Introducción
La observabilidad ha transformado el mundo del monitoreo, y con razón. Gracias a la gran cantidad de herramientas disponibles, el envío de código es ahora más fácil que nunca, pero eso también quiere decir que los entornos de software son más complejos que antes. A medida que nuestras prácticas de desarrollo de software han ido evolucionando, también han evolucionado nuestros sistemas. Ya no es suficiente preguntar si algo no funciona en nuestro stack de software; también debemos preguntar por qué. Esa es la función fundamental de la observabilidad.
Para lograr la observabilidad, es necesario instrumentar todo y ver todos los datos de telemetría en un solo lugar; y hay muchos debates sobre las mejores maneras de hacerlo. En New Relic, creemos que las métricas, los eventos, los registros y los rastreos (o M.E.L.T.) son los tipos de datos esenciales de la observabilidad. Cuando instrumentamos todo y utilizamos M.E.L.T. (Metrics Events Logs y Traces por sus siglas en inglés) para crear un conocimiento práctico fundamental de las conexiones —las relaciones y dependencias dentro de nuestro sistema— además de su rendimiento y su estado detallados, estamos practicando la observabilidad.
Sin embargo, si acaba de empezar a usar la observabilidad, podría ser que el verdadero valor de M.E.L.T. no esté del todo claro. Lo más probable es que haya escuchado hablar de estos términos, pero ¿puede describir con seguridad las diferencias entre ellos?
En esta guía, usaremos como referencia una simple máquina expendedora para explicar las métricas, los eventos, los registros y los rastreos, y mostraremos:
- ¿Cuáles son las diferencias entre estos tipos de datos?
- ¿Cómo saber cuándo usar uno en lugar de otro?
- ¿Cómo se usan en New Relic One, la primera plataforma de observabilidad?
Parte 1: Eventos
Un evento es una acción discreta que sucede en un momento específico. Entonces, para comenzar con la analogía de la máquina expendedora, podríamos definir un evento para captar el momento en que alguien hace una compra en la máquina:
A las 3:34 p.m. del 21/2/2019, alguien compró una bolsa de papas fritas BBQ por 1 dólar.
Así es como se vería ese dato de evento almacenado en una base de datos:

También podríamos definir eventos para acciones que no incluyen a un cliente, como cuando un proveedor abastece la máquina, o para estados que se derivan de otros eventos, como cuando un artículo se "agota" después de una compra. Es decir, los eventos son solo "algo que sucedió en un momento determinado".
Al definir un evento, puede seleccionar los atributos importantes que se enviarán. No hay una norma estricta acerca de los datos que se pueden incluir en un evento; usted define el evento como lo desee. En New Relic, por ejemplo, todos los eventos tienen como mínimo un atributo Timestamp y otro EventType.
¿Cómo se usan los eventos?
Los eventos son valiosos porque se pueden usar para validar la incidencia de una acción en particular en un momento determinado. Por ejemplo, si queremos saber cuándo fue la última vez que la máquina fue abastecida, con los eventos, podemos ver la marca de tiempo más reciente del tipo de evento Refilled y responder a la pregunta inmediatamente.
Puesto que los eventos son básicamente un historial de cada acción sucedida en el sistema, se pueden agrupar en agregados para responder preguntas más avanzadas sobre la marcha.
Siguiendo con nuestro ejemplo anterior de PurchaseEvent, supongamos que tenemos almacenados los eventos siguientes:
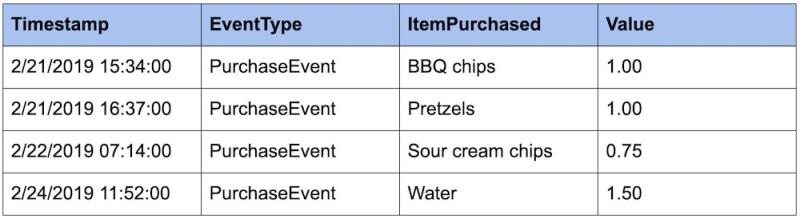
Una pregunta razonable que tal vez deseemos hacer acerca de estos datos es: ¿Cuánto dinero ganamos esta semana?
Bien, como tenemos un historial de todos los eventos de compra almacenados, podemos simplemente sumar la columna Value y ver que ganamos $4.25.
