大規模なスループットが発生するサービスでは、ログ送信それ自体の負荷や安定性について考慮する必要が高まります。それについて論じたブログ記事 Pros and Cons of Five Enterprise-Ready Log Forwarding Patterns の抄訳です。
初めて分散ロギングを扱うとき、開発者は本能的に、アプリケーションのログをアプリケーションからロギングバックエンドに直接送信したくなるかもしれません。直接接続は魅力的です。このような通信は通常、トランザクション型の REST API を介して行われ、すべてのログが通過するという誤った安心感を開発者に与えてしまいます。
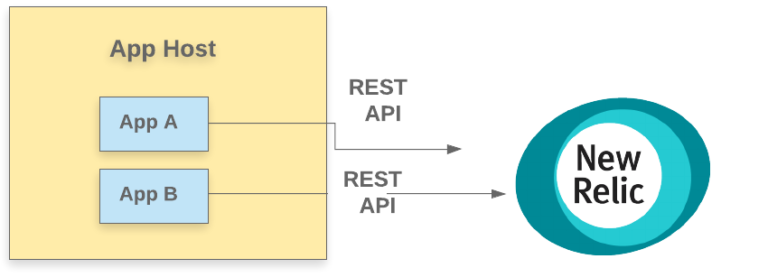
残念ながら、このモデルには3つの脆弱性のポイントがあります。
- ログが予期しないサイズやレートに達した場合にHTTP リクエストに対するバックプレッシャーが発生して、計装されたコードの正常な機能を破壊する恐れがある
- ロギングバックエンドにデータを送信する際に、レイテンシによってログデータの送信にラグが発生する恐れがある
- ネットワーク接続の問題が発生すると、ログの欠損につながる。特に、APMが計装されたアプリケーションからのログが障害と関連しているときにトラブルになります。
サイト信頼性エンジニアリング(SRE)では、システムの脆弱性を減らすためにシステムのテレメトリを常に観察することが原則とされています。ログ送信をアプリケーションから切り離すことで、システムの脆弱性を減らすことができます。ログフォワーダをアプリケーションコードから切り離すと、複雑な処理計算を別のプロセスで行えるようになり、アプリケーションに影響を与えることなく、ログフォワーダのコードや設定を頻繁に更新できるようになります。
さらに、ログフォワーダは、メモリまたはファイル ベースのバッファリングを内蔵しており、アプリケーションが動いているデータセンターとロギングのバックエンドと間に発生する様々な遅延や割り込みに対して、重要な柔軟に対応できるようになります。
ログフォワーダを使うと、次のようなことも対応可能です:
- 実行しているアプリケーションコードよりも幅広いネットワークプロトコルや出力フォーマットをサポートするように拡張されている
- インフラストラクチャレベルで分離されている、つまり異なるホストや異なるコンテナで実行できる
- 負荷のバランシングが可能
- 複雑なパイプラインを構成でき、上流で集約したり、堅牢なバッファリングを使うことも可能
この記事では、ログフォワーダを使用してログを New Relic Logs などのロギングバックエンドに配信するための5つのパターンを紹介します。New Relic Logsは New Relic One の核となるコンポーネントの一つです。これらのパターンを知ることで一般的な知識を身につけ、実践的な判断ができるようになるはずです。ログパイプライン全体にわたる脆弱性を低減するために何ができるのか?レイテンシ、エラー、飽和度を低減するにはどうしたらよいか?分散ロギングのプロセスを解明し、今日から使える実用的なパターンを紹介していきます。
どんなログフォワーダを使えばいいか
ELKスタックの一部である Logstash、Rsyslog、Fluentdの3つは一般的で比較的使いやすいログフォワーダです。WayfairのTremorや、Timber.ioのVectorのような新しいフォワーダはハイパフォーマンスな環境向けに作られています。が、ここで全てを比較することはやめておきましょう。
New Relic Infrastructure エージェントは、Fluent Bitエクステンションを使用してログ転送をサポートしています。設定の記述はFluent Bitの構文と互換性があります。Infrastructureエージェントをデプロイしておけば、その組み込みのフォワーダを使ってログを送り出すことができます。この記事では、Fluentd と Fluent Bit をスタンドアロンのフォワーダとして使っていきます。Infrastructure エージェントをインストールしていない場合や、複数の分散ソースを処理するために中央集権型のフォワーダが必要な場合にも使用できます。
