Did you know the number of elite DevOps performers has almost tripled year over year? It’s becoming more and more clear that DevOps is a key pillar of any successful modernization strategy in the enterprise. DevOps Research and Assessment (DORA) recently released the 2019 Accelerate: State of DevOps Report, and we had the chance to talk to Dr. Nicole Forsgren, DORA co-founder and Google’s lead researcher for the report, about this year’s findings. The questions we received during the live chat were so rich that we wanted to share them with you—both those answered live and the ones we didn’t have time to cover during the session.
Don't miss New Relic’s take on this year’s findings in the 2019 Accelerate: State of DevOps Report.
Here are the questions from the live chat, with fresh answers from Dr. Nicole Forsgren—and a few tips from our own point of view as well:
Q: If the elite group of DevOps performers gets too big, will you have to redefine what “elite” means?

Nicole Forsgren: This is a great question. Right now, we collect questions on a log scale: that is, people are great at knowing what is happening, but in general terms, not in precise terms. People can tell you if their teams are pushing code daily versus monthly (and they won’t make a mistake about that—while mistakes in code could “roll up” to errors there). But we can’t ask people for differences in 10 seconds versus 20 seconds. So what we can do is talk about trends in the industry—we can absolutely talk about how much of the industry is able to quickly develop and deliver stable code on demand. And it’s interesting … five years ago, I was getting phone calls from highly regulated companies insisting that my research was missing them, that I needed to do a State of DevOps Report for Finance, Telecom, and Healthcare. I don’t get those calls anymore. We can see that excellence is possible for everyone. That is exciting, and this level of granularity is fine for that.
Our research continues to evolve and ask about additional practices that drive excellence and are critical to our infrastructure as well. For example, we found that only 40% of organizations are doing disaster recovery testing annually. Only 40%! So we will continue to monitor trends to see how they evolve into more advanced practices (like chaos testing) and how that impacts availability and reliability.
Q: What's the best way to be a DevOps advocate in an organization where DevOps is only thought of as build and deployment automation? Push for adoption of additional practices and habits one at a time?
NF: Exactly. Start where you are and make incremental improvements. Like the old adage says, “Don’t let perfect be the enemy of good.” Start by identifying your slowest service and take incremental steps to make it better. Prioritize the most critical issues and work your way down the list. And, most important, measure performance baselines both before and after you implement change so that you can demonstrate the impact of your efforts to the business. By sharing your successes you’ll be able to build internal support for your DevOps effort.
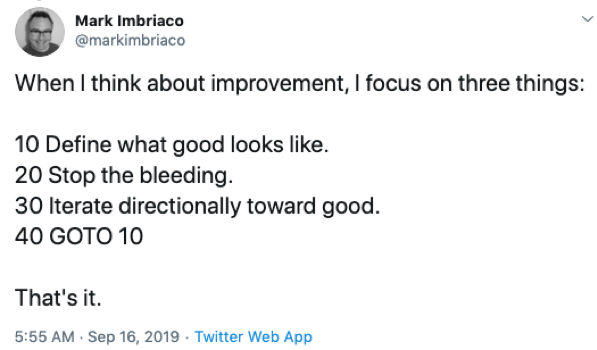
Tori Wieldt: Agreed. And we love this tweet from Mark Imbriaco of Epic Games which sums it up perfectly:
Q: How do DevOps and ITIL relate?
NF: ITIL (IT Infrastructure Library) is a practice that we’ve seen heavily adopted for a number of years, particularly within verticals that are highly regulated. ITIL was born of the best of intentions, with the notion that having stronger processes in place would lead to better stability. But what DORA research found as early as 2014, and has reconfirmed this year, is that heavyweight approval mechanisms actually lead to more delays and instability. While it came from good intentions—one more set of eyes to make sure the changes are right!—the resulting delays lead to batching of work, an increased blast radius once those changes hit production, a higher likelihood that those changes would then result in errors, and then greater difficulty in identifying and debugging the errors that were introduced (time to restore service). That is, we’ve seen that ultimately it works much better in theory than in practice.
We’re also seeing that some companies are adopting SAFe (Scaled Agile Framework), which is a great first step. But it’s important that organizations not just “land” and stay there, but continue to evolve and improve. You cannot expect to set frameworks and guidelines that will be around for another 5-10+ years. Successful DevOps requires continual improvement. We’ll also point out that ITIL is much more than change approvals. Be sure to check out this year’s report for how change advisory boards can shift into more strategic roles (page 51).
Q: What constitutes a failure? A bug? An outage?
NF: A failure is defined in the report (page 18) as a change to production or release to users that results in degraded service (e.g., a service impairment or service outage) and subsequently requires remediation (e.g., a hotfix, rollback, fix forward, or patch). We generally accept the definition that a bug is an error, fault, or flaw in any program or system that causes it to behave incorrectly; and we define an outage as unplanned system downtime.
Q: Great tools are only great if you get great adoption. What tactics do you recommend to increase adoption?
NF: Achieving great adoption ultimately ties back to several factors: Tools need to be useful, easy to use, and provide users with the right information. (Fun fact: a lot of this ties back to pieces of my dissertation and post-doc!) Employing tools that check these boxes is important as its highly correlated with quality of continuous delivery and predictive of productivity.
Geek out on Dr. Forsgren’s paper: The integrated user satisfaction model: Assessing information quality and system quality as second-order constructs in system administration

