New RelicではどのようにSLI/SLOを定義し、SREを実践しているか。その経験から、SLI/SLOについて解説した記事 Best Practices for Setting SLOs and SLIs For Modern, Complex Systems の翻訳です。
--
New Relicのサイト信頼性VPであるMatthew Flamingも、この記事に貢献しています。この記事はサンフランシスコその他で行ったFutreStack18での講演「SLOs and SLIs In The Real World: A Deep Dive.」をもとに作られています。
New Relicでは、サービスレベル指標(Service Level Indicator: SLI)とサービスレベル目標(Service Level Objective: SLO)を定義したり設定したりことが、サイト信頼性エンジニアリング(Site Reliability Engineering: SRE)のプラクティスとしてますます重要な側面になっています。SLIやSLOが高機能な信頼性に対する重要なプラクティスになってきているというのは言うまでもないですが、現実にある状況、複雑な現代的アーキテクチャでそれらを適用しようとするのはチャレンジングです。特に何を計測したり、どのように計測したりするかを決めるのは簡単ではありません。
この記事では、New Relicのアーキテクチャの概要を使いながら、私たちはNew Relicのプラットフォームに対してどのようにSLIやSLOを定義し、計測しているのかについて、具体的かつ実践的に示していきます。
SLI, SLOをどのように定義するか
略語で混乱するのはよくある話なので、本題に入る前に、まずは定義を確認しましょう。
- サービスレベル指標 (Service Level Indicator: SLI) … 「〇〇は正となるべきである」
- サービスレベル目標 (Service Level Objective: SLO) … 「〇〇のある時間での割合」
- サービスレベル合意 (Service Level Agreement: SLA) … 条件を満たさなった場合にどうするか
例えば、この定義を可用性に適用するとしたら、SLIはシステムの可用性のキーとなる計測値となります。SLOはどの程度の可用性を目指すかのゴール、そしてSLAはサービスレベル目標を達成できないときに何をしなければならないかを示す契約条件となります。
SLIはエンジニアリングチームがより良い決断をするために存在します。SLOパフォーマンスは、ハードで素早い決断が迫られた場面で役立つ最重要な情報です。SLOはまた、自分のチームが管理しないサービスやシステムに対して仮説を立てる場面で重要となるデータポイントです。さらに、組織が大きくなったときには、SLIやSLOは新機能開発と信頼性の改善のどちらに投資すべきかを判断する基準になります。
システムの境界にSLIとSLOを設定する
モダンなソフトウェアプラットフォームの内部は(控えめに言っても)気が遠くなるくらいに複雑です。プラットフォームは、データベース、サービスノード、ロードバランサー、メッセージキューなどを、数百のコンポーネントで構成されることもよくあります。各コンポーネントに対して顧客向けのSLIとSLOを確立するのは、現実的ではありません。
そのためにおすすめしたいのは、個々のコンポーネントではなくシステムの境界でSLIとSLOに設定することです。プラットフォームのシステム境界で計測できるSLI/SLOは、内部コンポーネントの境界よりもはるかに少なく、より価値があります。システムを保守するエンジニア、システムの顧客、ビジネス上の意思決定者にとって有用となります。