Los eventos se vuelven aún más útiles cuando les agregamos más metadatos. Por ejemplo, podríamos agregar atributos adicionales, como ItemCategory y PaymentType, para poder hacer consultas por facetas en nuestros datos de PurchaseEvent.
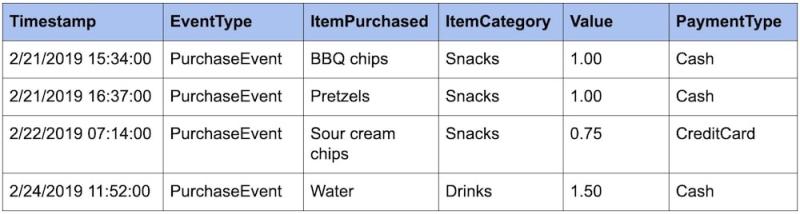
Ahora podemos hacer preguntas cómo:
- ¿Cuánto dinero obtuvimos en cada categoría? (Snacks: $2.75, Drinks: $1.50)
- ¿Con qué frecuencia se usan los distintos tipos de pago? (Cash: 3, CreditCard 1).
- ¿Cuánto dinero ganamos por día? (2/21: $2.00, 2/22: $0.75, 2/23: $0, 2/24: $1.50)
Ejemplo: Uso de eventos en New Relic
En este ejemplo, supongamos que somos una compañía de telecomunicaciones y tenemos varios clientes que nos informan sobre fallas en nuestra aplicación móvil, “ACME Telco - Android”, y es hora de que hagamos un análisis.
Debido a que hemos desplegado el agente New Relic Mobile, que capta los datos sobre fallas de las aplicaciones que monitorea, tenemos acceso a los datos sin procesar del evento MobileCrash subyacente en New Relic.
En el generador de gráficos de New Relic One, haremos esta consulta:
SELECT * FROM MobileCrash
Cada fila de la tabla siguiente corresponde a un evento de falla específico ocurrido a un usuario en particular en un momento determinado.
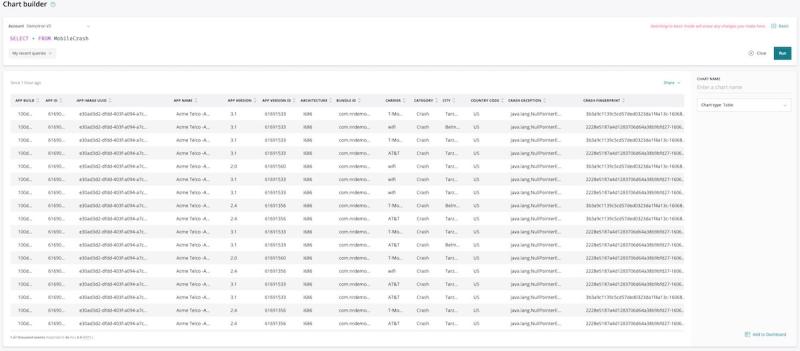
Ahora, supongamos que deseamos hacer preguntas más útiles acerca de estos datos. Por ejemplo, es probable que queramos saber si nuestra aplicación fallaba con más frecuencia en los dispositivos de un fabricante en particular durante el último día.
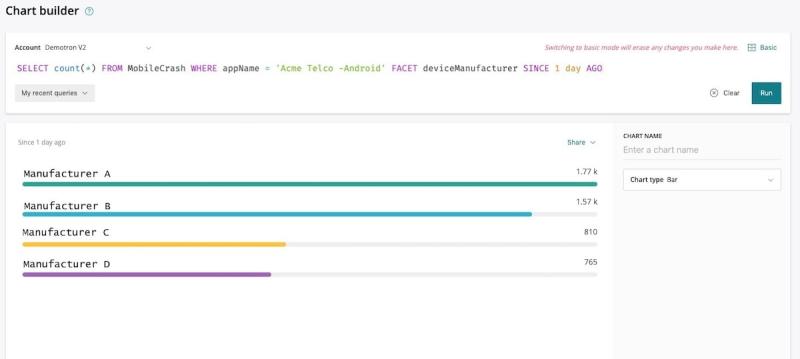
Para ello, haríamos la siguiente consulta en el generador de gráficos:
SELECT count(*) FROM MobileCrash WHERE appName = 'Acme Telco -Android' FACET deviceManufacturer SINCE 1 day AGO
Según los resultados, queda bastante claro que la aplicación falló casi tres veces más a menudo con la línea de dispositivos del Fabricante A en el último día.