注: FluentdとFluent Bitだけではなく、LogstashとVectorもNew Relic Logs用のプラグインを提供しています。また、ここに記載されていない他のフォワーダにも様々かつ柔軟な設定オプションがあり、New Relicを含むあらゆるバックエンドにログを送信することができます。
FluentdとFluent Bitのどちらが必要かを判断するために、以下のような比較ができます:
| 利点 | 欠点 | |
|---|---|---|
| Fluentd |
|
|
| Fluent Bit |
|
|
FluentdとFluent Bitをインストールする
New Relic Logsは高速で拡張性の高いログ管理プラットフォームを提供しており、ログデータを他のテレメトリデータと接続することができます。また、FluentdやFluent Bit(もしくはその他のフォワーダ)用のプラグインがあらかじめ用意されており、どこからでも簡単にデータをNew Relic Oneにログを送信することができます。
インストールと設定方法については、New Relicのドキュメントを参照してください。
以下の例ではログを New Relic に転送したい場合を想定していますが、その場合は New Relic のライセンスキーが必要です。ライセンスキーなしに基本的な転送機能を確認したい場合は、 フォワーダをダウンロードして(以下のリンクを参照)、テスト用に出力ファイルに書き込むように設定することができます。
注: パッケージマネージャ用に構築されたこれらのツールのフォークは、td-agent (Fluentd) と td-agent-bit (Fluent Bit) の命名規則に従っています。
Fluent Bit パッケージ:
Fluentd パッケージ:
ここでは、ログをNew Relic One(もしくは、使用したい何らかのバックエンド)に転送するための5つのパターンを見てみましょう。それぞれのパターンについて、長所と短所を見ていきます。
パターン1: ログをファイルに出力して、そのホストでフォワーダで動かす
このパターンでは、ファイルをtailして1つ以上のログファイルを監視し、書き込まれた新しい行をロギングバックエンドに送信します。フォワーダはアプリケーションホスト上の2つのアプリケーションの間に配置されます。ほとんどのフォワーダは豊富な設定オプションが設定でき、tailをどのように動作させるか、またロギングバックエンドに投稿する際にどのようなバッファリングが使用されるかを適切に選ぶことができます。スケーラビリティのために、同一ホスト内に配置されたフォワーダは、他のホストのフォワーダに転送することもできます(後述のパターン3に似ています)。
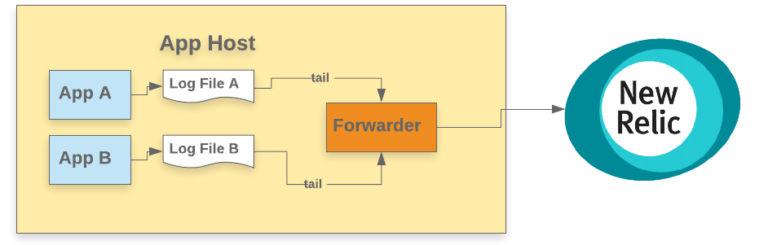
利点
- ホスト単位で 1つのフォワーダがあるため、アプリケーションインフラのスケーリング合わせて自動的にスケーリングされる
- ログファイルを使用するので、モダンなロギングツールに対応してないレガシーアプリケーションのログを転送することができる
欠点
- フォワーダはかなりの計算リソースを消費することがあり、アプリケーションの過剰なスケールアウトが必要となる可能性がある
- フォワーダの設定とアプリケーションの設定の依存性が高く、デプロイも複雑になる
- 負荷のピーク時にログファイルが肥大化し、ファイルテーラー(ログローテートと同じように)が追いつかず、ログ転送の遅延やストレージ不足が発生する可能性がある
設定例
注意: これらの設定例は、Python APMエージェントのロガー設定を参照しています。Pythonエージェントで Logs in Context を設定する手順は、ドキュメントを参照してください。さらに、出力を正しく設定するために、ロギングハンドラの設定についてのPythonの公式ドキュメントを参照してください。
Python
.
.
# Instantiate a new log handler
handler = logging.FileHandler('/var/log/app-a.log')
.
.
