
Introduction: The agentic AI era
If you're a developer in 2026, you've probably noticed something shifting. The applications you're building or being asked to build, are fundamentally different from what you worked on even two years ago. They don't just respond to requests anymore. They think. They plan. They act.
Welcome to the agentic AI era.
Let's be direct here: agentic AI systems are not a nice-to-have anymore. They're quickly becoming integral to modern applications. Your company's chatbot can now browse documentation, call APIs, query databases, and make decisions about what to do next. Your recommendation engine isn't running a fixed algorithm. It's a mesh of AI agents collaborating to understand user intent, retrieve context, and generate personalized suggestions in real-time.
And here's the kicker: you're responsible for building and keeping these systems running.
The problem? Traditional software engineering practices don't translate cleanly to agentic systems. You can't just write unit tests and call it a day. You can't predict every edge case because the system is non-deterministic by nature. The same input can produce different outputs. An agent might hallucinate. A tool call might fail. One agent's mistake can cascade through your entire system, and you won't know until a user complains, or worse, until your CEO asks why the AI just cost the company $50,000 in wasted API calls.
This isn't theoretical. According to recent industry research, high-impact outages now cost a median of $2 million per hour. That's over $33,000 for every minute your systems are down. When your agentic system fails, the clock is ticking, and without proper observability, you're flying blind.
The shift from deterministic to probabilistic systems
As a developer, you're used to deterministic systems. You write code, it executes the same way every time. If a function receives the same input, it returns the same output. Debugging is logical: follow the stack trace, find the bug, fix it, deploy. Done.
Agentic AI systems obliterate this mental model. These systems are probabilistic. An LLM might decide to call different tools based on subtle variations in its reasoning. A retrieval system might surface different documents depending on semantic similarity scores. A multi-agent workflow might take completely different execution paths based on how agents interpret their instructions. But these aren't bugs. These are the features that make these agentic systems powerful and adaptable. But it also makes them incredibly difficult to understand, debug, and maintain without the right observability infrastructure.
Consider a simple example: You have a customer support agent that's supposed to look up order information and provide shipping updates. Sometimes it works perfectly. Sometimes it tells users their order doesn't exist when it clearly does. Sometimes it just... times out.
With traditional logging, you might see:
[INFO] User query received: "Where is my order #12345?"[INFO] LLM call completed in 2.3s[ERROR] Database query failed
Great. But why did the database query fail? What did the LLM decide to do? Which tool did it try to call? Was the prompt well-formed? Did it hallucinate a different order number? Did another agent in your system interfere? You have no idea.
This is why understanding both how to build these systems and how to observe them from day one is critical. You can't bolt on observability after the fact. It needs to be part of your architecture from the start.
The cost of poor observability
Let's talk real numbers. When agentic systems fail without proper observability:
- Mean Time to Resolution (MTTR) skyrockets: Engineers spend hours or days trying to reproduce issues that are inherently non-deterministic
- Token costs spiral out of control: A single misconfigured agent can burn through thousands of dollars in API calls before anyone notices
- Quality degrades silently: Hallucinations and cascading errors slip through because you can't see what's happening inside your agent mesh
- Security vulnerabilities go undetected: Prompt injections and PII leakage happen in production, and you only find out when it's too late
The $2 million per hour figure we mentioned? Aside from downtime, that includes lost revenue from broken user experiences, wasted compute and API costs from runaway agents, engineering time spent debugging without proper tools and reputation damage. The cost adds up fast, and without visibility into what your agents are actually doing, you're constantly playing catch-up.
What You’ll Learn
This guide is a strategic blueprint for developers transitioning from traditional, deterministic software to the probabilistic world of agentic AI. While the landscape is moving fast, the core architectural challenges remain constant: how do we build systems that can reason, and how do we ensure they don't fail silently?
In the following sections, we will:
- Deconstruct the Agentic Shift: Understand why "unit testing and calling it a day" no longer works for systems that think and plan.
- Analyze the Anatomy of an Agent: Break down the five core pillars—LLMs, Tools, Retrieval, Memory, and Orchestration—and how they interact to move from "chat" to "action."
- Quantify the Cost of Invisibility: Look at the real-world financial and operational risks of deploying agents without a "Day 1" observability strategy.
Identify the "Probabilistic Gap": Learn to spot the difference between a technical failure (a 500 error) and a logical failure ( an LLM hallucinating a tool call).
Agentic systems 101
Before we dive into building and monitoring agentic systems, let's make sure we're all on the same page about what we're actually talking about. If you've been hearing buzzwords like "AI agents," "agentic workflows," or "autonomous systems" thrown around and wondering what makes them different from a regular API call to ChatGPT, this section is for you. But if you're already familiar with the basics, feel free to skip ahead.
The Spectrum of LLM Applications
LLM applications span from simple text generation to autonomous agents, transforming how data is processed, analyzed, and generated across industries. The spectrum moves from narrow, single-task applications to complex, multi-step agentic workflows.