Limitaciones de los eventos
Tal vez está pensando que los eventos parecen maravillosos (“¡Recopilemos un evento de todo lo que sucede en todo momento!”). Bueno, la recopilación de eventos tiene un costo. Para recopilar y procesar cada evento, se necesita cierta cantidad de energía computacional. También ocupa espacio en la base de datos; potencialmente mucho espacio. De modo que para acciones poco frecuentes relativamente, como la compra de una máquina expendedora, los eventos son ideales, pero no son recomendables para recopilar un evento de todo lo que hace la máquina expendedora. Por ejemplo, digamos que desea tener un historial de la temperatura de la máquina expendedora. Podría almacenar un evento para cada cambio minúsculo de menos de un grado en la temperatura, lo cual llenaría rápidamente incluso las bases de datos más grandes. O bien podría tomar solo una muestra de la temperatura a intervalos regulares. Es mejor almacenar este tipo de datos como una métrica.
Parte 2: Métricas
En pocas palabras, las métricas son un conjunto agregado de mediciones agrupadas o recopiladas a intervalos regulares. A diferencia de los eventos, las métricas no son discretas: representan agregados de datos durante un intervalo de tiempo determinado.
Existen distintos tipos de agregaciones de métricas (por ejemplo, promedio, total, mínimo, máximo, suma de cuadrados) pero todas las métricas suelen tener las siguientes características comunes:
- Una marca de tiempo (tome en cuenta que esta marca de tiempo representa un intervalo de tiempo, no una hora específica)
- Un nombre
- Uno o más valores numéricos que representan un valor agregado específico
- Un recuento de cuántos eventos están representados en el agregado
Este podría ser un ejemplo específico de una métrica:
Para el minuto de 3:34 a 3:35 p.m. del 21/2/2019, hubo un total tres compras por un valor total de $2.75.
Esta métrica estaría representada en una base de datos como una sola fila de datos:

Con frecuencia, verá varios valores calculados en una sola fila para representar métricas distintas que tienen el mismo nombre, marca de tiempo y recuento; en este caso, estamos haciendo el seguimiento del valor de compra Total y del valor de compra Average.
Observe que, en comparación con un evento, aquí se pierden algunos datos. Ya no sabemos cuáles fueron las tres compras específicas, ni tampoco tenemos acceso al valor de cada una de ellas (y estos datos no se pueden recuperar). Sin embargo, este dato requiere considerablemente menos almacenamiento, pero aún nos permite hacer ciertas preguntas importantes , como: “¿Cuál fue el total de ventas durante un minuto determinado?”.
A nivel práctico, esta es la diferencia principal entre las métricas y los eventos, pero podemos analizar con más detalle las ventajas y desventajas de cada uno.
Métricas y eventos
Entonces, ¿cuáles son las ventajas y las desventajas de las métricas y los eventos?
Eventos
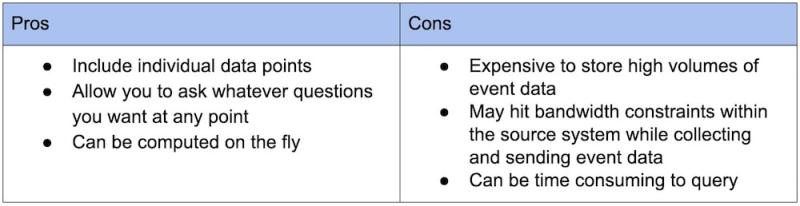
Métricas

Las métricas funcionan bien para grandes cantidades de datos o para datos recopilados a intervalos regulares cuando sabe de antemano lo que desea preguntar. Los eventos son útiles cuando la cantidad de datos es relativamente pequeña o cuando estos son esporádicos, o bien cuando no sabe de antemano los agregados específicos que desea ver.
