FACET deviceManufacturer SINCE 1 day AGO
Podemos ver nos resultados que o aplicativo falhou quase três vezes mais para a linha de dispositivos de Manufacturer A no último dia.
Limitações dos eventos
Você deve estar pensando que os eventos parecem incríveis ("Vamos coletar um evento para tudo que acontece o tempo todo!"). Bom, a coleta de eventos tem o seu preço. Todo evento usa uma quantia de energia computacional para ser coletado e processado. Eles também ocupam espaço em seu banco de dados, provavelmente muito espaço. Então, para ações menos frequentes, como uma compra em uma máquina de vendas, os eventos são ótimos, mas não é recomendado coletar eventos para tudo que a máquina de vendas faz. Por exemplo, digamos que você queira ter um histórico da temperatura da máquina de vendas. Se você armazenar um evento para cada mudança minúscula da temperatura, pode encher rapidamente até os maiores bancos de dados. Por isso, é melhor coletar apenas uma amostra da temperatura em um intervalo regular. Esse tipo de dado é melhor armazenado como uma métrica.
Parte 2: métricas
Basicamente, métricas são um conjunto agregado de medidas agrupadas ou coletadas em intervalos regulares. Diferente dos eventos, as métricas não são únicas. Elas representam agregados de dados em um determinado espaço de tempo.
Há diversos tipos de agregados de métricas (por exemplo, média, total, mínimo, máximo, soma dos quadrados), mas todas as métricas geralmente compartilham as seguintes características:
- Um carimbo de data/hora (observe que ele representa um intervalo de tempo, não um horário específico)
- Um nome
- Um ou mais valores numéricos que representam um valor agregado específico
- Uma contagem dos eventos representados no agregado
Um exemplo específico de uma métrica pode ser assim:
Para o minuto 15:34-15:35 em 21/02/2019, houve um total de três compras, totalizando R$ 2,75.
Essa métrica seria representada em um banco de dados como uma única linha de dados:

Você verá com frequência diversos valores calculados em uma única linha para representar métricas diferentes que compartilham o mesmo nome, carimbo de data/hora e contagem. Neste caso, estamos monitorando o valor de compra Total, além do valor de compra médio em Average.
Observe que, se comparado a um evento, perdemos alguns dados aqui. Nós não sabemos mais quais são as três compras específicas, nem temos acesso aos seus valores individuais (e esses dados não podem ser recuperados). No entanto, esses dados demandam um armazenamento bem menor e ainda permitem que façamos algumas perguntas críticas, como "Qual foi o total de vendas em um minuto específico?"
Em um nível prático, essa é a principal diferença entre métricas e eventos, mas podemos no aprofundar nas vantagens e desvantagens deles.
Métricas versus eventos
Então, quais são os pontos positivos e negativos das métricas e dos eventos?
Eventos
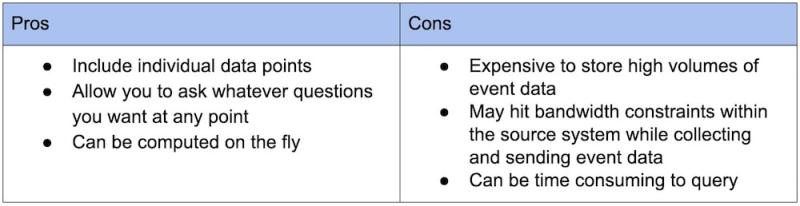
Métricas

As métricas funcionam bem para grandes corpos de dados ou dados coletados em intervalos regulares quando você sabe o que quer perguntar de antemão. Os eventos são úteis quando os dados são relativamente pequenos ou têm uma natureza esporádica ou quando você não sabe com antecedência quais agregados específicos quer ver.
