はじめに
コンテナって何を監視すればいいの?誰もが一度はそう疑問を持ったことがあると思います。私もそうでした。
皆さんはなぜコンテナを採用するのでしょうか?デジタルビジネスの変革スピードに対応するため?マイクロサービス化を推進しやすくするため?ビルド・デプロイの自動化をしやすくするため?時代の流れがそうなっているから?。様々な理由があると思います。採用理由については色々な理由や経緯があって当然なので、ここではその良し悪しについての議論はしません。しかしながら、この疑問に答えるにあたって重要なのは、本番環境でコンテナを動かすにはどういった構成で動かすものなのかを理解する、ということです。
本Postでは、これを整理することでコンテナの監視を行う際の重要なポイントを整理することを目的としています。なお、具体的にNew Relicでどう実現するかについては、個別のブログ記事や公式ドキュメントを参照してください。
コンテナの課題とオーケストレーションの必要性
そもそもコンテナとは?という話はすでに情報が溢れていますので、詳細解説はそちらにお任せします。ただ、コンテナは、あくまでサーバーの上で動くプロセスなので、本番環境で可用性を実現するために冗長化しようとすると課題が出てきます。また、マイクロサービスのように、多数のサービスが相互に通信しようとなると、負荷分散や名前解決などの新たな問題が発生します。
課題1: 冗長化による課題
本番環境では、一部のコンテナが停止してもサービスが停止しないように複数のコンテナを起動しておこう、となると思います。しかし、同一のサーバーに複数のコンテナが起動していると、サーバーがダウンした際にサービスが停止してしまいます。そうならないように、複数のサーバーに分散してコンテナを配置したくなります。コンテナの可用性を設計したいのに、サーバーの可用性も考慮して設計する必要があります。
課題2: サービス間通信の確保の課題
マイクロサービス化などによりたくさんのサービスが相互に通信してサービスを構成するようになると、冗長化も考慮すると様々なコンテナが様々なサーバ上に配置されます。しかも、アプリケーションを更新・デプロイするたびにその場所が変わる可能性もあります。つまり、どこになんのサービスのどのコンテナがあるのか?を、常に管理し続けてあげる必要があります。
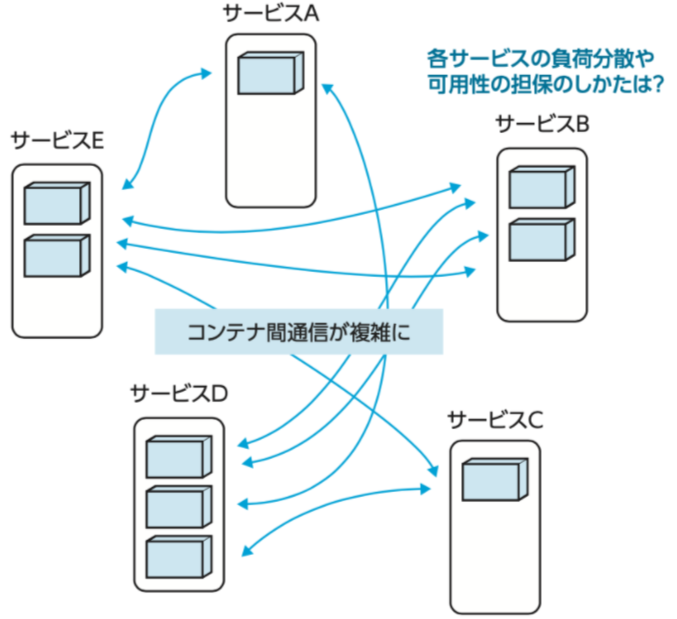
これらの課題は、少ない数のサービスや変更頻度の少ないコンテナを管理する際には問題視されないかもしれません。しかしながら、本来の目的であるビジネススピードを上げるためにマイクロサービス化したり、素早くデプロイするために自動化などを行おうとしている場合、これらを継続的にやり続けるのは負荷がかかります。