システム境界は、外部の顧客に対して公開している機能を提供している1つまたは複数のコンポーネントです。たとえばNew Relicプラットフォームには、APIを通じてユーザを認証するための機能を持つログインサービスあります。
ログインサービスには、サービスノード、データベース、読み取り専用のデータベースレプリカなど、いくつかの内部コンポーネントがあるかも知れません。ですが、これらの内部コンポーネントは顧客に公開されていないため、システムの境界にはなりません。一連の内部コンポーネントが連携して、ログインサービスの機能を構成しています。
このシステム境界の考え方を使用してみましょう。New Relicをシンプルに捉えると、次の4つの論理ユニット(または階層)で構成されています。UI、 サービス層(ログインサービスなど)、2つのデータベース、そしてデータ収集サービス。そしてもちろん、New Relicは1つ以上のシステム境界を持っています。これらサービス全体と外部顧客との境界です。
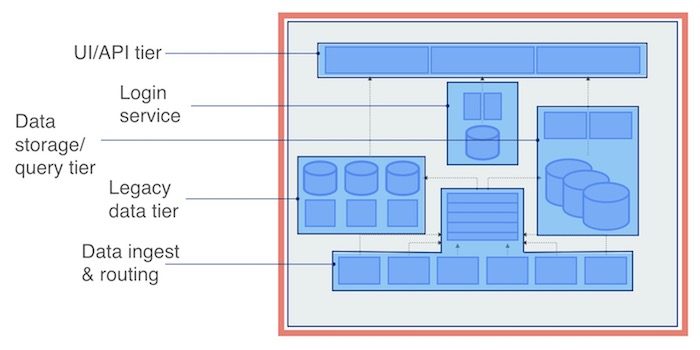
システム境界のSLIにフォーカスすることで、これらの重要なシステム測定値の価値を捉えることができ、また、測定に必要な実装の手間を大幅に減らすことができます。
SLIとSLOの始め方
SLI、SLO、およびシステム境界の概念を、モダンなプラットフォームを構成するさまざまなコンポーネントに適用することができます。これらの概念をどのように適用するかは、コンポーネントの種類によって異なりますが、どの場合も同じ一般的な方法を使用します。
- プラットフォーム内のシステム境界を特定する
- システム境界に存在する、顧客に公開している機能を特定する
- 各機能が利用可能であることの意味を、わかりやすい言葉で定義する
- その定義のための1つ以上のSLIを定義する
- ベースラインを得るために測定を開始する
- 各能力のSLOを定義し、それに対するパフォーマンスを追跡する
- システムを繰り返して改善し、常にSLOを調整していく
各システムの境界には、考慮すべき機能と依存関係のユニークなセットがあります。つぎに、これらの考慮事項が、各階層のSLIとSLOの定義方法をどのように形成するかを詳しく見てみましょう。
機能がSLIを駆動する
New Relicプラットフォームでは、可用性の定義の一部として、顧客からデータを収集して他のシステムがデータを利用できるように適切な場所にルーティングできる、ということを定義しています。そこでは、収集とルーティングという2つの異なる機能を扱っているので、それぞれにSLOとSLIが必要になります。
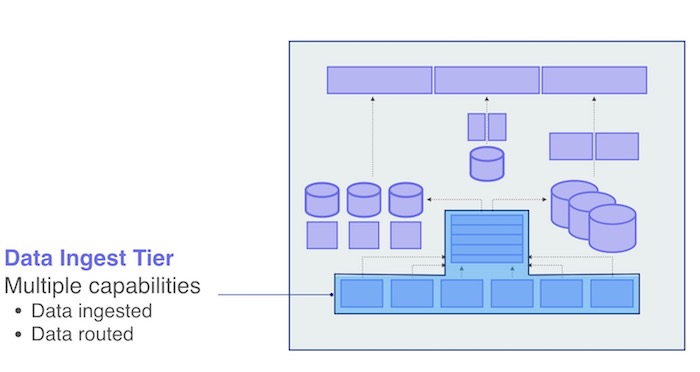
このシステムを使用している顧客にとって、それぞれの機能の「可用性」とは何を意味するのかをわかりやすく定義することから始めることが重要です。収集機能の顧客とは、New Relicのエンドユーザー、つまりデータを送ってくる人たちです。この場合、可用性の定義は次のようになります: 「自分のデータを正しい形式でNew Relicに送れば、それは受け入れられて処理される」
このわかりやすい定義を使って、どのメトリックが可用性の定義に最も適しているかを判断することができます。ここでの最適な指標は、おそらく、受信データを含むHTTP POSTリクエストのうち、200 OKステータスレスポンスで受け入れられたHTTP POSTリクエストの数になるでしょう。これをSLOの観点から表現すると、「99.9%の整形済みペイロードが 200 OKステータスレスポンスを受け取る」と言えるかもしれません。