Exemplo: uso de métricas no New Relic
No New Relic, o melhor exemplo de dados de métrica são taxas de erro, tempos de resposta e taxas de transferência:
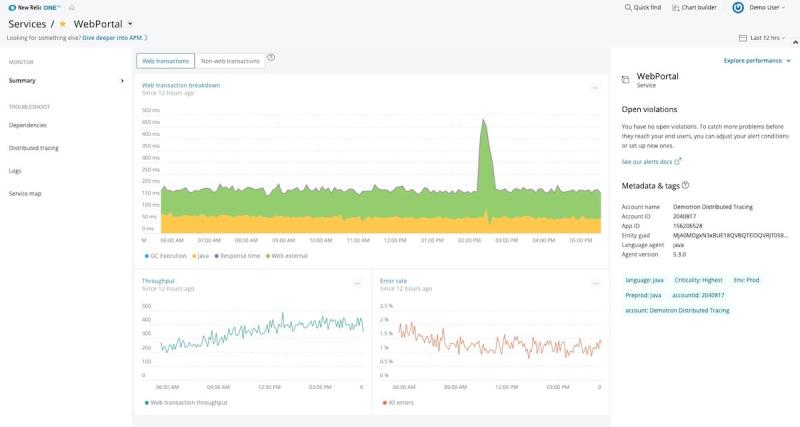
Na captura de tela acima, vemos um período de 12 horas para um aplicativo chamado "WebPortal". Está vendo como as linhas são muito irregulares? Isso indica um nível maior de fidelidade nos dados. Agora, vamos observar outro período de 12 horas para a mesma métrica, coletado há duas semanas:
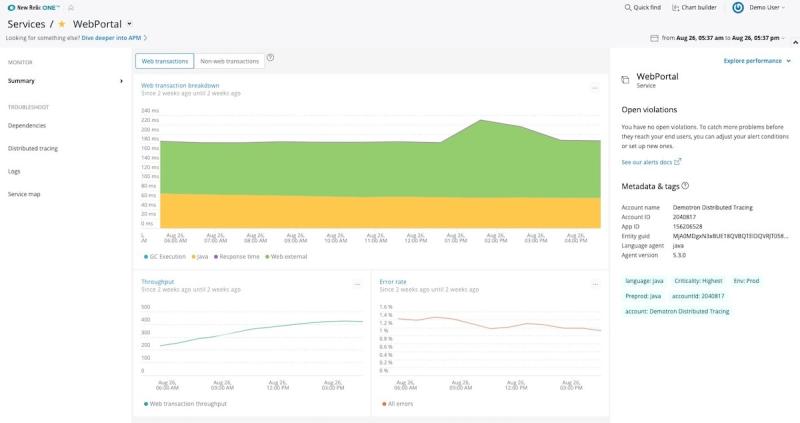
Percebeu como as linhas ficaram mais estáveis? Isso ocorre porque as métricas foram agregadas ainda mais ao longo do tempo. Quando os dados são novos, as médias representam períodos de um minuto. Porém, passado um tempo, geralmente nós não precisamos de uma granularidade tão alta. Então, as médias de um minuto são agrupadas em médias de uma hora: um ponto de dados por hora em vez de sessenta, o que economiza armazenamento, mas sacrifica um pouco da fidelidade. Já com os eventos, isso nunca é verdade. Todos os eventos individuais são armazenados até serem excluídos.
Limitações das métricas
Você obtém muitas informações em um formato muito compacto e com um bom custo-benefício. Então, por que não usamos métricas o tempo todo? Basicamente porque as métricas demandam uma tomada de decisão cuidadosa. Por exemplo, se você souber antecipadamente que quer saber o 50º percentil (mediana) e o 95º percentil da métrica que está coletando, pode instrumentar isso, coletar em todos os seus agregados e depois criar um gráfico. Mas digamos que você queira saber o 95º percentil apenas para os dados de um item específico da máquina de vendas. Você não consegue calcular isso posteriormente, pois precisaria de todos os eventos de amostra brutos para fazer isso. Então, para as métricas, você tem que tomar decisões antecipadamente sobre como quer analisar os dados e definir as configurações para dar suporte a essa análise.