Ejemplo: Uso de las métricas en New Relic
En New Relic, los mejores ejemplos de datos de métricas son las tasas de error, el tiempo de respuesta y el rendimiento:
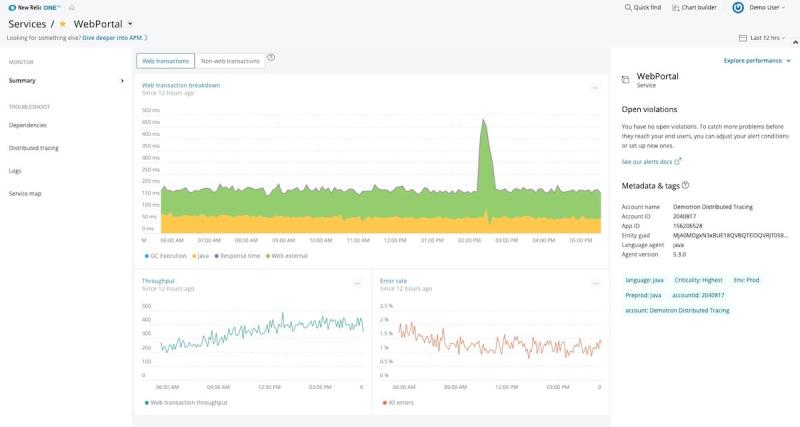
En la imagen anterior, vemos un intervalo de 12 horas para una aplicación llamada “WebPortal.” Observe que todas las líneas son irregulares. Esto indica un nivel de fidelidad más alto en los datos. Veamos ahora otro intervalo de 12 horas para las mismas métricas, recopiladas hace dos semanas:
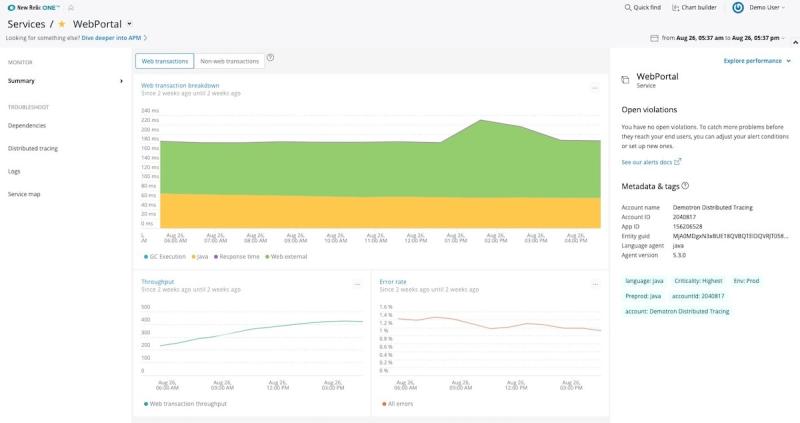
Observe que las líneas son ahora más lisas. Esto se debe a que las métricas se han agregado aún más con el tiempo. Cuando los datos son recientes, los promedios representan intervalos de tiempo de un minuto; sin embargo, pasado cierto tiempo, por lo general ya no se necesita tanto detalle. Así que los promedios de un minuto se agrupan en promedios de una hora: un punto de datos por hora en lugar de sesenta, lo cual ahorra almacenamiento, pero pierde cierta fidelidad. Con los eventos, esto nunca sucede. Cada evento individual queda almacenado hasta que se elimina.
Limitaciones de las métricas
Las métricas proporcionan mucha información en un formato muy compacto y económico. Entonces, ¿por qué no podemos usar métricas todo el tiempo? Bueno, en pocas palabras, porque las métricas exigen una toma de decisiones cuidadosa. Por ejemplo, si sabe de antemano que desea conocer el 50% (mediana) y el 95% de la métrica que está captando, eso lo podría instrumentar y recopilar en todos los agregados, para luego crear un gráfico. Pero digamos que desea conocer el 95% únicamente de los datos de un artículo en particular de la máquina expendedora. Eso no se puede calcular después de los hechos; necesitaría todos los eventos de muestra sin procesar para poder hacerlo. Entonces, para las métricas, necesita decidir previamente cómo desea analizar y configurar los datos para poder hacer ese análisis.