ルーティング機能のわかりやすい定義は、「受信したメッセージは、他のシステムがメッセージバスから遅延なく取り出すことができる」。この定義では、SLIとSLOを「受信メッセージの99.xx%は、他のシステムが500ミリ秒以内にメッセージバスから取り出すことができる」と定義することができます。このSLO 99.95%を測定するために、各メッセージの収集タイムスタンプを、メッセージバスでそのメッセージが利用可能になったときのタイムスタンプと比較することができます。
OK、素晴らしい!これで各機能のSLOが得られました。実際にやってみると、SLOの数値は調整するだけのなので、SLIのほうが検討が必要になります。事実として、さまざまなビジネス上の理由から、SLOの数値を調整したい場面があります。たとえば、あまり成熟していないシステムではSLOを低く始めて、システムが成熟するにつれてSLOを高くしていくこともあります。これが、SLIを駆動させる機能が重要であると述べている理由です。
SLIは可用性の広範なプロキシ
New Relicプラットフォームに収集されたデータは、我々が「NRDB」と呼んでいる、New Relic内部のメインデータ層のどこか1つに保存されます。わかりやすく言えば、NRDBはシステムにデータを素早く挿入し、顧客がそのデータを照会して取得することができれば、正常に機能しているといえます。
NRDBは数千のノードとさまざまなタイプのワーカーを持つ大規模な分散システムです。このシステムを監視して、メモリ使用量、ガベージコレクション時間、データの耐久性と可用性、1秒あたりにスキャンされたイベントなどのメトリクスを追跡しています。しかし、システム境界のレベルでは、インサートのレイテンシとクエリ応答時間に注目することで、裏に隠れたエラーを表すプロキシとして見ることができます。
クエリ応答時間にSLIを設定する場合、平均値を見ることはありません。平均値は嘘を付きます。しかし、ワーストケースなシナリオのクエリが実行されることもあるので、99.9パーセンタイルも見たくありません。そのかわりに、95パーセンタイルや99パーセンタイルに注目します。これで、外れ値にあまり焦点を当てることなく、大多数の顧客の体験を見抜くことができます。
これで、クエリの応答時間SLOに違反した場合に発砲するアラートの条件を設定することができます。すると、どのくらいの頻度でこのアラートが起こっているかを追跡することができ、その結果、どのくらいの頻度でSLOを満たしているのか、つまり、どのくらいの時間が利用可能なのかを知ることができます。真夜中に人を起こすためにこのアラートを使用するのは本当に避けたいものではありますが…、SLO違反を記録することでのパフォーマンスを簡単に追跡することができるようになります。
New Relicでは、データ層に対してこれらのSLIとSLO を明確に定義しており、顧客はデータを照会する際に何を期待すればよいかを知ることができます。実際には、複数の SLO を組み合わせて、顧客フレンドリーな単一の信頼性の基準として使っています。

それぞれの論理的ユニット毎にSLOを定義する
New Relicプラットフォームには、新しいNRDBだけではなく、レガシーなDBMSもいくつかあります。レガシーデータベースは巨大なデータを分割してシャードにして管理しており、速度改善や管理しやすさに寄与しています。
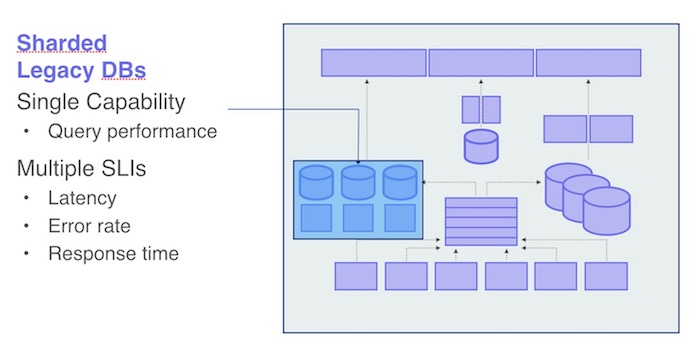