このような課題を解決するのがオーケストレーションと呼ばれるレイヤーです。オーケストレーションサービスは、これらの課題を解決するために、複数のサーバーを束ねてクラスター化し、そのクラスター上でよしなにコンテナを分散配置して名前解決させ、ロードバランシングする機能を兼ね備えています(当然これ以外にたくさんの機能がありますが本Postでは割愛します)。AWSだとAmazon Elastic Container Service(Amazon ECS)やAmazon Elastic Kubernetes Service(Amazon EKS)がそれに該当します。
オーケストレーションサービスの構成要素
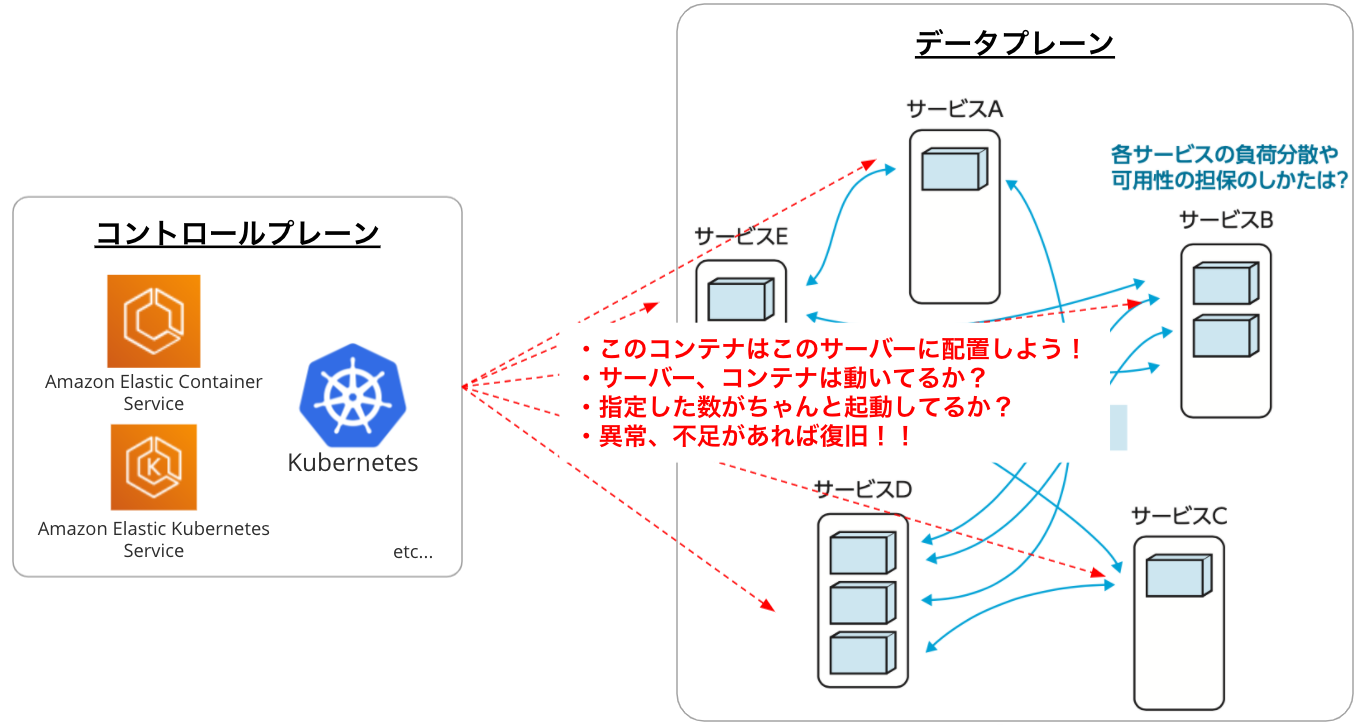
オーケストレーションサービスは、コンテナをよしなに管理するコントロールプレーンと、実際にコンテナが稼働する箱であるデータプレーンから構成されます。利用者は、どんなコンテナをどのくらいのリソース量で何個起動するか、といった条件を定義してコントロールプレーンに依頼するだけで、コントロールプレーンは、どのサーバにコンテナを配置すれば良いか、などを自動的に判断して配置・起動してくれます。また、指定された通りのコンテナがちゃんと起動できているかも監視し、異常あれば停止したり、再起動までしてくれます(これを自己修復性などと言ったります)。
監視の基本的な考え方
ここまでで、コンテナアプリケーションを本番環境で安定的に可用性高く稼働させるためにはオーケストレーションが必要で、それはコントロールプレーン、データプレーンで構成されていることは理解いただけたと思います。もうお気づきだと思いますが、本番環境でコンテナアプリケーションを監視するには、コンテナの監視だけでなく、クラスターを構成する各コンポーネントそれぞれの監視が必要になります。ここからは、各コンポーネントでどのような観点で監視していけば良いかを、もう少し深掘りしていきます。
1. コントロールプレーンの監視
Amazon ECSやAmazon EKSの場合、コントロールプレーンはマネージドで提供されるため利用者が管理する必要がありません。特に、素のKubernetesはコントロールプレーンの管理負荷が高いため、Amazon EKSのようにコントロールプレーンの管理をAWSにオフロードできるのは大きなメリットになります。
2. データプレーン(サーバー群)の監視
ここは通常のサーバー監視と同様の観点で監視を行います。CPUやメモリの使用状況、ディスク使用状況やネットワークIOなどです。また、個々のサーバーだけでなく、サーバー全体のキャパシティがどの程度あり、コンテナ側からどの程度の使用要求があり、実際どの程度使用されているのか、という観点で監視することが大切になります。なお、AWSでは、このデータプレーンのオプションとして、AWS Fargateというサービスを提供しています。AWS Fargateを選択することで、データプレーンの管理からも解放できます。必要に応じてこちらも選択するのも良いでしょう。