Fluentd
<source>
@type tail
<parse>
@type none
</parse>
path /var/log/app-a.log
tag app-a
</source>
<source>
@type tail
<parse>
@type none
</parse>
path /var/log/app-b.log
tag app-b
</source>
<match **>
@type newrelic
license_key <NEW_RELIC_LICENSE_KEY>
base_uri https://log-api.newrelic.com/log/v1
</match>
Fluent Bit
[INPUT]
Name tail
Path /var/log/app-a.log
[INPUT]
Name tail
Path /var/log/app-b.log
[OUTPUT]
Name newrelic
Match *
licenseKey <NEW_RELIC_LICENSE_KEY>
パターン2: 同じホストにあるフォワーダに、ソケットでログを送る
このパターンでは、アプリケーションはUDPまたはTCPポートを介して直接フォワーダにログを送信し、フォワーダが非同期的にNew Relicにログを転送します(New Relic Log APIを使用しています)。ファイルには出力されません。フォワーダーはアプリとNew Relicバックエンドの間に位置し、最小限のバッファと処理レイヤーを提供します。
注意: UDPとTCPのどちらを使用すべきか、詳しい議論は他に譲ります。 一般論として、UDPはアプリケーションへの影響は最小限に抑えられますが、プロトコルの配信保証は高くありません。そのため、大量にログが発生する環境では、フォワーダにログを送信するためにUDPが選ばれる例が多くあります。一方で、SIEM ソフトウェアのようなセキュリティに特化したアプリケーションでは、完全性を保証するためにTCPを使用する傾向になります。
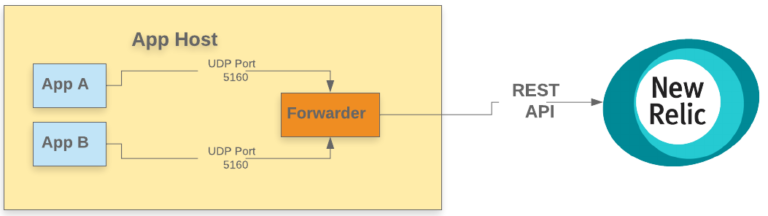
利点
- ホスト単位で 1つのフォワーダがあるため、アプリケーションインフラのスケーリング合わせて自動的にスケーリングされる
- ログ入力にソケットプロトコルを使用するため、ファイルを保存したりローテートしたりする必要がない
- フォワーダが同一ホストに設置されているため、ネットワークのオーバーヘッドが少ない
- 1つのフォワーダは、任意のアプリケーションからネットワークインターフェースを介してログを受信できる
欠点
- フォワーダはかなりの計算リソースを消費することがあり、アプリケーションの過剰なスケールアウトが必要となる可能性がある
- フォワーダの設定とアプリケーションの設定の依存性が高く、デプロイも複雑になる
- 物理的なログファイルがないため、ホスト上のアプリケーションをトラブルシューティングのときに難しくなる(別の設定としてファイルに出力することもできなくありません)
- TCP プロトコルは、アプリケーションにバックプレッシャーを与える可能性がある
- TCP および UDP カーネルのパラメータを調整する必要がある
- 以下のようなシステムテレメトリを監視する必要がある
- UDP Buffers (for UDP)
- UDP Buffer Receive Errors
- TCP Errors
設定例
Python (UDP)
# UDP Example
.
# Instantiate a new log handler
handler = logging.DatagramHandler('localhost', 5160)
.
.
Python (TCP)
# TCP Example
.
# Instantiate a new log handler
handler = logging.SocketHandler('localhost', 5170)
.
.
Fluentd
<source>
@type udp
<parse>
@type none
</parse>
tag udp_5160
port 5160
bind 0.0.0.0
</source>
<source>
@type tcp
tag tcp_5170
<parse>
@type none
</parse>
port 5170
bind 0.0.0.0
</source>
<match **>
@type newrelic
license_key <NEW_RELIC_LICENSE_KEY>
base_uri https://log-api.newrelic.com/log/v1
</match>
Fluent Bit
注:UDPはFluent Bitの組み込みプラグインとしてはサポートされていません。
[INPUT]
Name tcp
Listen 0.0.0.0
Port 5170
[OUTPUT]
Name newrelic
Match *
licenseKey <NEW_RELIC_LICENSE_KEY>
パターン3: 別のホストにあるフォワーダに、ソケットでログを送る
このパターンでは、ログフォワーダはアプリケーションホストの外部に配置されています。アプリケーションは UDP または TCP ポートを使ってログをフォワーダに送信し、フォワーダは Log API (New Relic 出力プラグインにカプセル化されています)を使って、ログを New Relic One に転送します。
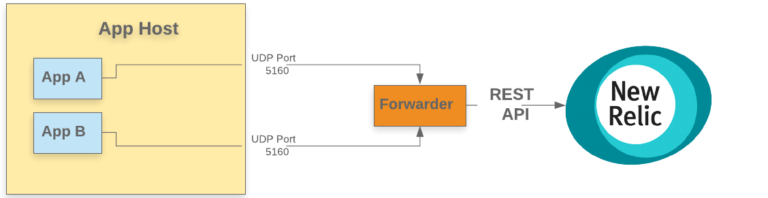
フォワーダを別のインフラストラクチャに移動することで、計算リソースの使用率に関するスケールメリットが得られ、ログフォワーダのインフラストラクチャへの構成とメンテナンスを一元化できます。このパターンでは、異なるアプリケーションファミリが同じインフラストラクチャプールにログデータを送信できます。必要に応じて、異なるソースからのログのカスタム処理を行うために、パターンマッチングと同様に、異なるポートやプロトコルを使用することもできます。