Parte 3: logs
Não é exagero dizer que os logs são o tipo original de dados. Em sua forma mais fundamental, os logs são basicamente linhas de texto que um sistema produz quando determinados blocos de código são executados. Eles são muito utilizados por desenvolvedores para solucionar problemas em seus códigos e verificar e interrogar retroativamente a execução do código. Na verdade, os logs são extremamente importantes para a solução de problemas em bancos de dados, caches, balanceadores de carga ou sistemas específicos mais antigos que não são compatíveis com a instrumentalização de processos.
Assim como os eventos, os dados de log são únicos, não são agregados e podem ocorrer em intervalos irregulares. Geralmente, os logs também são muito mais granulares do que os eventos. Aliás, um evento pode estar associado a diversas linhas de log.
Vamos observar nosso evento original da máquina de vendas:
Às 15h34 de 21/02/2019, um saco de batatinhas BBQ chips foi comprado por 1 real.
Os dados de log correspondentes seriam os seguintes:
2/21/2019 15:33:14: User pressed the button ‘B’
2/21/2019 15:33:17: User pressed the button ‘4’
2/21/2019 15:33:17: ‘Tasty BBQ Chips’ were selected
2/21/2019 15:33:17: Prompted user to pay $1.00
2/21/2019 15:33:21: User inserted $0.25 remaining balance is $0.75
2/21/2019 15:33:33: User inserted $0.25 remaining balance is $0.50
2/21/2019 15:33:46: User inserted $0.25 remaining balance is $0.25
2/21/2019 15:34:01: User inserted $0.25 remaining balance is $0.00
2/21/2019 15:34:03: Dispensing item ‘Tasty BBQ Chips’
2/21/2019 15:34:03: Dispensing change: $0.00
Às vezes, os dados de log são desestruturados e, por isso, difíceis de analisar de maneira sistemática. Porém, hoje em dia é mais fácil encontrar "dados de log estruturados", formatados especialmente para serem analisados por uma máquina. Com dados de log estruturados, é mais fácil e rápido buscar os dados e deduzir eventos ou métricas com eles.
Por exemplo, se mudarmos a linha de log de:
2/21/2019 15:34:03: Dispensing item ‘Tasty BBQ Chips’
Para:
2/21/2019 15:34:03: { actionType: purchaseCompleted, machineId: 2099, itemName: ‘Tasty BBQ Chips’, itemValue: 1.00 }
Poderemos pesquisar por logs de purchaseCompleted e analisar o nome e valor do item comprado rapidamente.
Quando os logs são úteis?
Os logs são extremamente versáteis e têm muitos casos de uso. Além disso, a maioria dos sistemas de software são capazes de emitir dados de log. O caso de uso mais comum dos logs é obter um registro detalhado, passo a passo, do que aconteceu em um determinado momento.
Vamos supor, por exemplo, que temos um evento PurchaseFailed que é mais ou menos assim:

Com ele, sabemos que uma tentativa de compra falhou devido a um imprevisto em determinado momento, mas não temos nenhum atributo adicional que nos explique por que a compra falhou. Já os logs, por outro lado, mostram algo assim:
2/21/2019 15:33:14: User pressed the button ‘B’
2/21/2019 15:33:17: User pressed the button ‘9’
2/21/2019 15:33:17: ERROR: Invalid code ‘B9’ entered by user
2/21/2019 15:33:17: Failure to complete purchase, reverting to ready state
Agora sabemos exatamente o que deu errado: o usuário inseriu um código inválido.
Exemplo: logs no New Relic
Os New Relic Logs são extremamente úteis para solucionar erros assim que eles ocorrem.
