New Relicには、各所から収集したデータを検索するNRQL(New Relic Query Language)という強力なクエリ言語があります。NRQLを効果的に利用することで、よりニーズにマッチした形でデータを可視化することやアラートの設定を行うことができます。
この度、NRQLによるデータの検索の柔軟性をさらに向上させる機能がサポートされたのでご案内します。以下は、Extract URL Values Using Regex Capture to Improve Your NRQL Resultsの意訳記事になります。
--------
技術スタックのパフォーマンスを観測する際には、メトリクス、イベント、ログ、トレースなどの形でテレメトリーデータを収集することが多いと思いますが、これらのデータにはURLの形でデータが含まれていることがあります。 これらのURL属性は通常、標準的な文字列として保存されていますが、これまでは文字列で利用できる機能が限られていたため、NRQLを使ったクエリで意味のあるデータを抽出するのは一筋縄ではいきませんでした。この問題に対処するためにカスタムの属性やデータを追加することは理論的にはできますが、どのようなデータを収集すべきかを事前に知ることは必ずしも容易ではありません。このような類のデータを参照する際の問題を示すために、次のような例を見てみましょう。
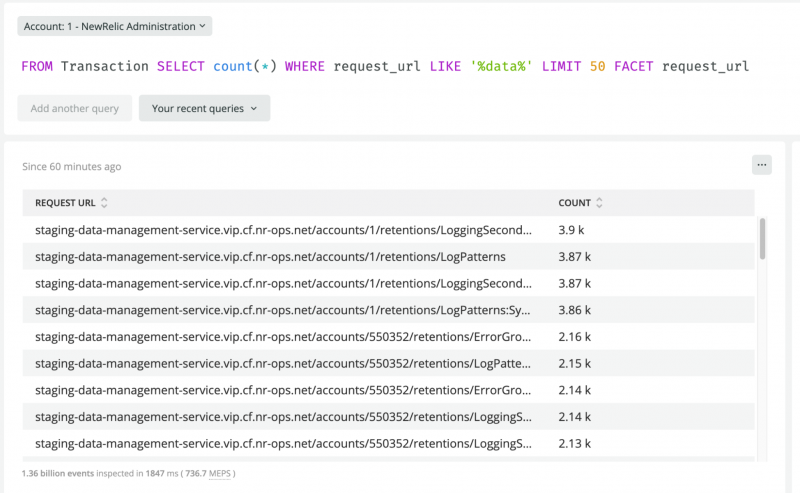
上の画像にあるURLは、あるサービスのトランザクションイベントの属性として記録されています。属性であるrequest_urlでグルーピング(FACET)すると、文字列全体(ここではリクエスト数)で集計されたデータのみが表示されます。しかし、パスに含まれるアカウントのIDでグルーピングしたい場合はどうでしょうか?このままでは、どのアカウントが各エンドポイントを最も利用しているのか、各エンドポイントを利用しているユニークなアカウントは何人いるのか、どのエンドポイントがアカウントに関係なく最も高いトラフィックを持っているのか、などを調べることはほぼ不可能です。
そのため、私たちは正規表現のキャプチャ(capture関数)をサポートしました。これにより、URLやログメッセージなどの文字列から有用なデータを照会・抽出することがこれまで以上に容易になります。
正規表現のキャプチャの仕組み
NRQLでは、capture関数を使った正規表現のキャプチャをサポートします。capture関数を使うと、クエリに正規表現を使用してデータを抽出することができます。以下に例を示します。
capture(request_url, r'.*/accounts/(?P<account>\d+).*')
capture関数は2つの引数を取ります。1つ目の引数はrequest_url:URL文字列を含む属性です。2番目の引数は、特殊なリテラル構文r'...[pattern] ...'を使った正規表現パターンです。NRQL の正規表現は Re2 構文に基づいて構築されています。
上の図のように、キャプチャするパターンの範囲は、名前付きのキャプチャグループ: ...(?P<name> ... pattern ...)...によって定義されます。パターン全体がマッチングに使用され、キャプチャグループはどのサブパターンを抽出するかを定義します。この仕組みについて次に詳しく説明します。現状では、単一のキャプチャしかできません。将来的には、マルチキャプチャーに拡張する予定です。