利点
- ログを処理するために特別にプロビジョニングされたインフラストラクチャを用意するため、アプリケーションのインフラの一部としてフォワーダをプロビジョニングする必要がない
- 異なるアプリケーションから同じログフォワーダにログを送信できる
- アプリケーションから独立してフォワーダをスケーリングできるので、バックプレッシャーがなくなる
- 例えば Apache Kafka を使用してログを保存してから New Relic One やロギングバックエンドにログを送信するなど、耐久性のあるバッファを実現するための強力な方法を使用できる
欠点
- 物理的なログファイルがないため、ホスト上のアプリケーションをトラブルシューティングのときに難しくなる(別の設定としてファイルに出力することもできなくありません)
- 独立した設定で新しい種類のインフラストラクチャ維持が必要
- フォワーダプール内のどれかのフォワーダを圧倒するような「ホットな送信者」アプリケーション問題に遭遇する可能性がある(次のパターンで、フォワーダプールの前にあるロードバランシングレイヤを使用してこの問題を排除する方法を紹介します)
設定例
Pythonエージェントのロギング設定はパターン2とほぼ同じになりますが、フォワーダーホストのパブリックIPまたはDNS名を使用する必要があります。
Python
handler =
logging.DatagramHandler('forwarder1.host.mycompany.com', 5160)
パターン4: スケールアウトされたフォワーダに、ソケットでログを送る
前のパターンと同様、フォワーダ層はアプリケーションの外側に配置されています。しかし、この場合、フォワーダレイヤーはロードバランサレイヤーの後ろにインストールされています。アプリケーションは、通常はUDPポートを介してフォワーダレイヤーの前にあるロードバランサレイヤーにログを送信し、ロードバランサは一般的な負荷分散ルール(ラウンドロビンなど)に基づいてフォワーダの適切なインスタンスにデータを送信します。各フォワーダは、パターン3のフォワーダと同じように構成されています。
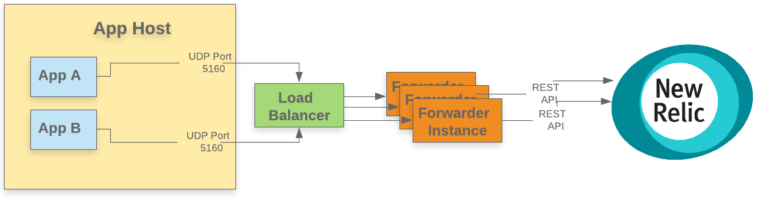
基本的に、このフォワーダプールの設定は、ロードバランサ層以外には何も変わりません。この場合、 Nginx のロードバランサは、アプリケーションプロセスが特定のフォワーダを圧倒しないようにします。アプリケーションは Nginx UDP load balancer に関連付けられたラウンドロビン DNS リソースを使用してログを送信します。
利点
- 大規模なスケーラビリティを実現可能
- マルチテナントのログ転送インフラに適している
- 高可用なログ転送インフラストラクチャが実現
- 「ホットな送信者」からのログの「スパイク」は分散されるため、大量のログを送信する可能性のあるアプリケーションが転送エンドポイントを詰まらせることがない
欠点
- 独立した設定で新しい種類のインフラストラクチャ維持が必要
設定例
Pythonのロギング設定はパターン2と3とほぼ同じですが、Nginxのロードバランサーに関連付けられたDNS名を使用する必要があります。
Python
handler = logging.SocketHandler('loglb.mycompany.com', 5160)
ロードバランサの設定例
# Load balance UDP‑based DNS traffic across two servers
stream {
upstream dns_upstreams {
server <IP of forwarder 1 of 3>:5160;
server <IP of forwarder 2 of 2>:5160;
server <IP of forwarder 3 of 3>:5016;
}
server {
listen 5160 udp;
proxy_pass dns_upstreams;
proxy_timeout 1s;
proxy_responses 1;
error_log logs/log-lb.log;
}
}
パターン5: ログの種類によってルートをわける
この一連のパターンは、これまでに説明した他のデータ転送パターンと組み合わせることができます。大規模なアプリケーションになると、様々なログが大量に必要となり、フィルタリングし、適切にルーティングする必要があります。これらのパターンの実装はフォワーダに依存しがちですが、多くフォワーダはこのようなパターンをサポートしているはずです。バックエンドでログイベントがどのように処理されるかについて、Life of a Fluentd event をご覧ください。
利点
- 大規模なスケーラビリティが実現可能
- レートとログサイズの異常なスパイクを緩和し、フォワーダのクラッシュを防ぐことができる
欠点
- 設定が複雑になり、動作の理解が難しくなる
- 様々なフィルタを使用することで、CPUとメモリのリソースを大量に消費する。フィルタは賢く使いましょう。複数のフィルタを使う場合は、データを大量に除外するフィルタを最初に実行しましょう。
それでは、フィルタリング、加工、ルーティングの例を見てみましょう。
フィルタリング設定例
どのログをどのログストリームに送るかを設定します。
Fluentdは出力プラグインごと match ディレクティブをサポートしています。match ディレクティブは、一致するタグを持つイベントを探して処理します。
ロードバランサの設定例
<match **>
… New Relic account A..