TW: Establishing Communities of Practice (COPs) within an organization can also be a great way to encourage and influence internal adoption. These could be broadly interest-based, so that participants can pick and choose which topics are relevant and useful to their job function. Then, within the group, members regularly hold trainings or “lunch and learns” to share demos or walkthroughs of the tools that they are using. We have strong COPs at New Relic, and we like to think of it as “crowdsourcing” tech information.
Q: How often do you find a strong (active) programming requirement a condition of the DevOps role?
NF: It’s certainly important. But that also depends on how you define a “DevOps role.” In any case, by its nature, the approach of DevOps is intended to apply an “engineering lens” to traditional operations, allowing ops work to be more repeatable and more performant, or to apply an appreciation for operations concerns like reliability and scalability to development work. Both of those require some programming skills. The importance is in the overlap and extensibility of the work.
TW: We agree that a solid technical background is a requirement for good DevOps work. You’ll need to do some level of programming for automation. We recently compiled key questions to prep for in a DevOps interview, and many of them focus on highlighting examples of technical and collaborative projects the candidate has worked on, as well as any skills or certifications the candidate has earned. Our blog on the typical Day in the Life of an SRE, penned by our own Yonatan Schultz, also demonstrates why the need for a broad technical background is so important to success in a DevOps role.
Q: Can you talk more about "pre-mortem"—why is it different from CAB?
TW: CAB stands for “Change Advisory Board,” which in some organizations is a group of two to three senior engineers who are tasked with the job of approving code for production, with the goal of minimizing risk. Here at New Relic, we previously employed a CAB but eventually found it to be too much of a bottleneck and a hurdle to agility. Instead, we’ve now implemented an automated “pre-flight check” for all code changes, which allows us to move much faster.
A pre-mortem, on the other hand, is an exercise in which your stakeholder group holds a brainstorming session about a particular project (or infrastructure or services) before it deploys and envisions all the things that could possibly go wrong with it. This is a fantastic opportunity to lay out a solid game plan and minimize the things that could go wrong well before the adrenaline kicks in on launch day.
Check out the report and webinar now
Thanks to all our participants for such great questions! Watch the webinar on-demand and download this year’s State of DevOps report in full. For more great DevOps content, be sure to visit out our resources page or check out our upcoming webinars.

이 블로그에 표현된 견해는 저자의 견해이며 반드시 New Relic의 견해를 반영하는 것은 아닙니다. 저자가 제공하는 모든 솔루션은 환경에 따라 다르며 New Relic에서 제공하는 상용 솔루션이나 지원의 일부가 아닙니다. 이 블로그 게시물과 관련된 질문 및 지원이 필요한 경우 Explorers Hub(discuss.newrelic.com)에서만 참여하십시오. 이 블로그에는 타사 사이트의 콘텐츠에 대한 링크가 포함될 수 있습니다. 이러한 링크를 제공함으로써 New Relic은 해당 사이트에서 사용할 수 있는 정보, 보기 또는 제품을 채택, 보증, 승인 또는 보증하지 않습니다.