Parte 3: Registros
No es exagerado decir que los registros son el tipo de datos original. En su forma más básica, los registros son solo líneas de texto que un sistema genera cuando se ejecutan ciertos bloques de código. Los desarrolladores dependen mucho de estos registros para resolver problemas con el código y para verificar y cuestionar retroactivamente la ejecución del código. De hecho, los registros son increíblemente valiosos para solucionar problemas relacionados con bases de datos, memorias caché, equilibradores de carga o sistemas patentados más antiguos que no son compatibles con la instrumentación en proceso.
Al igual que los eventos, los datos de los registros son discretos —no están agregados— y pueden ocurrir a intervalos de tiempo irregulares. Los registros suelen ser también mucho más detallados que los eventos. En realidad, un evento se puede correlacionar con varias líneas del registro.
Veamos nuestro evento original de la máquina expendedora:
A las 3:34 p.m. del 21/2/2019, alguien compró una bolsa de papas fritas BBQ por 1 dólar.
Los datos del registro correspondientes podrían ser así:
2/21/2019 15:33:14: User pressed the button ‘B’
2/21/2019 15:33:17: User pressed the button ‘4’
2/21/2019 15:33:17: ‘Tasty BBQ Chips’ were selected
2/21/2019 15:33:17: Prompted user to pay $1.00
2/21/2019 15:33:21: User inserted $0.25 remaining balance is $0.75
2/21/2019 15:33:33: User inserted $0.25 remaining balance is $0.50
2/21/2019 15:33:46: User inserted $0.25 remaining balance is $0.25
2/21/2019 15:34:01: User inserted $0.25 remaining balance is $0.00
2/21/2019 15:34:03: Dispensing item ‘Tasty BBQ Chips’
2/21/2019 15:34:03: Dispensing change: $0.00
Los datos de registro a veces están poco estructurados y, por lo tanto, son difíciles de analizar de manera sistemática. Sin embargo, hoy en día es más probable encontrar "datos de registro estructurados" con un formato específico para ser analizados por una máquina. Con datos de registro estructurados, es más fácil y más rápido hacer búsquedas en los datos y generar eventos o métricas a partir de esos datos.
Por ejemplo, si modificamos la línea del registro de:
2/21/2019 15:34:03: Dispensing item ‘Tasty BBQ Chips’
a:
2/21/2019 15:34:03: { actionType: purchaseCompleted, machineId: 2099, itemName: ‘Tasty BBQ Chips’, itemValue: 1.00 }
podríamos buscar ahora purchaseCompleted en los registros y analizar el nombre y el valor del artículo sobre la marcha.
¿Cuándo sirven los registros?
Los registros son increíblemente versátiles y tienen muchos usos, y la mayoría de los sistemas de software pueden emitir datos de registro. El uso más común de los registros es para obtener una entrada detallada, paso por paso, de lo que sucedió en un momento en particular.
Por ejemplo, digamos que tenemos un evento PurchaseFailed parecido a este:

Con estos datos, sabemos que se intentó hacer una compra y no se pudo por algún motivo imprevisto en un momento en particular, pero no tenemos ningún otro atributo que nos indique por qué falló la compra. No obstante, el registro podría darnos información como la siguiente:
2/21/2019 15:33:14: User pressed the button ‘B’
2/21/2019 15:33:17: User pressed the button ‘9’
2/21/2019 15:33:17: ERROR: Invalid code ‘B9’ entered by user
2/21/2019 15:33:17: Failure to complete purchase, reverting to ready state
Ahora sabemos exactamente qué pasó: el usuario ingresó un código no válido.
Ejemplo: Registros en New Relic
Los registros de New Relic Logs son sumamente útiles para resolver errores tan pronto como ocurren.