レガシーデータベースを測定するために、各シャードごとにSLIとSLOを作成しています。ユーザーのワークロードはシャード間で分散されていないからです。
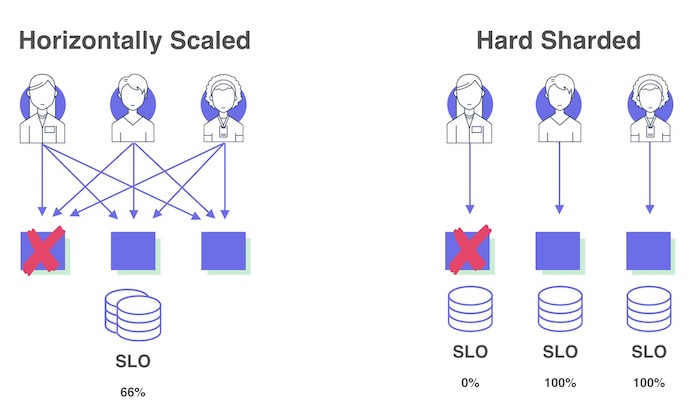
次の図の1つ目、水平スケールされたサービスでは、ノードを1つ失った場合、データベースが顧客のリクエストの1/3を処理できます。その場合は、データベースを1つの論理ユニットとして扱い、SLOを管理することができます。図の2つ目のように顧客ごとにシャード化されたシステムでは、1つのノードを失った場合、全体では33%のエラーが発生するのは同じですが、実際には、1/3の顧客は100%のエラーが発生し、2/3の顧客は何も問題が起こっていないように見えるはずです。この場合は、全体を1つの論理ユニットとしては扱えず、個別にSLOを管理する必要があります。
そこで、このレガシーデータ層では、各論理インスタンス(この場合は各データベース・シャード)についてSLIとSLOを個別に測定ています。NRDB層と同様に、レガシー層の唯一の機能はクエリ処理であり、SLIとSLOを用いてレイテンシ、エラー率、応答時間を測定しています。リージョンが異なる場合にも同じように考えることができます。例えば、New RelicのEUリージョンはUSリージョンとは論理的に独立したインスタンスであるため、システムごとに独自のSLOを取得しています(ほとんどは、同じSLIを再利用しています)。
顧客体験を測定し、SLI/SLOを理解する
私たちはUI層に1つの機能、「高速でエラーがないこと」を定義しています。しかし、UIパフォーマンスを測定するためには、視点を少し変えなければなりません。これまでは、信頼性に関する懸念はサーバー中心でしたが、UI層では、フロントエンドアプリケーションが顧客体験に対してどのような影響を与えるかを測定したいと考えています。UI層では複数のSLIを設定する必要がでてきます。
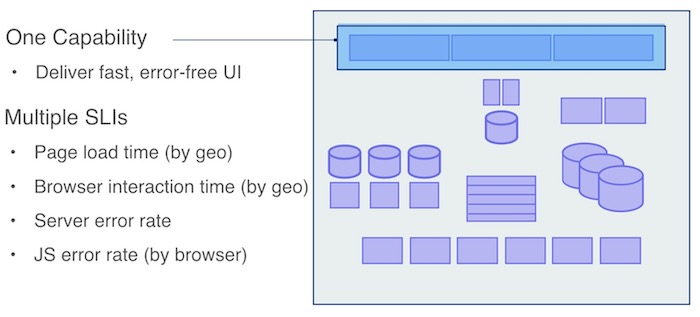
例えば、ページのロードタイムについては、平均ではなく、95パーセンタイルまたは99パーセンタイルのロードタイムを使用しています。さらに、地域ごとに異なるSLIを設定しています。しかし、モダンなウェブアプリケーションでは、ページロードタイムは考慮すべきSLIの1つに過ぎません。
さらに、AJAXのトリガーやDOMの変更など、ブラウザ内のさまざまなインタラクションの応答性を計測するためのSLIを作成したいと考えています。そしてもちろん、JavaScriptのエラー率を計測するSLIを設定し、特定のブラウザでのユーザー体験の改善を優先させる場面もあります。
ハードの依存関係には強いSLOが必要
ここまで、New Relicプラットフォームのさまざまなサービスに対してSLIとSLOを定義する方法を説明してきましたが、ここからは、コアインフラストラクチャの重要な部分であるネネットワーク層について説明していきます。これらはNew Relicにとって最も重要なSLIとSLO であり、プラットフォーム全体の基盤となるものです。ネットワーク層は、New Relicのすべてのサービスにとってハードの依存関係にあります。
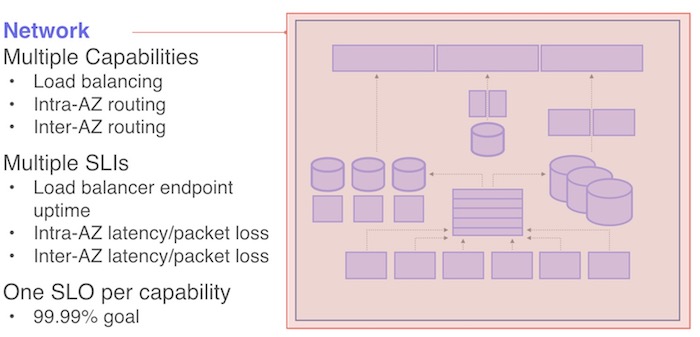
この層では、3つの機能を定義しています。アベイラビリティ・ゾーン(AZ)間の接続性、AZ内のラック間の接続性、内部と外部の両方にサービスを公開するロードバランサのエンドポイントです。これらの機能には、より高いSLOが必要です。