</match>
特定のアプリケーションからのものとしてタグ付けされたレコードのみを許可する
<match app.customer_info>
...
</match>
注意すべき欠点としては、フォワーダ内に中間処理がある場合、そのレコードを破棄しても各レコードはその処理オーバーヘッドを受けます。また、Fluentdのイベント処理パイプライン内でフィルタリングを行うことができるので、不要なレコードをすぐに破棄することができます。
<source> … input configs… tag app-a </source> <source> … input configs… tag app-b </source> <filter app-a> … expensive operation only for app-a… </filter> <match **> … output configs… </match>
もう一つの非常に便利なパターンは、不要なコンテンツを削除したり除外したりすることです。 <exclude> フィルタを使用して、個人を特定できる情報(PII: Personally Identifiable Information )を含むログなどを、特定のログをストリームから削除することができます。
<filter **>
@type grep
<exclude>
key message
pattern /USERNAME/
</exclude>
</filter>
ログ加工の設定例
ストリーム内の既存のログにコンテンツを追加または変更することもできます。
ログの加工は一般的に、処理対象のレコードに要素を追加したり、更新したりすることを意味します。Fluentdには、 record_transformer など、多くの演算子が用意されています。
# add host_param to each record.
<filter app.customer_info>
@type record_transformer
<record>
host_param "#{Socket.gethostname}"
</record>
</filter>
これらは初歩的な例であり、Fluentdがサポートするタグ管理のフルパワーを十分に活用できているとは言えません。 rewrite_tag_filter プラグインを使用してレコードにタグを注入する方法の素晴らしい例については、rewrite_tag_filterのドキュメントを参照してください。
ルーティングの設定例
異なるタイプのログを異なるバックエンドに送信したり、別のNew Relicアカウントに送信したりも可能です。
Fluentdは、異なるイベントを全く異なるバックエンドに送ることができる強力なルーティングの設定を数多くサポートしています。ルーティングの実用的な例としては、以下の2つがあります。
- あるアプリケーションのログを特定のNew Relicアカウントに送信し、他のすべてのアプリケーションのログを別のNew Relicアカウントに送信する
- a) New Relic と b) 長期アーカイブ用のクラウドストレージバケットの2つの異なる出力にログを送信する。
ログがシステムを食いつぶさないようにするには
現代的なSREにとってフルスタックな観測性が重要です。上流のロギング実装がどのようにスケールするか。複雑で広域なネットワーク上のデータセンター間で発生する様々な遅延や切断に対してどのようにリジリエンスを発揮できるか。慎重な検討が求められています。
特定の異常な状況下では、正常に動作していたアプリケーションが突然、予想外のサイズのログ(複数MBのスタックトレースやオブジェクトダンプ)を出力しだしたり、予想もしていなかった速度(毎分数百万行)でログを放出続けるようになることもあります。ログがシステムのリソースを食いつぶし、許容範囲を超える混乱を引き起こし、可観測性が崩壊する。そのような事態をさけるために、ここで示したパターンが参考になれば幸いです。
弊社のエキスパートによるNew Relic Logsの素晴らしいコンテンツをもっとお探しの方は、Kubernetes上で実行されているJavaアプリケーションにLogs In Contextを設定する方法 もご覧ください!
The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