3. コンテナの監視
コンテナの実態はサーバー内の実際の1つのプロセスになります。ですので、サーバー監視をしている方からすると、プロセス監視を行う観点と似ています。コンテナがいくつ稼働しているか、そのコンテナが要求する最低限のリソース量はどのくらいか、要求したリソース量に対して、実際どの程度のリソースを使用しているか、などです。基本的にはコンテナのリソース使用量が適切であるかどうかを監視します。これに加えて、オーケストレーションを使用していることでコンテナ独自の挙動を示すことがあるので、そこも捉えていきます。
コンテナの状態変化を継続的に把握する重要性
コンテナ独自の監視ポイントとしてピックアップしたいのは「コンテナの状態変化を継続的に把握すること」です。コンテナは、要求したリソース量が確保できない、コンテナ起動時の初期処理に失敗した、などの理由で、正常にクラスターに配置できない場合があります。この場合、コントロールプレーンは、自己修復性の一環でなんとかそのコンテナを正常に稼働させようと、コンテナの再作成を試みます。また、コンテナのリソース使用量が要求量に比べて過剰な場合には、コントロールプレーンによってコンテナが強制停止され、コンテナを再作成するケースもあります。いずれの場合でも、クラスターの自己修復性によって自動的に回復されことなきを得ることが多いです。それがオーケストレーションを利用するメリットでもあります。しかしながら、これらの事象が継続的に発生しているとなると話は別です。何か別の問題で再作成が繰り返されていると、最悪の場合、致命的な問題に発展する可能性もあります。
クラスターの管理者としては、コンテナの予期せぬ停止と再作成が継続的に発生していないかをしっかりと捉えることが重要になります。
まとめ
いかがでしたでしょうか?「コンテナって何を見ればいいの?」という質問に回答するためには、本番環境でコンテナアプリケーションを可用性高く安全に稼働させるために必要な構成と特徴を理解することで、その答えが見えてきます。具体的にどの指標を見ればいいのか?というレベルは、当然そのワークロードの特性に応じて変わってきますが、基本的なアプローチは解説したような考え方で網羅できるかと思います。
なお、これらのポイントをNew Relicで具体的に設定する方法については、別の記事で解説しています。それらもぜひ合わせてご参照ください。
Happy container monitoring!!!!

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