Por exemplo, em nosso aplicativo "WebPortal", vemos uma mensagem de erro para uma exceção de caractere inválido:
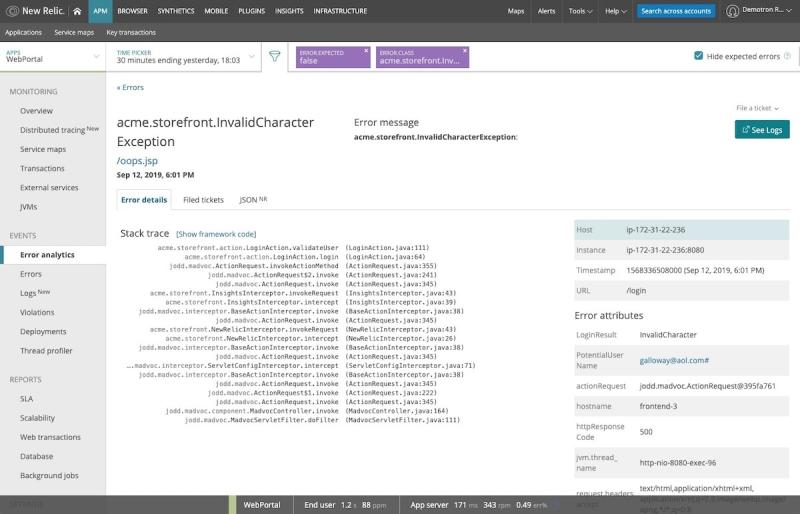
A partir daqui, podemos clicar em See Logs e o New Relic One nos apresenta os logs daquela transação de erro específica:
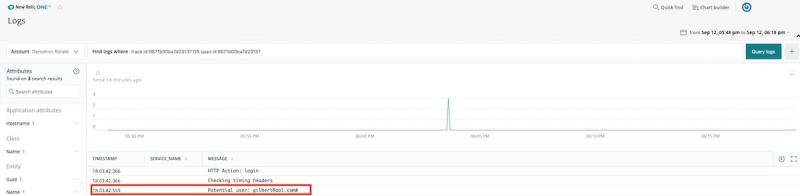
Nesse caso, vemos que o usuário passou um nome de usuário errado; ele digitou um caractere errado.
Parte 4: traces
Traces, ou mais precisamente, "traces distribuídos", são amostras de cadeias casuais de eventos (ou transações) entre componentes diferentes em um ecossistema de microsserviços. E, assim como os eventos e logs, os traces são únicos e irregulares em sua ocorrência.
Digamos que nossa máquina de vendas aceite dinheiro e cartões de crédito. Se um usuário fizer uma compra com um cartão de crédito, a transação tem que passar pela máquina de vendas através de uma conexão de back-end, entrar em contato com a empresa de cartão de crédito e depois entrar em contato com o banco emissor.
Ao monitorar a máquina de vendas, podemos facilmente configurar um evento parecido com esse:

O evento nos diz que um item foi comprado com cartão de crédito em um determinado momento e que a transação foi concluída em 23 segundos. Mas e se 23 segundos for tempo demais? Foi o nosso serviço de back-end, o serviço da empresa de cartão de crédito ou o do banco emissor que causou essa demora? Os traces foram criados para responder a perguntas como essas.
Como funcionam os traces?
A união de traces forma eventos especiais chamados "spans". Os spans ajudam a rastrear uma cadeia casual através de um ecossistema de microsserviços para uma única transação. Para isso, cada serviço passa identificadores de correlação, conhecidos como "contexto do trace" um para o outro. Esse contexto do trace é usado para adicionar atributos ao span.
Então, um exemplo de trace distribuído formado pelos spans em nossa transação de cartão de crédito seria assim:
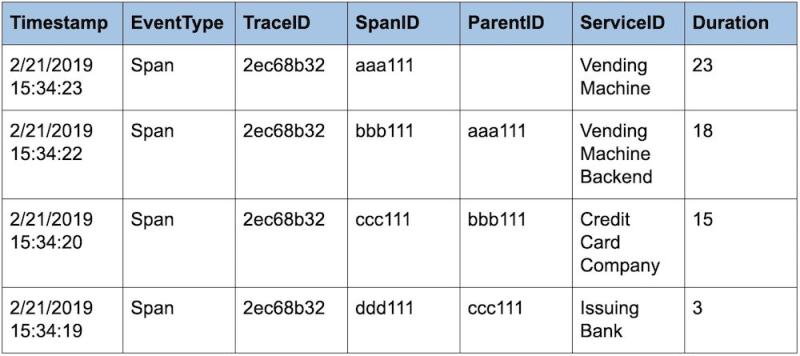
Se observarmos o carimbo de data/hora em Timestamp e os dados de duração em Duration, podemos ver que o serviço mais lento da transação é o da empresa de cartão de crédito, que está consumindo 12 dos 23 segundos, ou seja, mais da metade de todo o trace!