正規表現のキャプチャの動作
正規表現のキャプチャを使えば、上の例のように簡単にデータを照会することができます。正規表現は最初は扱いが難しいかもしれませんが、Re2にはわかりやすいドキュメントがあります。
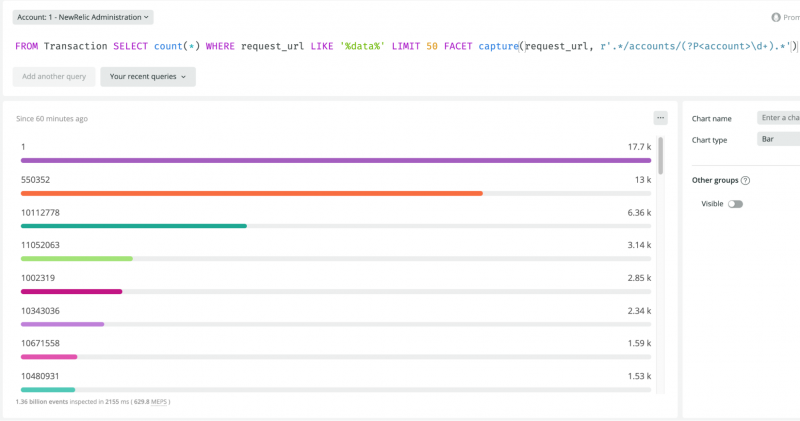
それでは例を見てみましょう。このクエリは、正規表現のキャプチャを使用して、どのアカウントが特定のサービスエンドポイント(request_url)を最も頻繁に使用しているかを調べます。
FROM Transaction SELECT count(*)
WHERE request_url LIKE '%data%' LIMIT 50
FACET capture(request_url, r'.*/accounts/(?P<account>\d+).*')
上記のクエリでは、SELECT countは各FACETでグルーピグされたアカウントごとにトランザクション数を返します。次に、FACET 句をcaputre関数と組み合わせて、キャプチャされたアカウント ID によって結果をグループ化しています。
この正規表現は、以下のセクションで構成されています。
*/accounts/は、文字列の後に/accounts/という接尾辞が付いているものにマッチします。これにより、アカウントIDの直前の文字列の一部を見つけることができます。(?P<account>\d+)は、必須のキャプチャグループで、accountという名前の1つ以上の数字を抽出します。これにより、埋め込まれたアカウントIDが抽出されます。.*は末尾の任意の文字にマッチし、任意の URL パスにマッチさせることができます。これは、すべてのURLがアカウントIDに続くパスを持ち、パターンが異なるURLパスにマッチする必要があるためです。この場合、どのエンドポイントが使用されているかは気にしません。
以下は、このクエリの結果です。各アカウントを識別する特定の番号に注目してください。capture関数がこれらの値を返すことができるのは、第2引数に名前付きのキャプチャーグループが指定されているからです。
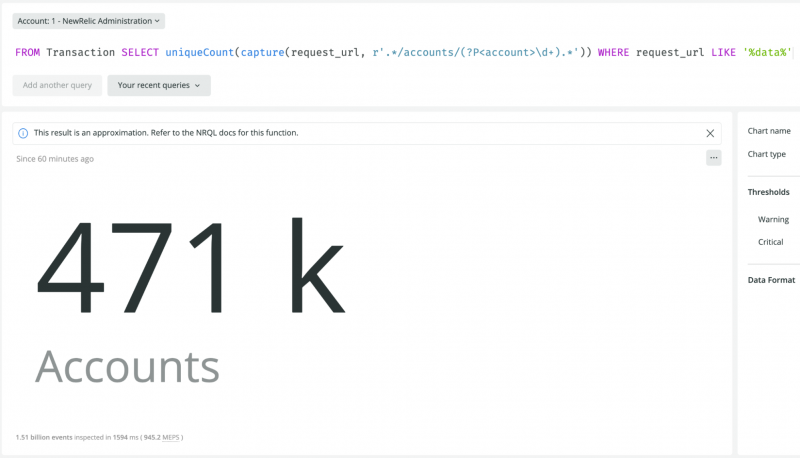
次に、これらのエンドポイントにどれだけのユニークアカウントがヒットしているかを見てみましょう。caputre関数はFACET句、WHERE句、SELECT句で使用できます。この例では、SELECT句のcapture関数をuniqueCountの入力引数として使用しています。
FROM Transaction SELECT uniqueCount(capture(request_url, r'.*/accounts/(?P<account>\d+).*'))
WHERE request_url LIKE '%data%'
uniqueCountを使用すると、各アカウントは一度だけカウントされ、指定されたrequest_urlを使用するアカウントの合計数が返されます。言い換えれば、このクエリは、指定されたエンドポイントのいずれかを使用するアカウントの総数を返します。
その結果は以下の通りです。