- Content generation
At the simplest level, LLMs are used to generate content. This includes writing text such as blogs, emails, and scripts, generating code, or helping debug existing code. Each request is independent, and the system does not maintain context or take action beyond producing output. - Summarization and analysis
In the next stage, LLMs are used to analyze existing content. This includes summarizing long documents, extracting key points, classifying text, or performing sentiment analysis. The model processes information, but it does not interact with external systems or make decisions. - Conversational systems
Conversational systems add interaction and context. These systems maintain conversation history and respond over multiple turns. While they feel interactive, they still primarily generate text and do not act autonomously. - Retrieval augmented systems
Retrieval augmented systems connect LLMs to external data sources. Instead of relying only on the model’s training data, they retrieve relevant documents or records at runtime and use them as context. This improves accuracy and allows the system to answer domain specific questions, but the model still does not own the workflow. - Agentic systems
Agentic systems represent the final step. These systems are goal driven and autonomous. The LLM decides what to do next, calls tools such as APIs or databases, updates state, and continues until a task is complete or stopped.
This guide focuses on agentic systems, because that's where developers face the most challenges around architecture, reliability, and observability.
What is an agentic system?
Let’s try to understand the agentic system using a simple, hypothetical example of a restaurant assistant:
Traditional conversational systems:
User: "Find me a good Italian restaurant for 4 people tonight at 7pm."LLM: "I'd recommend looking for Italian restaurants in your area that can accommodate 4 people."End of interaction.
Agentic system:
User: "Find me a good Italian restaurant for 4 people tonight at 7pm."Agent: Determines it needs restaurant options that match cuisine, rating, party size, and time.Agent: Calls a restaurant search toolAgent: Receives a list of Italian restaurants with ratings, hours, and reservation support.Agent: Filters by rating and checks availability for 7pm.Agent: "I found Bella's Italian Bistro (4.5 stars). They have a table at 7pm for 4. Should I book it?"User: "Yes"Agent: Calls the reservation tool to create the booking.Agent: "Done! Confirmation #BR-2847."Goal accomplished autonomously.
The key difference? In traditional LLM-driven conversational systems, the system provides advice but takes no further action. The agentic system, on the other hand, runs in a loop: it decides what it needs, takes action, checks the result, and continues until the task is complete. The LLM becomes a decision-maker inside a workflow that can interact with real systems using tools, retrieving information, and maintaining memory of what's happened. And these are the characteristics that make systems “agentic”.
Agentic systems may feel magical from the outside, but under the hood, they are composed of a few core architectural components that work together to turn a high level goal into concrete actions. Each component plays a specific role, and understanding these roles is essential before you can reason about reliability, cost, or observability.
Core architectural components
To understand the core architectural components involved in building agentic systems, let’s look at a very high level architecture of the restaurant agent, inspired by the augmented LLM building block described by Anthropic.
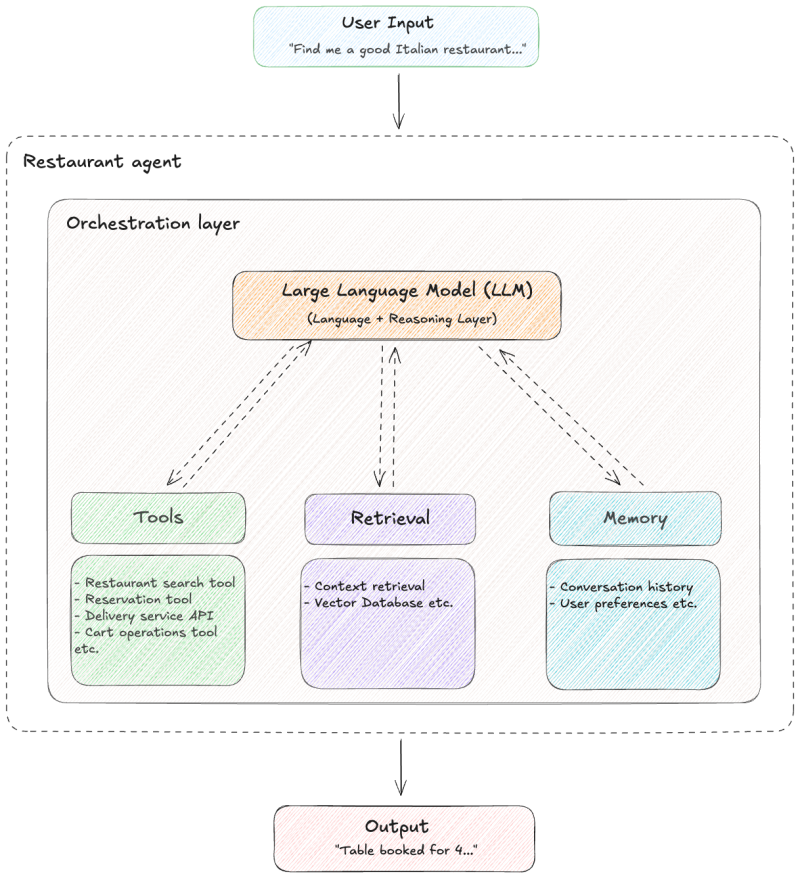
The diagram shows the high-level structure of a restaurant agent. The LLM sits at the center as the decision making core, while orchestration manages the execution loop around it. Through this loop, the LLM can access tools, retrieval, and memory; the three capabilities it uses to achieve its goals.