これらの依存関係の層には、潜在的な障害シナリオがあります:
- UI層で何か問題が発生した場合、それは孤立した障害であり、簡単に復旧できる
- サービス層がダウンした場合、UI層に影響が出ますが、その影響を軽減するために UIキャッシングを実装することができる
- データ層がダウンすると、サービス層とUI層もダウンし、データ層とサービス層の両方がオンラインに戻るまでUI層は回復できない
- ネットワーク層がダウンすると、すべてがダウンしてしまい、システムがオンラインに戻るまでにある程度の復旧時間が必要になります。また、システムは依存関係が回復した瞬間には復帰しないため、平均復旧時間(MTTR)は各層の単位で変化。
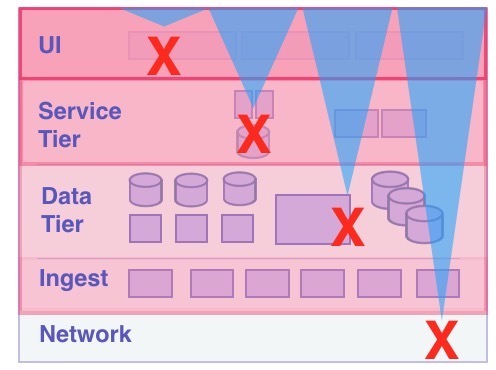
一般的には、各層のアップタイムは1桁落ちることを想定しています。ネットワーク層で実行されているサービスのSLOを99.9%の可用性を期待する場合、ネットワーク層のSLOを99.99%の可用性に設定します。
ハードなインフラの停止に対してグレースフルな縮退シナリオを実装するのは難しいので、インフラ層のSLOはより高い目標値を設定し、信頼性の確保に投資しています。このプラクティスは、プラットフォームの全体的な健全性のためにできる最も重要なことの1つです。
最後に、全体的にチェックしよう
さて、New Relicプラットフォームの全体を提供するサービスのSLIとSLOを定義できました。これで、私達は信頼性のホットスポットがどこにあるかを理解することができ、エンジニアリングチームは信頼性に関する課題を理解し、優先順位を付け、守るためのとても役立つ道具を手に入れました。ただし、最後の1つだけ、SLIとSLOのチェックを実装する必要があります。エンドツーエンドの顧客体験を測定する必要があります。
これを実現するために、単純なエンドツーエンドの顧客ワークフローを表すNew Relic Syntheticsスクリプトを実行します。このスクリプトは、New Relicのプラットフォームにデータを送信し、ログインして、特定のデータに対してクエリを実行します。このスクリプトのパフォーマンスとSLOで設定した目標値を比較して、大きな差異があることがわかれば、SLIを見直す必要があることがわかります。
The views expressed on this blog are those of the author and do not necessarily reflect the views of New Relic. Any solutions offered by the author are environment-specific and not part of the commercial solutions or support offered by New Relic. Please join us exclusively at the Explorers Hub (discuss.newrelic.com) for questions and support related to this blog post. This blog may contain links to content on third-party sites. By providing such links, New Relic does not adopt, guarantee, approve or endorse the information, views or products available on such sites.