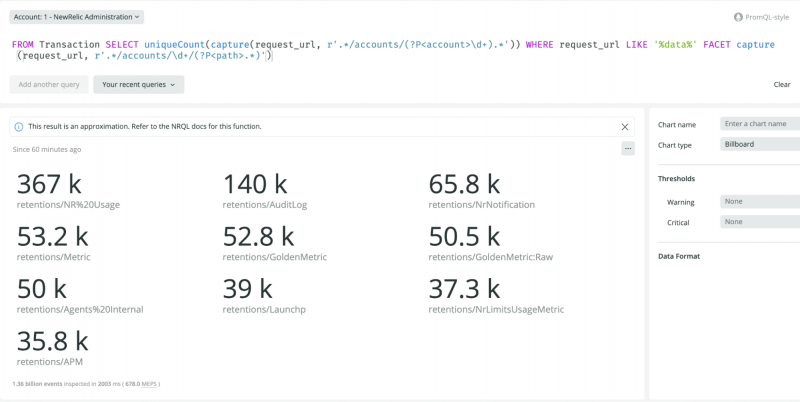
これらのキャプチャをURLの異なるセグメントに適用することで、興味深いデータポイントを発見することがより容易になります。例えば、さらに掘り下げて、それぞれのエンドポイントを使用しているユニークなアカウントの数を確認することができます。そのためには、アカウントに続くパスを抽出する別のキャプチャにファセットをかける必要があります。以下がそのクエリです。
FROM Transaction SELECT uniqueCount(capture(request_url, r'.*/accounts/(?P<account>\d+).*'))
WHERE request_url LIKE '%data%' FACET capture(request_url, r'.*/accounts/\d+/(?P<path>.*)')
この例では、SELECT句とWHERE句の両方でcapture関数を使用する方法を示しています。このファセットをクエリに追加することで、より意味のある結果が得られます。
また、これらのエンドポイントでパフォーマンスが最も低いアカウントを発見することができます。このリクエストでは、指定されたリクエストURLへのリクエストにかかる平均時間が99.9パーセンタイルであるすべてのアカウントを調べます。これらは、パフォーマンスが遅れている極端な外れ値です。
クエリの結果は以下の通りです。
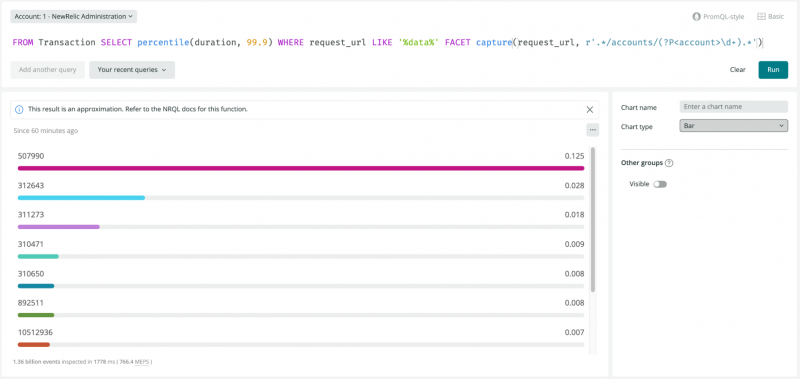
ありがたいことに、これらのエンドポイントのほとんどが良好に動作しています。しかし、507990は異常値なので、調査する価値があるかもしれません。
まとめ
今回は、トランザクションイベントに含まれるURLからアカウント毎のデータを抽出するケースを例にcapture関数の利用方法について説明しました。しかし、ユースケースはこの限りではありません。例えば、以下のようなことが実現できます。
- URLに含まれる商品名などのコンテンツ名を抽出し、コンテンツごとのページアクセス数を計測する。これによりサイトのコンテンツへのアクセス分析(人気のあるコンテンツの洗い出し)を行うことができます。
- xx.yy.zzのようなメトリック名からxxの部分抽出しし、カテゴリごとのメトリックデータの量(データ容量)を集計する。これにより、不必要にデータ量の多いメトリクスなどを明らかにすることができます。
- トランザクションのパスのうち、共通する接頭辞(e.g. /api/v1/など)を除去する。これにより可視化する際の表示をスリムにし、見やすいダッシュボードを構成することができます。
正規表現は、文字列のパターンを見つけるための非常に強力なツールです。正規表現のキャプチャを使えば、その力を利用してNRQLクエリを改善することができます。この新機能を使って、データの新たな発見をしてみてはいかがでしょうか。
次のステップ
New Relic One での正規表現キャプチャの使用については、こちらのドキュメントをご覧ください。正規表現の構文について詳しく知りたい場合は、Re2 syntax をご覧ください。

The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