Por ejemplo, en nuestra aplicación “WebPortal”, vemos un mensaje de error para una excepción de carácter no válido:
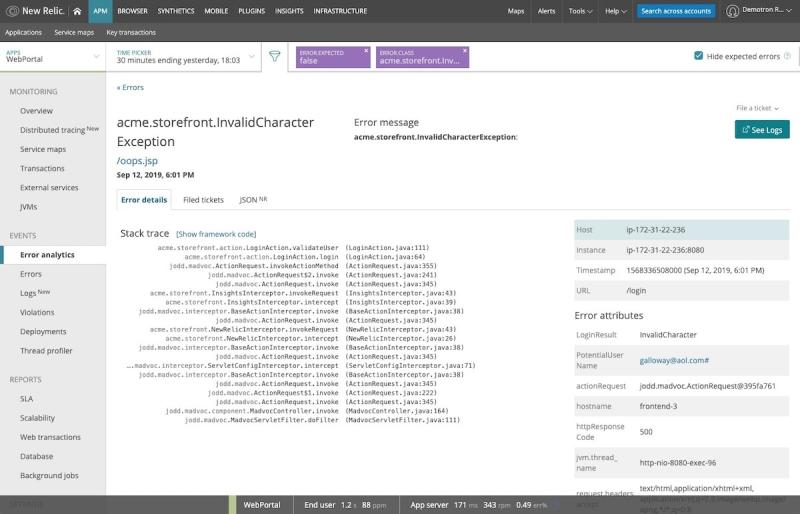
Desde aquí, podemos hacer clic en See Logs, y New Relic One nos muestra registros de esa transacción de error específica:
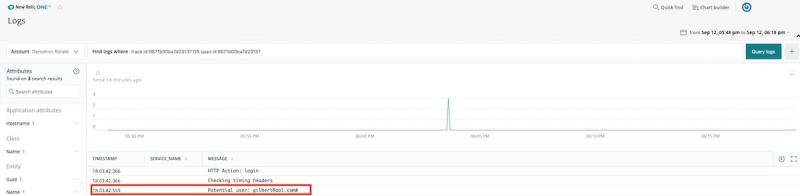
En este caso, se puede ver que el usuario escribió un nombre de usuario incorrecto, simplemente escribió mal un carácter.
Parte 4: Rastreos
Los rastreos —o más exactamente, los "rastreos distribuidos" (distributed tracing) — son muestras de cadenas causales de eventos (o transacciones) entre los distintos componentes de un ecosistema de microservicios. Y, al igual que los eventos y los registros, los rastreos son discretos y no suceden con regularidad.
Digamos que nuestra máquina expendedora acepta efectivo y tarjetas de crédito. Si un usuario hace una compra con tarjeta de crédito, la transacción tiene que pasar por la máquina expendedora a través de una conexión de backend, contactar con la compañía de la tarjeta de crédito y luego contactar con el banco emisor.
Al monitorear la máquina expendedora, podríamos fácilmente configurar un evento parecido al siguiente:

Este evento nos indica que se compró un artículo con tarjeta de crédito en un momento en particular, y que la transacción tardó 23 segundos en completarse. ¿Pero qué sucede si 23 segundos es demasiado tiempo? ¿Fue nuestro servicio de backend, el servicio de la compañía de la tarjeta de crédito o el servicio del banco emisor lo que causó la demora? Los rastreos están diseñados para responder preguntas exactamente como estas.
¿Cómo funcionan los rastreos?
Los rastreos unidos forman eventos especiales llamados “intervalos”; los intervalos ayudan a hacer el seguimiento de una cadena causal a través del ecosistema de microservicios de una sola transacción. Para ello, cada servicio pasa identificadores de correlación de uno con otro, conocidos como "contexto de rastreo" (trace context), y este contexto de rastreo se usa para agregar atributos al intervalo.
Entonces, un ejemplo de rastreo distribuido compuesto de los intervalos de la transacción con tarjeta de crédito, podría ser el siguiente:
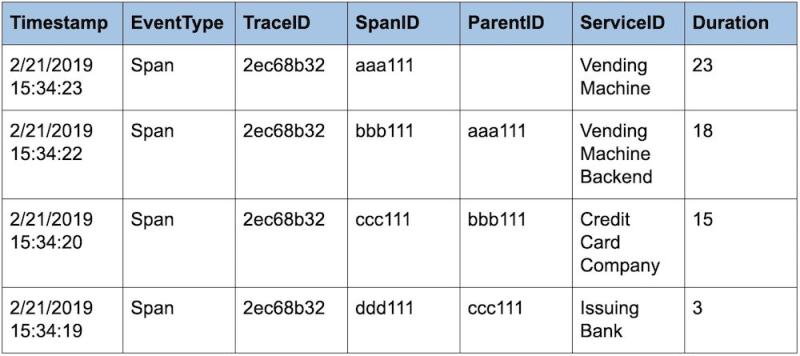
Si analizamos los datos Timestamp y Duration, podemos ver que el servicio más lento de la transacción es el de la compañía de la tarjeta de crédito: dura 12 de los 23 segundos; es decir, más de la mitad del tiempo de todo el rastreo.