Let's break down each component in detail.
LLM (Language & Reasoning Layer)
At the heart of every agentic system is a Large Language Model. This is the decision making core of the system that interprets user intent, reasoning about the problem, deciding what actions are needed, and generating outputs that drive the rest of the workflow. For example, in our restaurant agent, when a user says "Find me Italian food for 4 people tonight," the LLM reasons about the constraints and determines the next steps, such as searching restaurants, filtering by cuisine, checking availability, and presenting options.
Most production systems rely on hosted LLM APIs such as those provided by OpenAI (GPT-5.2, GPT-4), Anthropic, or Azure OpenAI. Some organizations also use open source models like Llama or Mistral when data control or deployment constraints require it.
However, from a developer's perspective, it is important to understand what the LLM is not. It does not execute business logic, enforce correctness, or guarantee consistent behavior. Its outputs are probabilistic, and the same input can lead to different decisions. The LLM also has no direct access to real systems. Without the surrounding architecture, it cannot fetch data, store state, or take action. For this reason, the LLM should be treated as a reasoning engine, not the system itself.
Tools
Tools are how an agentic system interacts with the real world. While the LLM decides what to do, tools are responsible for actually executing those decisions. For a restaurant agent, for example, a tool might be an API call to get restaurant data, database queries to look up menus, an internal service call to the reservation system, a payment action, or any other piece of executable code. Without this layer, an agent can reason, but it cannot act.
In practice, tools are exposed to the LLM as well defined functions with clear names, descriptions, and input schemas. The orchestration layer presents these tools to the model, and the model selects which one to use based on the goal it is trying to achieve. Once selected, the tool execution layer runs the underlying code and returns the result back into the agent’s context. This result may end the workflow or become input for further reasoning steps.
Modern LLMs like GPT-4 and Claude support native function calling, which makes this interaction straightforward. The important distinction is that tools perform actions, not the model. This separation keeps execution predictable and allows real systems to remain under programmatic control.
Retrieval
Retrieval is used when the system needs additional context from unstructured data. This typically includes free form text such as reviews or descriptive information. For example, the restaurant agent could use it to search restaurant reviews for qualities like "romantic atmosphere" or "good for groups," find menu items by description, explain why one restaurant is preferred over another, or recall relevant past conversations. Retrieval allows the agent to search a corpus, pull relevant snippets, and include them as context for reasoning or explanation. This pattern, Retrieval Augmented Generation (RAG), grounds responses in actual data. Retrieved content supports decision making, but it is not required for every request and should not replace authoritative data sources such as databases or APIs.
Memory
Memory allows the agent to maintain continuity across steps and interactions. It captures relevant context such as user preferences, previous decisions, and intermediate results, so the system does not start over on every model call.
Memory typically lives outside the LLM and is injected into prompts when needed. Short term memory usually includes recent conversation history or recent reasoning steps that must be preserved across calls. Long term memory may store user preferences, historical interactions, or domain knowledge that should persist across sessions. These memories are often stored in databases, key value stores, or vector databases, depending on whether exact recall or semantic recall is required. The orchestration layer decides what memory is relevant and how much of it to include, balancing context size, cost, and usefulness.
In practice, agentic systems require careful management of memory. An agent might forget crucial context mid-conversation, leading to confusing responses. Or it might accumulate so much history that it becomes slow and expensive to run. Hence, effectively managing memory is one of the trickier aspects of building reliable agentic systems.
Orchestration layer
The orchestration layer is what turns an LLM into an agent. Think of it as the operating system for your agentic system. It sits between the LLM and the rest of your system and controls how decisions are made, executed, and chained together. The orchestration layer is responsible for constructing prompts, injecting context, exposing tools to the model, and enforcing execution order. While the LLM reasons, orchestration governs control flow.
Most agentic systems use an orchestration framework such as LangChain, LlamaIndex, AutoGen etc. These frameworks provide abstractions for agents, tools, memory, and workflows, reduce boilerplate and speed up development.
From a production perspective, many real world issues originate here. This layer is where intent becomes action. Small changes in context, ordering, or tool availability can lead to different execution paths. Furthermore, a poorly structured prompt, missing context, or incorrectly defined tool schema can cause the model to make the wrong decision while still returning a valid looking response. Because the failure is logical rather than technical, it often bypasses traditional error handling and is hard to detect. Which is why observability at this layer is critical.
Taken together, these components form the foundation of an agentic system. The LLM provides reasoning, orchestration controls the flow, tools execute actions, retrieval adds context when needed, and memory preserves progress across steps. Every agentic system, regardless of scale or domain, is built from some combination of these pieces.
By mastering these five architectural pillars, you move beyond treating AI as a 'black box' and begin treating it as a manageable, observable system. You are now equipped with the mental model required to architect agentic workflows that are not just powerful, but predictable.