Como chegamos a 12 segundos? O span para entrar em contato com o banco emissor é o que chamamos de span filho, o span para entrar em contato com a empresa de cartão de crédito é seu pai. Então, se a solicitação do banco levou 3 segundos e a da empresa de cartão de crédito, 15 segundos, e nós subtrairmos o filho do pai, vemos que demorou 12 segundos para processar a transação de cartão de crédito, ou seja, mais da metade do tempo total do trace.
Quando você deve usar traces?
Os dados do trace são necessários quando os relacionamentos entre serviços/entidades são importantes para você. Se você só tivesse eventos brutos para cada serviço isolado, não conseguiria reconstruir uma única cadeia entre serviços para uma transação específica.
Além disso, muitas vezes os aplicativos chamam diversos outros dependendo da tarefa que estão tentando realizar. Eles também costumam processar dados paralelamente, então a cadeia de chamados pode ser inconsistente e os tempos podem ser duvidosos para realizar uma correlação. A única maneira de garantir uma cadeia de chamados consistente é passar o contexto do trace entre cada serviço para identificar exclusivamente uma única transação em toda a cadeia.
Exemplo: trace distribuído no New Relic
O New Relic captura dados através de seu recurso de trace distribuído.
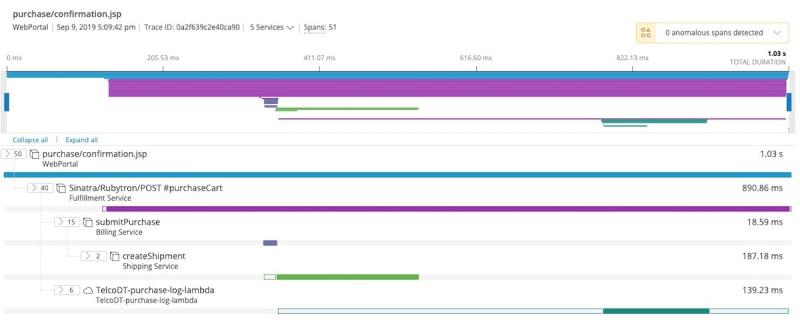
Nesse exemplo específico, nosso aplicativo "WebPortal" tem uma página chamada purchase/confirmation.jsp. Essa página chama o "Fulfillment Service", que chama o "Billing Service", que chama o "Shipping Service". Cada retângulo colorido marca quanto tempo durou uma chamada de serviço aninhada. Quanto maior o retângulo, mais tempo foi gasto naquele serviço específico.
Redefina como você pergunta "por quê?"
Independentemente de você estar apenas começando com a observabilidade ou ser um profissional de DevOps experiente, entender os casos de uso para cada tipo de dado do M.E.L.T. é essencial para desenvolver sua prática de observabilidade.
Quando entender esses tipos de dados, você compreenderá melhor como trabalhar com uma plataforma de observabilidade como o New Relic One para conectar seus dados de telemetria de código aberto ou específicos do fornecedor para entender os relacionamentos e como os dados estão conectados com sua empresa. Quando você consegue visualizar dependências e detalhar os tipos de telemetria em tempo real, resolve problemas do sistema de maneira mais rápida e fácil e evita a reincidência desses problemas em seus aplicativos e infraestrutura. É assim que você garante a confiabilidade.
Com o New Relic One, a primeira plataforma de observabilidade do setor que é aberta, conectada e programável, estamos redefinindo como você pergunta "por quê?" e o que é possível na observabilidade. E tudo isso começa com o M.E.L.T.
Software ainda mais perfeito
Experimente o New Relic One hoje para começar a criar experiências de software melhores e mais resilientes. Visite newrelic.com/platform