¿Cómo llegamos a 12 segundos? El intervalo para contactar con el banco emisor es lo que se llama un intervalo secundario, el intervalo para contactar con la compañía de la tarjeta de crédito es el intervalo principal. De modo que si la solicitud al banco tardó 3 segundos y la compañía de la tarjeta de crédito tardó 15 segundos, y restamos el intervalo secundario del principal, vemos que fueron necesarios 12 segundos para procesar la transacción de la tarjeta de crédito: más de la mitad del tiempo total del rastreo.
¿Cuándo se deben usar los rastreos?
Los datos de rastreo son necesarios si las relaciones entre servicios y entidades son importantes para usted. Si solo tuviera eventos sin procesar para cada servicio aislado, no tendría manera de reconstruir una sola cadena entre los servicios de una transacción en particular.
Además, las aplicaciones suelen llamar a varias otras aplicaciones según la tarea que estén intentando ejecutar; con frecuencia, también procesan los datos en paralelo, de manera que es posible que la cadena de llamadas no sea uniforme y que los tiempos no sean confiables para la correlación. La única manera de garantizar que una cadena de llamadas sea uniforme es pasar el contexto de rastreo entre cada servicio para identificar de manera única una sola transacción en toda la cadena.
Ejemplo: Rastreo distribuido en New Relic
New Relic capta los datos de rastreo por medio de su función de rastreo distribuido.
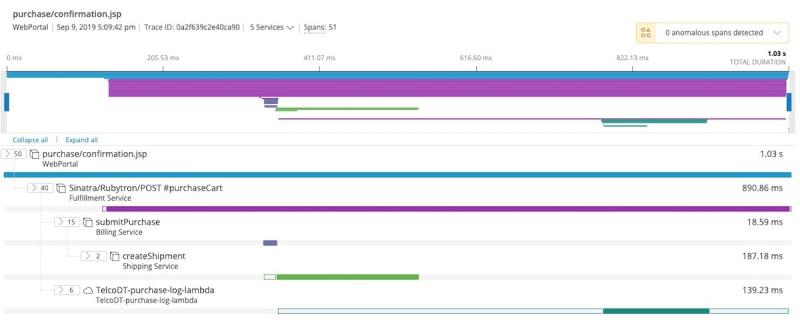
En este ejemplo específico, nuestra aplicación "WebPortal" tiene una página que se llama purchase/confirmation.jsp. Esta página llama a "Fulfillment Service", que llama a "Billing Service", que llama a "Shipping Service". Cada rectángulo de color indica el tiempo que duró una llamada de servicio anidada; cuanto más grande sea el rectángulo, más tiempo pasó en ese servicio específico.
Redefinición de cómo se pregunta "¿Por qué?"
No importa si acaba de empezar a usar la observabilidad o si ya es un profesional de DevOps con experiencia, conocer los usos de cada tipo de datos M.E.L.T. es esencial para crear una práctica de observabilidad.
Una vez que conozca estos tipos de datos, sabrá cómo trabajar mejor con una plataforma de observabilidad como New Relic One para conectar sus datos de telemetría —sean de código abierto o específicos de un proveedor— para entender las relaciones e interpretar los datos en relación con su negocio. Si puede visualizar las dependencias y ver los detalles de los tipos de telemetría, en tiempo real, podrá resolver más rápida y fácilmente los problemas del sistema y evitar que esos problemas se repitan en las aplicaciones y la infraestructura. Así es como se verifica la fiabilidad.
Con New Relic One —la primera plataforma de observabilidad del sector que es abierta, conectada y programable— estamos redefiniendo cómo se pregunta "por qué" y qué es posible hacer con la observabilidad. Y todo comienza con M.E.L.T.
Software más perfecto
Pruebe New Relic One hoy mismo y comience a crear experiencias de software mejores y más adaptables. Visite newrelic.com/platform.